英偉達非唯一選擇:蘋果借助谷歌TPU成功訓練大型模型!
2024-07-31 11:15:26 EETOP蘋果透露,它在開發最近發布的 Apple Intelligence 功能時并未使用 Nvidia 的硬件加速器。根據蘋果官方的研究論文(machinelearning.apple.com/papers/apple_intelligence_foundation_language_models.pdf),蘋果使用的是谷歌的 TPU 來處理訓練數據,背后支持 Apple Intelligence 基礎語言模型。
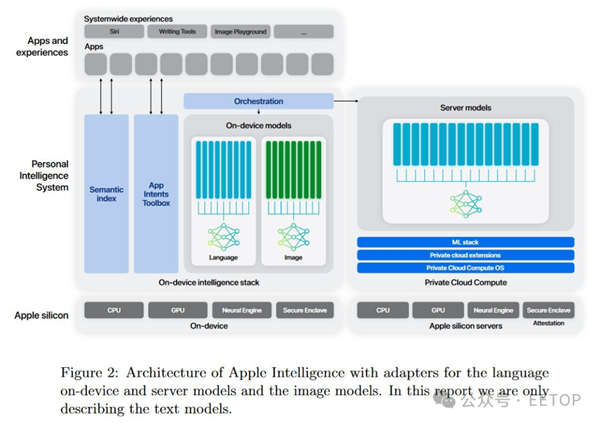
配備谷歌TPUv4和TPUv5芯片的系統在創建Apple Foundation Models(AFMs)過程中發揮了重要作用。這些模型,包括AFM-server和AFM-on-device模型,旨在為在線和離線Apple Intelligence功能提供支持,這些功能在 2024 年 6 月的全球開發者大會(WWDC)上得到了廣泛宣傳。
AFM-server 是蘋果最大的 LLM,因此它僅在線使用。根據最近發布的研究論文,蘋果的 AFM-server 在 8,192 個 TPUv4 芯片上訓練,“分配為 8 × 1,024 芯片切片,這些切片通過數據中心網絡(DCN)連接在一起。”預訓練是一個三階段過程,首先使用 6.3T 的 tokens,然后是 1T 的 tokens,最后通過 100B 的 tokens 進行上下文擴展。
蘋果表示,用于訓練其 AFMs 的數據包括從 Applebot 網絡爬蟲(遵循 robots.txt)收集的信息,以及各種經過授權的“高質量”數據集。它還利用了精心挑選的代碼、數學和公共數據集。
當然,ARM-on-device 模型大幅縮減,但蘋果認為其知識蒸餾技術已優化了這個較小模型的性能和效率。論文揭示,AFM-on-device 是一個 3B 參數模型,從 6.4B 的服務器模型中蒸餾而來,后者在完整的 6.3T tokens 上訓練。
與AFM-server的訓練不同,谷歌的TPUv5集群被用于準備ARM-on-device模型。論文透露,“AFM-on-device是在一個由2048個TPUv5p芯片組成的切片上進行訓練的。”
有趣的是,蘋果發布了如此詳細的論文,揭示了Apple Intelligence背后的技術和工藝。這家公司并不以透明度高而聞名,但似乎在努力給人留下深刻印象,以展示其在人工智能方面的實力,這或許是因為它在這個領域的起步相對較晚。
根據蘋果內部測試,AFM-server 和 AFM-on-device 在指令跟隨、工具使用、寫作等基準測試中表現出色。