深度解析最快AI芯片:性能怪獸、AI奇跡芯片!
2025-08-25 16:19:18 未知
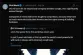
英偉達最快最先進的AI GPU: Blackwell Ultra GB300,號稱AI 領域的奇跡芯片,日前,英偉達發布了一篇深度解析文章,詳細介紹了其最新最強的 AI 芯片 ——GB300 Blackwell Ultra。這款芯片已全面投產,并已向核心客戶交付。作為 Blackwell 解決方案的延伸產品,GB300 在性能和功能上實現了重大升級。性能超 GB200 50% 并配備 288GB 內存。

如同英偉達 Super 系列是原版 RTX 游戲顯卡的增強版,Ultra 系列則是其 AI 芯片的進階版本。盡管此前的 Hopper 和 Volta 等產品線未明確推出 Ultra 型號,但從技術層面看也存在類似的增強版本。值得注意的是,Ultra 芯片雖在硬件層面更具優勢,但軟件更新與優化同樣能為非 Ultra 芯片帶來顯著性能提升。

那么,Blackwell Ultra GB300 究竟有何特別?如前所述,它采用兩顆整片晶圓尺寸的芯片(Reticle-sized Dies),通過英偉達 NV-HBI 高帶寬接口連接,在邏輯上呈現為單顆 GPU。該 GPU 基于臺積電 4NP 工藝(專為英偉達優化的 5nm 制程)打造,集成了 2080 億個晶體管。NV-HBI 接口為兩顆 GPU 芯片提供 10TB/s 的帶寬,同時確保其作為單一芯片協同工作。

英偉達 Blackwell Ultra GB300 GPU 集成了 160 個流式多處理器(SM),每個 SM 包含 128 個 CUDA 核心、4 個支持 FP8/FP6/NVFP4 精度計算的第五代張量核心、256KB 張量內存(TMEM)及特殊函數單元(SFU)。整體規格達到 20480 個 CUDA 核心、640 個張量核心及 40MB TMEM。
第五代張量核心是實現 AI 計算的核心引擎,英偉達在每代 GPU 的張量核心技術上均有重大創新:
·Volta 架構:8 線程矩陣乘法累加單元(MMA),支持 FP16 訓練并搭配 FP32 累加計算
·Ampere 架構:全 warp 范圍 MMA 單元,引入 BF16 和 TensorFloat-32 格式
·Hopper 架構:跨 128 線程的 warp 組 MMA 單元,集成支持 FP8 的 Transformer 引擎
