凜冬將至:從wave computing的倒下談AI加速器的未來
2020-04-23 12:29:40 MikesICroom EETOP
時間回到2016年,隨著alpha go在圍棋領域擊敗人類最優秀的棋手,加上Alexnet在圖像識別領域超越人類的準確率,標志著機器有可能在某些領域超越和代替人類。這類算法的特點是采用深層次的圖結構進行推斷,其中包含大量的參數和計算需求,從了催生了對芯片算力的極大挑戰。傳統的CPU根本無法提供這樣的計算能力,因此具有可編程性的GPU走向前臺成為了深度學習的主力。其中NVIDIA的GPU因為其提供了CUDA這樣的通用并行編程語言而具有很強的編程性和靈活性,稱為這個領域絕對的霸主。在深度學習算法向各個領域滲透和挖掘的過程中,工程師們注意到這種特殊的運算在GPU上并不能獲得很好的性能功耗比,主要原因是GPU提供了各個精度的高并行的科學運算,而深度學習通常只需要低精度的乘累加運算,這樣并不能充分利用GPU的運算能力。因而催生出設計針對深度學習特有運算的加速器,通過犧牲通用性來獲得該領域的專用加速。Google是最初嘗試的一批公司,第一代TPU突破性的只使用INT8進行推理,舍棄了傳統的浮點運算,這樣用更小的面積和功耗獲得了更大的算力。TPU 1.0的推出可以算是AI專用芯片領域的開拓者。
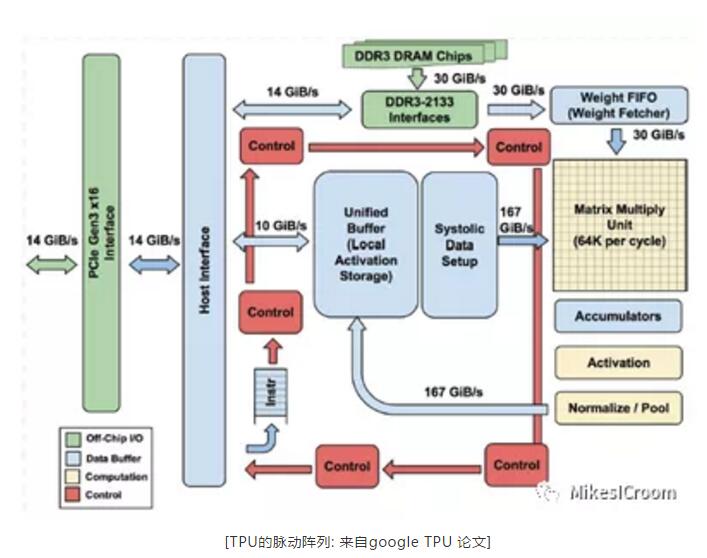
隨著AI熱潮的興起,芯片這個資本市場的冷門領域第一次獲得了如此高的關注,在非常短的時間里,大大小小的AI芯片公司雨后春筍般蓬勃發展起來,各種領域,各種規模,各種架構的都有公司涉獵。隨著AI算法在圖像和語音領域的高速發展,在這兩個方面有較大需求的互聯網和手機公司也紛紛加入戰局,比如蘋果和華為都很快推出了各自手機的神經網絡加速器,用來提高攝像和面容識別的速度和準確度。互聯網巨頭們也不甘落后,Google,百度,阿里都在很短時間里組建了自己的硬件設計團隊并推出了各自的加速器和編程框架。在各家的宣傳中,對GPU的性能可以說都是數十倍的提升。其中wave computing的DPU架構算是其中的佼佼者,全異步電路,數據流執行,非馮架構的眾核可重構結構,哪一項放出來都是芯片設計中的尖端方向。從他給出的測試數據來看,等效6.7GHz的頻率,連intel都要望其項背。即使wave AI芯片不成功,這些技術的研究總也是很有前景的,而這樣的公司也要走向破產申請之路,不免讓人有些疑惑,到底是技術錯了,還是市場錯了?
