詳細評測:英特爾 Cascade Lake vs 英偉達圖靈,AI處理誰更強?
2019-07-31 11:19:01 EETOP今天我們來看看英特爾的第二代Xeon可擴展處理器,即“Cascade Lake”,它可能是英特爾在AI領(lǐng)域硬件的核心。今年早些時候推出的這些新處理器仍然基于與第一代產(chǎn)品相同的核心Skylake架構(gòu),但采用了許多新指令來加速AI性能。
就新技術(shù)而言,這肯定是Cascade Lake最有趣的方面。雖然我們可以談?wù)撘话?a href="http://www.xebio.com.cn/cpu_soc" target="_blank" class="keylink">CPU性能提升3%到6%,英特爾最昂貴處理器的56核,以及“世界紀錄基準(zhǔn)”, 但這些小的改進對于IT世界近期和中期的未來幾乎是無關(guān)緊要的。看看英特爾新聞與分析師簡報的第一張PPT就知道了。
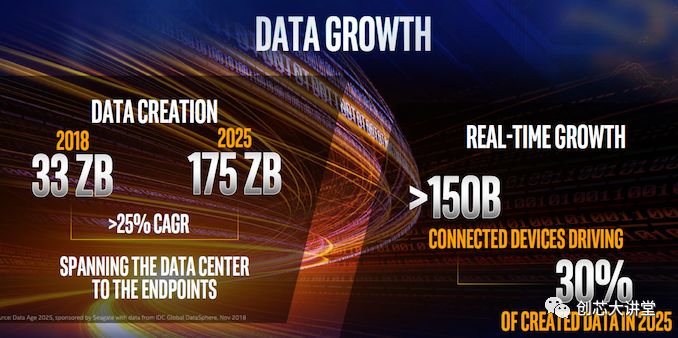
物聯(lián)網(wǎng)、數(shù)據(jù)工程和人工智能。這將是增長、創(chuàng)新和未來的主要領(lǐng)域。這就是英特爾的目標(biāo)。
目前,英偉達在這個市場上領(lǐng)域——深度學(xué)習(xí)和“大規(guī)模并行高性能計算”軟件——幾乎處于壟斷地位。由于硬件和軟件方面的一系列因素,大多數(shù)軟件都運行在英偉達GPU和集群上。因此,對于普通大眾來說,英偉達似乎擁有“人工智能市場”,這一圖景并不準(zhǔn)確,但也不完整。人工智能市場不僅僅是神經(jīng)網(wǎng)絡(luò)推理,特別是,所有為人工智能模型提供數(shù)據(jù)的事情都很少受到關(guān)注。因此,神經(jīng)網(wǎng)絡(luò)和他的終結(jié)者機器人占據(jù)了所有的頭條,盡管它們只是圖片的一部分。實際上,AI應(yīng)用程序的處理網(wǎng)絡(luò)更類似于下圖。
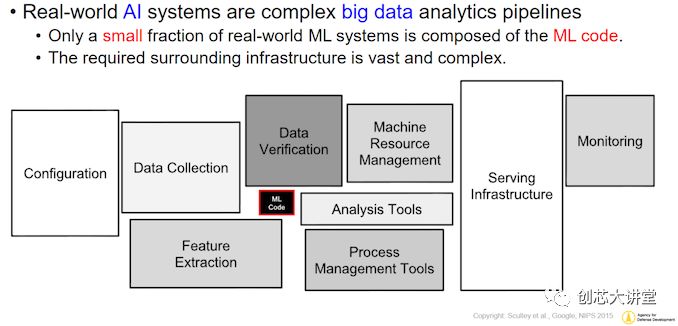
簡而言之,實際的機器學(xué)習(xí)代碼執(zhí)行只是構(gòu)建和AI應(yīng)用程序所需的軟件工具的一小部分。為什么?讓我們深入研究一下。