·Blackwell 架構:第二代 Transformer 引擎,支持 FP8/FP6/NVFP4 計算及 TMEM 存儲
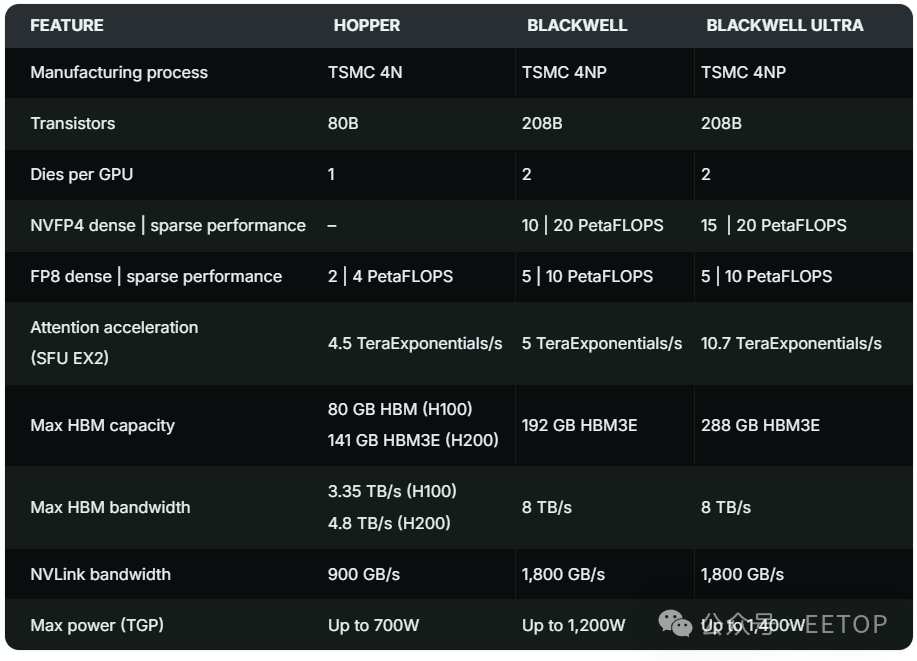
Blackwell Ultra 還實現了內存規格的重大升級:搭載 288GB HBM3e 顯存,較前代 Blackwell GB200 的最高 192GB 提升顯著。這一升級使其能夠支持萬億級參數規模的 AI 模型。內存采用 8 堆疊設計,配備 16 個 512 位控制器(總帶寬 8192 位),單 GPU 顯存帶寬達 8TB/s,具體優勢包括:
·完整模型駐留:無需內存卸載即可運行 3000 億 + 參數模型
·擴展上下文長度:為 Transformer 模型提供更大 KV 緩存容量
·提升計算效率:針對多樣化工作負載優化計算 - 內存比率
Blackwell 系列的互聯技術包括 NVLINK 交換機、NVLINK-C2C 連接,以及用于主機 GPU 連接的 PCIe Gen6 x16 接口。以下是 NVLINK 5 及主機端連接的關鍵特性:
·單 GPU 雙向帶寬:1.8TB/s(18 條鏈路 ×100GB/s)
·性能擴展:較 Hopper GPU 的 NVLink 4 提升 2 倍
·最大拓撲規模:支持 576 顆 GPU 構建無阻塞計算架構
·機架級集成:72 顆 GPU 的 NVL72 配置,總帶寬達 130TB/s
·PCIe 接口:Gen6×16 通道(雙向 256GB/s)
·NVLink-C2C:支持 Grace CPU-GPU 內存一致性通信(900GB/s)
RFhAiajxg/640?wx_fmt=png&from=appmsg&watermark=1" class="rich_pages wxw-img" data-ratio="0.23333333333333334" data-s="300,640" data-type="png" data-w="930" type="block" data-imgfileid="503570832" data-original-style="null" data-index="9" src="http://www.xebio.com.cn/uploadfile/2025/0825/20250825042019914.jpg" _width="677px" alt="圖片" data-report-img-idx="8" data-fail="0" style="-webkit-tap-highlight-color: transparent;padding: 0px;outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;vertical-align: bottom;height: auto !important;visibility: visible !important;width: 676.982px !important"/>
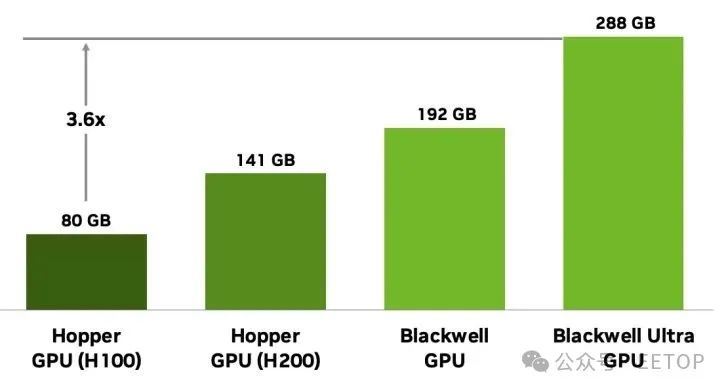
得益于全新 NVFP4 標準,英偉達 Blackwell Ultra GB300 平臺的密集低精度計算輸出提升 50%,同時保持接近 FP8 的精度水平(差異通常小于 1%)。與 FP8 相比,NVFP4 還能將內存占用減少 1.8 倍,較 FP16 減少 3.5 倍。
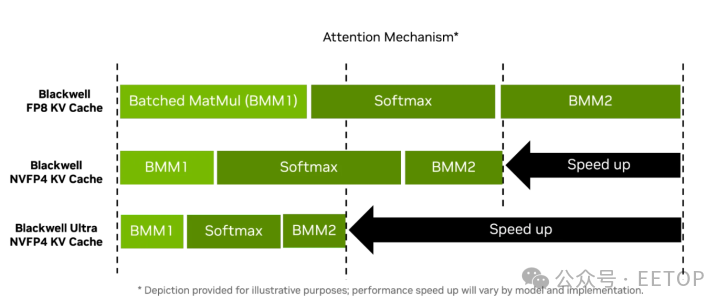
Blackwell Ultra 還搭載了先進的調度管理與企業級安全特性:
·增強型 GigaThread 引擎:新一代工作調度器,優化上下文切換性能并實現 160 個 SM 間的工作負載智能分配
·多實例 GPU(MIG):支持將 GPU 劃分為不同規格的 MIG 實例(如 2 個 140GB 實例、4 個 70GB 實例或 7 個 34GB 實例),實現安全多租戶環境下的性能隔離
·機密計算與安全 AI:為敏感 AI 模型和數據提供硬件級可信執行環境(TEE),首次在 Blackwell 架構中集成 TEE-I/O 功能,并通過 NVLink 在線加密實現接近未加密模式的吞吐量
·高級遠程證明服務(RAS)引擎:基于 AI 的可靠性監控系統,實時監測數千項參數以預測故障、優化維護計劃,最大化大規模部署的系統可用性
性能效率方面,Blackwell Ultra GB300 的每兆瓦吞吐量(TPS/MW)較 Blackwell GB200 進一步提升(具體數據見下圖)。

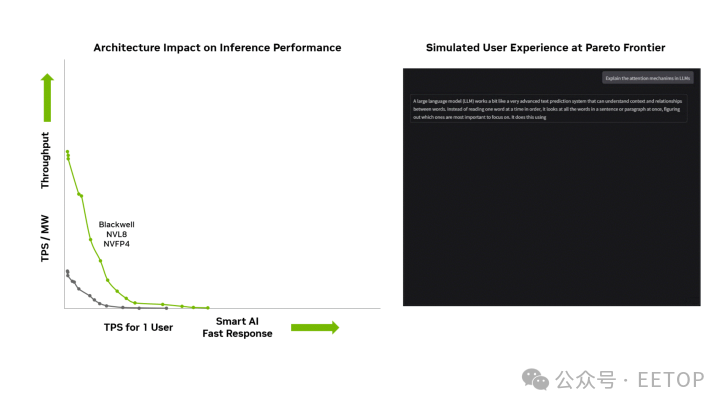
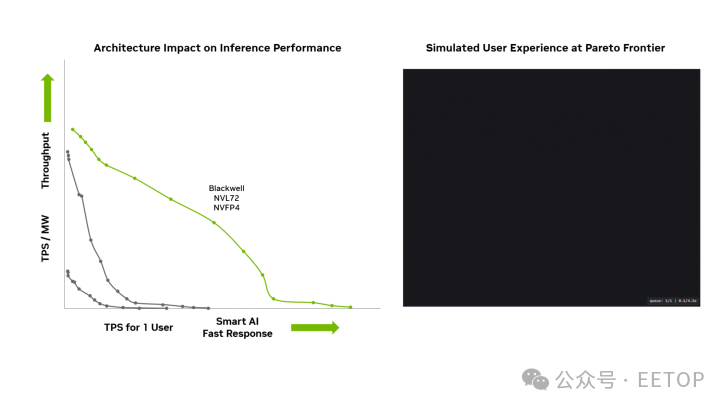
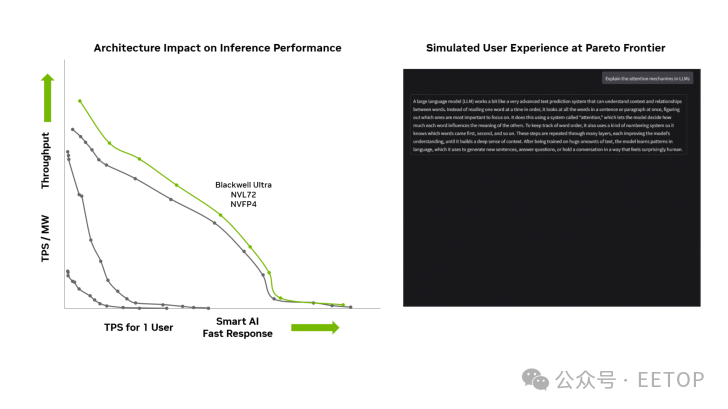
種種創新表明,英偉達憑借 Blackwell 及 Blackwell Ultra 等工程杰作穩居 AI 領域之巔。其深度軟件支持與持續優化是核心競爭力,而年度硬件迭代節奏與不斷加碼的研發投入,將確保其在未來數年內持續引領行業。