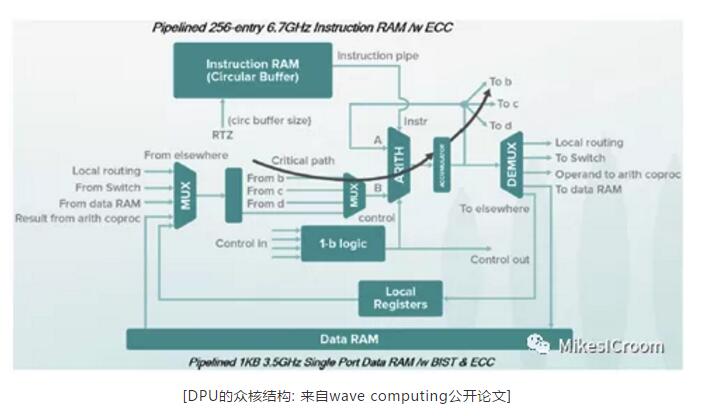
這里我并不想質疑wave所宣揚的技術創新是否可行,而希望從最近AI芯片不利的消息中,談談對AI芯片未來發展的個人看法。隨著全球經濟不可避免的下滑和資本市場的冷卻,wave的倒下可能只是個開始,也就是說之后就是潮水褪去的裸泳時代了。從AI芯片拋物線式的發展歷程來看,目前高端AI市場最大的贏家,也很有可能是未來很久的贏家,就是NVIDIA。其他面向這個領域的玩家,包括wave在內,并沒有對NV造成實質性的威脅,其中的關鍵是無法挑戰龐大的CUDA生態,沒有良好的編程性和通用性,再高的性能也很難在實際的應用中發揮效果。在中端領域,這個市場被幾大手機廠商所瓜分,包括蘋果,華為,三星,高通,ARM。由于圖像是AI領域最成熟的方向,并且可以很明顯的提升手機攝像和識別的效果,因此各廠商都有動力開發這樣的專用加速器,并且是各自開發來保證差異性和控制力。至于低端領域,不客氣的說,AI芯片沒有低端領域,一個ARM CPU加上DSP和NEON擴展足以應付絕大多數的應用。從各場景上來看,AI芯片的創業其實是夾縫中生存,高端沒有強大生態,中端各廠家只想自己玩,低端沒有應用場景。因而大多數的AI芯片創業公司,除了開幾場發布會,發布一些耀眼數據,跑跑benchmark,并沒有辦法找到合適的應用場景,因此只能靠融資一輪一輪的支持,不能創造經濟價值。而目前的經濟形勢有可能是壓倒駱駝的最后一根稻草,這也可能是wave面臨的現狀。


芯片從本質上來說和其他的商品并沒有不同。要能賣出去創造價值,關鍵是要有合適的場景,并且要有“非我莫屬”的殺手級應用出現,促使整個行業向包含AI芯片的方向發展。從目前來看,這樣的殺手級應用似乎還沒出現。AI行業的發展,不是靠各個會議中所提出的五花八門的模型,以及像換臉作曲打游戲這樣的娛樂級應用,而是需要一個像手機中的“iphone”,汽車中的“特斯拉”這樣的產品出現,向大家宣布,這就是未來,將從根本上改變人們之后的生活。而這個未來中,AI芯片是必不可少的重要一環。這也許需要時機,也需要一個像喬布斯,馬斯克這樣的開拓者。

從技術上來說,wave computing所面臨的的問題也許標志著第一波AI創業者們方向性的錯誤。過份的追求性能,功耗,犧牲了通用性和編程性,造成在實際應用上的編程困難和不可移植。從整個算法領域來看,AI目前所在的深度學習也許算是一個專用領域,但從AI自身的算法看,它仍然是通用的,是需要有適應算法和模型變化的能力的,不管是圖像,語音,仿生,都不會是一個一成不變的算法,而是會一直演進下去。哪怕是成熟的算法,對于不同的應用,仍然會有各種各樣的區別,這樣都需要AI芯片能夠快速且高性能的適配。除非一個領域的算法發展為幾乎固定,比如視頻的H.264,加密的AES,這樣ASIC的固定算法就具有絕對優勢,可以不考慮編程性,否則可編程和可移植一定是最重要的因素,甚至是第一要素,而顯然AI不會是個固定的算法。因此,如何在目前的各種AI加速的硬件架構上,提供足夠好的編程性,會是之后AI芯片設計的重點。從這個角度來看,目前走在這條道路上的公司寥寥無幾。其中除了目前成功的GPGPU結構外,類VLIW的加速器也是可能的方向之一,如Habaha的Goya和Gaudi,華為的DaVinci,燧原的DTU。至于能否占據先機,更關鍵的是完善的生態,這也是最難的一步。然而隨著Habana的被收購,不免讓人疑慮重重,這些小的AI創業公司們能否有機會成長為參天大樹,還是只能在資本和市場的困境中無奈的選擇被巨頭并購?還是很希望有創業公司能夠成長壯大,像Google對于搜索,像阿里對于互聯網商務,像NVIDIA對于圖形和AI。芯片這個資本和技術并重的行業,需要這樣的攪局者和開拓者來打破僵局,推動它向更高更強的方向發展。
更多干貨,歡迎關注公眾號:MikesICroom 回復“課程”獲取斯坦福大學AI加速器課程資料