在高層次上,雖然深度學(xué)習(xí)是人工智能的一種形式,但反過來并不總是正確的,實現(xiàn)AI的應(yīng)用程序不一定要使用深度學(xué)習(xí)。許多人工智能應(yīng)用程序使用“傳統(tǒng)統(tǒng)計”或“傳統(tǒng)”機器學(xué)習(xí)。畢竟,支持向量機、邏輯回歸、K-nearest、Naive Bayes和決策樹在自動進行信息分類時仍然非常有用,尤其是在沒有大量數(shù)據(jù)的情況下。
例如,在自然語言處理中使用條件隨機域(CRF),許多推薦引擎都是基于玻爾茲曼機、交替最小二乘(ALS)等。舉個例子:我們的“大數(shù)據(jù)”基準(zhǔn)測試是最苛刻、最獨特的基準(zhǔn)測試之一,它使用ALS算法作為推薦引擎(“協(xié)同過濾”)。
當(dāng)然,神經(jīng)網(wǎng)絡(luò)的應(yīng)用——它本身就是一個完整的研究領(lǐng)域——正在蓬勃發(fā)展,它們的應(yīng)用往往主導(dǎo)著最新的人工智能應(yīng)用。神經(jīng)網(wǎng)絡(luò)也是要求最高的工作負載之一,需要大量的處理能力。所有這些都與邏輯回歸(logistic regression)形成了鮮明對比,后者仍然是最常用的機器學(xué)習(xí)方法,而且恰好需要更少的處理。
盡管如此,盡管神經(jīng)網(wǎng)絡(luò)是人工智能技術(shù)中處理最密集的技術(shù)(尤其是具有大量層的技術(shù)),但有幾種傳統(tǒng)的機器學(xué)習(xí)技術(shù)也需要大量的處理能力。例如,支持向量機及其復(fù)雜的轉(zhuǎn)換也往往需要大量的計算時間。在我們的Spark測試中,斯坦福大學(xué)的NER系統(tǒng)是基于一個有監(jiān)督的CRF模型,使用標(biāo)記的英語數(shù)據(jù)集合。在測試中,它必須處理大量的高達幾百GB的非結(jié)構(gòu)化文本數(shù)據(jù)。
反過來,處理能力要求的這些差異的原因?qū)嶋H上非常簡單。引用AI專家Wouter Gevaert的表述:
"神經(jīng)網(wǎng)絡(luò)中的每個神經(jīng)元都可以被視為邏輯回歸單元。因此,神經(jīng)網(wǎng)絡(luò)就像大量的邏輯回歸" (當(dāng)你使用sigmoid作為激活函數(shù)時)
然而,盡管神經(jīng)網(wǎng)絡(luò)是人工智能技術(shù)中最需要處理的技術(shù)(尤其是具有大量層次的人工智能技術(shù)),有幾種傳統(tǒng)的機器學(xué)習(xí)技術(shù)也需要大量的處理能力。例如,支持向量機及其復(fù)雜的轉(zhuǎn)換也往往需要大量的計算時間。在我們的Spark測試中,斯坦福大學(xué)的NER系統(tǒng)是基于一個有監(jiān)督的CRF模型,使用標(biāo)記的英語數(shù)據(jù)集合。在測試中,它必須處理幾百GB的大量的非結(jié)構(gòu)化文本。

當(dāng)然,大多數(shù)分析查詢?nèi)匀皇褂门f的SQL編寫。對于結(jié)構(gòu)化和半結(jié)構(gòu)化數(shù)據(jù),對于OLAP多維數(shù)據(jù)集等,SQL代碼仍然很普遍。由于單個SQL查詢遠不及神經(jīng)網(wǎng)絡(luò)那么平行 - 在許多情況下它們是100%順序的 - CPU是這項工作的最佳工具。
因此,在實踐中,大多數(shù)數(shù)據(jù)(預(yù)處理)和許多人工智能軟件仍然運行在CPU上。GPU主要運行大規(guī)模并行的HPC應(yīng)用程序和神經(jīng)網(wǎng)絡(luò),這無疑是一個重要的市場,但仍然只是更大的人工智能市場的一部分。這也是為什么英偉達去年的數(shù)據(jù)中心收入為30億美元,而英特爾的數(shù)據(jù)中心收入為200億美元。
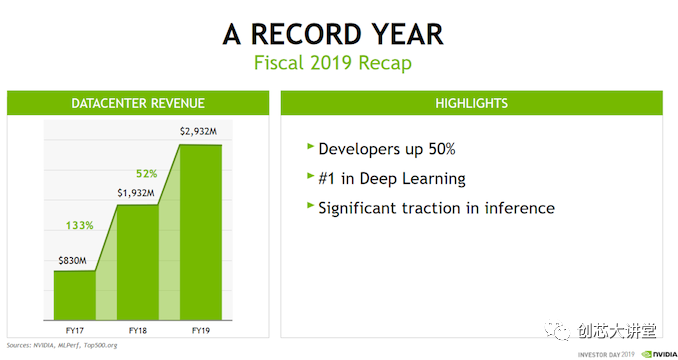
然而,使整個情況更加復(fù)雜的不僅僅是只看收入,還要看增長。在數(shù)據(jù)中心市場,英偉達一直在大幅增長,而英特爾只實現(xiàn)了個位數(shù)的增長。隨著新技術(shù)的出現(xiàn),客戶的需求也在不斷變化;對數(shù)據(jù)分析市場的爭奪已經(jīng)開始,而且正在加劇。
卷積,循環(huán)和可擴展性:尋求平衡
盡管英特爾Xeon Phi協(xié)處理器(Xeon Phi協(xié)處理器)作為加速器在市場上失敗了,而且已經(jīng)停產(chǎn),但英特爾并沒有放棄這個概念。該公司仍希望在人工智能市場占據(jù)更大的份額,包括原本可能進入英偉達的份額。
Naveen提出了一個重點。因為雖然英偉達從未聲稱他們?yōu)樗蓄愋偷?a href="http://www.xebio.com.cn/ai" target="_blank" class="keylink">AI提供最好的硬件,但從表面上看整個行業(yè)新聞稿中引用最多的基準(zhǔn)(ResNet,Inception等),你幾乎可以相信只有一種類型的AI事項。卷積神經(jīng)網(wǎng)絡(luò)(CNN或ConvNets)在基準(zhǔn)測試和產(chǎn)品演示中占據(jù)主導(dǎo)地位,因為它們是分析圖像和視頻的最流行的技術(shù)。任何可以表示為“2D輸入”的東西都是這些流行神經(jīng)網(wǎng)絡(luò)的輸入層的潛在候選者。
近年來,CNN取得了一些最引人注目的突破。例如,ResNet性能如此受歡迎并不是錯誤的。相關(guān)的ImageNet數(shù)據(jù)庫是斯坦福大學(xué)和普林斯頓大學(xué)之間的合作,包含了1400萬張圖像。直到最近十年,AI在識別這些圖像方面的表現(xiàn)非常差。美國有線電視新聞網(wǎng)(CNN)以快速的順序改變了這一點,從那以后它一直是最受歡迎的人工智能挑戰(zhàn)之一,因為公司希望能夠比以往更快,更準(zhǔn)確地對這個數(shù)據(jù)庫進行分類。
早在2012年,AlexNet,一個相對簡單的神經(jīng)網(wǎng)絡(luò),在ImageNet分類競賽中取得了比傳統(tǒng)機器學(xué)習(xí)技術(shù)更好的準(zhǔn)確率。在那次測試中,它達到了85%的準(zhǔn)確率,幾乎是傳統(tǒng)方法73%準(zhǔn)確率的一半。
在2015年,著名的Inception V3在對圖片進行分類時達到了3.58%的錯誤率,這與人類相似(甚至略好于人類)。ImageNet的挑戰(zhàn)變得更加困難,但是由于剩余的學(xué)習(xí),即使不增加層數(shù),CNN也變得更好。這導(dǎo)致了著名的“ResNet”CNN,現(xiàn)在最流行的人工智能基準(zhǔn)之一。長話短說,CNNs是人工智能領(lǐng)域的明星。到目前為止,他們得到了最多的關(guān)注、測試和研究。
CNN也具有很高的可擴展性:在降低網(wǎng)絡(luò)培訓(xùn)時間時,增加更多GPU(幾乎)線性擴展。
坦率地說,CNN是上天送給英偉達的禮物。這是人們購買昂貴的英偉達 DGX服務(wù)器(40萬美元)或購買多臺特斯拉GPU (7k+美元)最常見的原因。
盡管如此,人工智能還有比CNN更多的東西。例如,遞歸神經(jīng)網(wǎng)絡(luò)在語音識別、語言翻譯和時間序列方面也很受歡迎。
這就是MLperf基準(zhǔn)計劃如此重要的原因。這是我們第一次獲得CNN未完全統(tǒng)治的基準(zhǔn)。
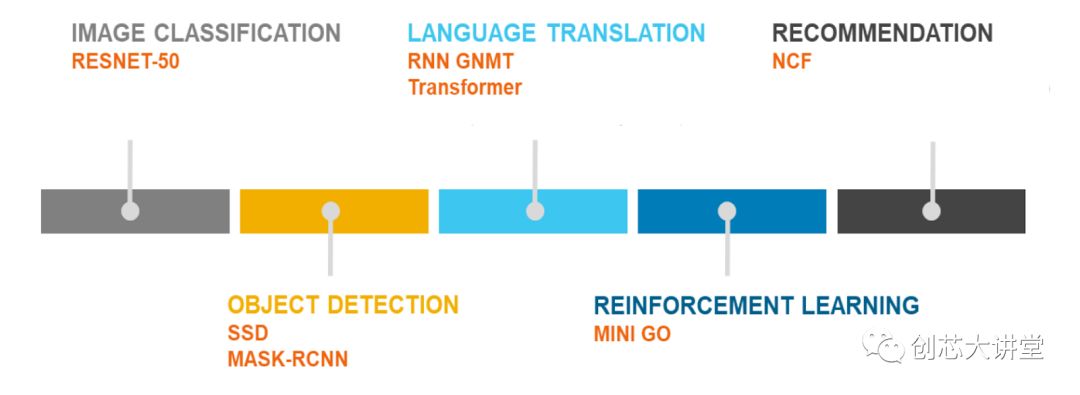
快速瀏覽一下MLperf,圖像和對象分類基準(zhǔn)當(dāng)然是CNN,但也表示了RNN(通過神經(jīng)機器翻譯)和協(xié)同過濾。同時,甚至推薦引擎測試也基于神經(jīng)網(wǎng)絡(luò); 從技術(shù)上講,不包括“傳統(tǒng)的”機器學(xué)習(xí)測試,這是不幸的。但由于這是0.5版本并且該組織正在邀請更多反饋,它肯定是有希望的,一旦它成熟,我們預(yù)計它將成為最好的基準(zhǔn)。
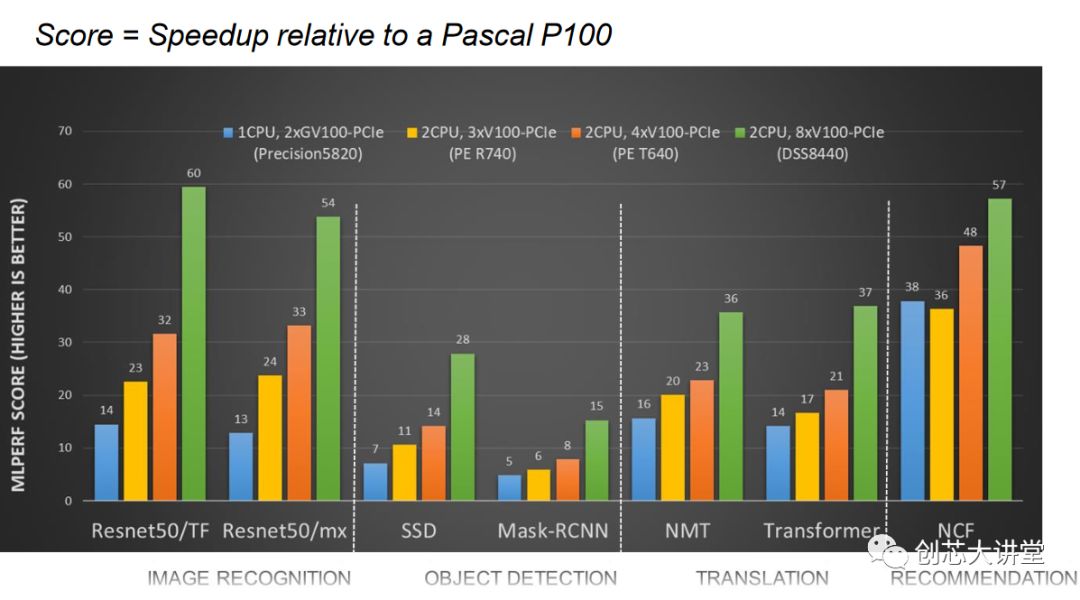
然而,通過戴爾的基準(zhǔn)測試,我們可以清楚地看到,并非所有的神經(jīng)網(wǎng)絡(luò)都具有CNN那樣的可擴展性。當(dāng)您移動到GPU數(shù)量的四倍(并添加第二個CPU)時,ResNet CNN很容易翻兩番,而協(xié)作過濾方法只提供了50%的更高性能。
事實上,相當(dāng)多的學(xué)術(shù)研究都圍繞著優(yōu)化和適應(yīng)CNNs展開,這樣它們就可以像處理RNNs一樣處理這些序列建模工作負載,從而可以替代伸縮性較差的RNNs。
總的來說,英特爾有一個很好的觀點,即存在“廣泛的AI應(yīng)用”,例如CNN之外的AI生活。在許多現(xiàn)實場景中,傳統(tǒng)的機器學(xué)習(xí)技術(shù)優(yōu)于CNN,并非所有深度學(xué)習(xí)都是通過超可擴展的CNN完成的。在其他實際案例中,擁有大量RAM是另一個重要的性能優(yōu)勢,無論是在訓(xùn)練模型還是使用它來推斷新數(shù)據(jù)時。
因此,盡管英偉達在運行CNN方面具有巨大優(yōu)勢,但高端Xeon 可以在數(shù)據(jù)分析市場中提供可靠的替代方案。可以肯定的是,沒有人希望新的Cascade Lake Xeon在CNN訓(xùn)練中勝過英偉達 GPU,但在很多情況下,英特爾可能會說服客戶投資更強大的Xeon而不是昂貴的Tesla加速器:
因此,英特爾或許有機會將英偉達擋在門外,直到他們在CNN工作負載中為英偉達的GPU找到一個合理的替代方案。英特爾一直在為Xeons可伸縮系列產(chǎn)品瘋狂地添加功能,并優(yōu)化其軟件堆棧,以對抗英偉達的人工智能霸主地位。優(yōu)化的人工智能軟件,如英特爾自己的Python發(fā)行版,英特爾數(shù)學(xué)內(nèi)核庫用于深度學(xué)習(xí),甚至英特爾數(shù)據(jù)分析加速庫——主要用于傳統(tǒng)的機器學(xué)習(xí)……

總而言之,對于第二代英特爾至強可擴展處理器,該公司在深度學(xué)習(xí)(DL)Boost名稱下添加了新的AI硬件功能。這主要包括矢量神經(jīng)網(wