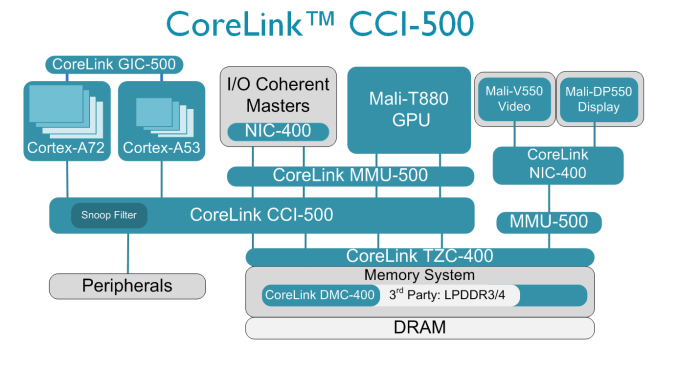
ARM-GPU將在高性能計(jì)算中脫穎而出
2020-01-30 09:51:52 EETOPGPU已經(jīng)成為加速高性能計(jì)算工作負(fù)載的標(biāo)準(zhǔn)平臺(tái),至少對(duì)于那些已經(jīng)對(duì)其代碼進(jìn)行了調(diào)整以完全支持加速的工作而言。但是直到最近,大部分加速還是發(fā)生在使用Intel Xeon或IBM Power處理器的主機(jī)系統(tǒng)上。但是隨著Nvidia兌現(xiàn)了支持Arm作為X86和Power的對(duì)等產(chǎn)品的承諾,由Arm-GPU組合提供支持的HPC的前景已大大增加。
從Nvidia的角度來(lái)看,考慮到Arm將在未來(lái)的HPC部署中取代X86,特別是在歐盟和英國(guó),這當(dāng)然很有意義。在美國(guó)和其它地方,Arm被視為向高性能計(jì)算生態(tài)系統(tǒng)注入更多多樣性和競(jìng)爭(zhēng)的一種方式。此外,Arm在超大規(guī)模、云計(jì)算和企業(yè)設(shè)置方面還具有更廣泛的地理可能性。
三大知名超級(jí)計(jì)算中心正在幫助Nvidia將這種Arm-GPU計(jì)算模型實(shí)現(xiàn)為HPC:日本的RIKEN,英國(guó)的布里斯托大學(xué)和美國(guó)的橡樹嶺國(guó)家實(shí)驗(yàn)室。
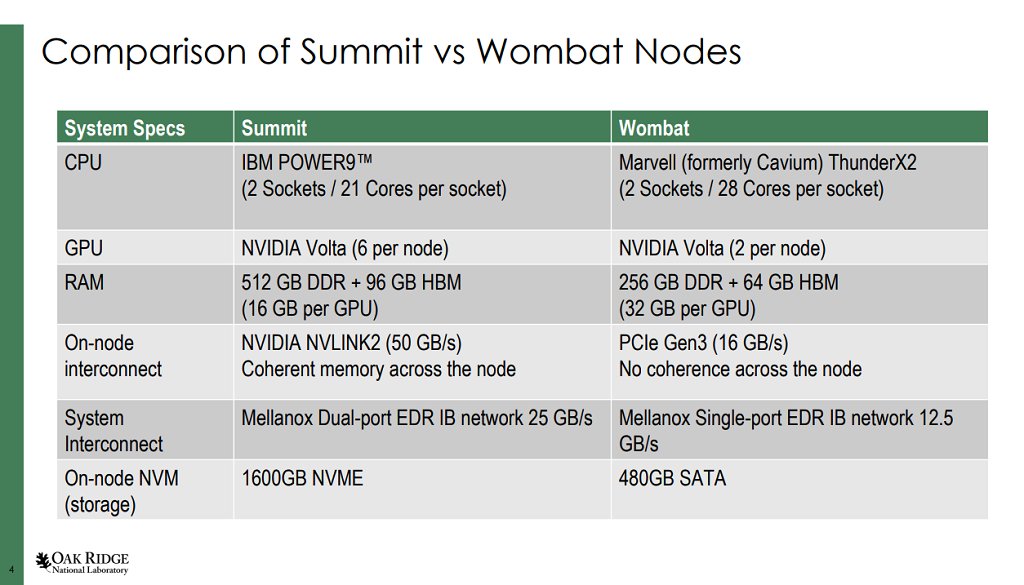
以橡樹嶺為例,實(shí)驗(yàn)室已通過(guò)為基于ThunderX2的Wombat測(cè)試平臺(tái)群集配備NvidiaV100 GPU并使用該設(shè)置移植和基準(zhǔn)化一系列加速的HPC代碼來(lái)著手這項(xiàng)工作。Wombat由16個(gè)預(yù)制的HPE Apollo70節(jié)點(diǎn)組成,每個(gè)節(jié)點(diǎn)都配備了一對(duì)28核的ThunderX2CPU,256 GB RAM和100 Gb / sec EDRInfiniBand網(wǎng)絡(luò)接口。其中四個(gè)節(jié)點(diǎn)已配備Nvidia V100 GPU,每個(gè)節(jié)點(diǎn)兩個(gè),每個(gè)GPU都掛接到32 GB的HBM2內(nèi)存中。與橡樹嶺的“ Summit”超級(jí)計(jì)算機(jī)上設(shè)置的V100 GPU相比,Wombat的HBM2內(nèi)存是其兩倍,但接口要慢得多,因?yàn)檫@些GPU使用PCI-Express 3.0鏈接而不是Nvidia專門構(gòu)建的NVLink2互連。
在軟件方面,為Wombat用戶提供了Arm增強(qiáng)的CUDA 10.1(預(yù)發(fā)行版)以及一系列Arm支持的編譯器,包括gcc v8.2,gcc v9.2,用于HPC v19的Arm編譯器。 3,以及具有CUDAFortran支持的PGI開發(fā)人員版本。支持庫(kù)由OpenMPIv3.1和v4.0,以及UCX 1.7.0以及ArmPerformance Libraries提供的優(yōu)化的BLAS,LAPACK,F(xiàn)FT等數(shù)學(xué)例程組成。
在測(cè)試的應(yīng)用程序中有用于比較基因組學(xué)的組合度量(CoMet)代碼、格羅寧根化學(xué)模擬機(jī)(GROMACS)、用于分子動(dòng)力學(xué)模擬、量子多體系統(tǒng)的動(dòng)態(tài)簇近似++(DCA ++)代碼、大規(guī)模原子/分子大規(guī)模并行模擬器(LAMMPS)代碼以及材料科學(xué)的局部自洽多重散射(LSMS)代碼等。
橡樹嶺科學(xué)計(jì)算小組的計(jì)算科學(xué)家Wayne Joubert表示,移植是非常簡(jiǎn)單的,主要是需要更改應(yīng)用程序構(gòu)建腳本。例如,CoMet主要方法的移植,測(cè)試和基準(zhǔn)測(cè)試不到兩天。其他代碼只需幾個(gè)小時(shí)即可移植。
Joubert告訴我們:“這種體驗(yàn)非常類似于將代碼從X86轉(zhuǎn)移到Power架構(gòu)。事實(shí)上,移植過(guò)程中最大的挑戰(zhàn)是確保所有需要的系統(tǒng)軟件都安裝在系統(tǒng)上。”
ORNL技術(shù)集成小組的HPC系統(tǒng)程序員RossMiller表示,移植代碼的不同團(tuán)隊(duì)在SC19移植代碼之前僅幾周,因此在大多數(shù)情況下,他們只有時(shí)間來(lái)啟動(dòng)應(yīng)用程序并進(jìn)行移植。在Wombat上運(yùn)行,而不是花費(fèi)更多的勞動(dòng)強(qiáng)度來(lái)優(yōu)化其性能。例如,盡管GPU的HBM2容量是Summit上的GPU的兩倍,但開發(fā)人員沒有機(jī)會(huì)為額外的內(nèi)存調(diào)整問(wèn)題大小。
“至少在一種情況下(VMD),開發(fā)人員已經(jīng)為X86代碼編寫了手動(dòng)調(diào)整的SSE,AVX和AVX-512例程,” Miller指出。“ Arm端口必須完全依賴編譯器生成的代碼,而效率卻不那么高。如果開發(fā)人員花時(shí)間為NEON指令集編寫類似的優(yōu)化例程,那么性能將更加接近。”
通常,GPU性能差不多是Summit的20%,差異歸因于功能較弱的主機(jī)處理器(ThunderX2與Power9)以及缺乏優(yōu)化。一些應(yīng)用受到較低PCIe帶寬的影響,而對(duì)于另一些應(yīng)用,差異并不明顯。考慮到所有這些因素,再加上Wombat使用的是預(yù)制硬件,在某些情況下還使用了預(yù)制軟件,現(xiàn)在就對(duì)這種Arm-GPU產(chǎn)品的相對(duì)性能做出確切的決定還為時(shí)過(guò)早。
同樣,評(píng)估此特定系統(tǒng)的能源效率也為時(shí)過(guò)早。他們打算在將來(lái)考慮這一點(diǎn)。
每個(gè)參與者Arm、Nvidia和HPC用戶社區(qū)都在打持久戰(zhàn),沒有人指望Arm能夠像1990年代初X86接管HPC并成為未來(lái)三十年的主導(dǎo)架構(gòu)那樣,席卷整個(gè)HPC市場(chǎng)。但是Arm可以一點(diǎn)一點(diǎn)地在競(jìng)爭(zhēng)中脫穎而出。 (EETOP翻譯自nextplatform)

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章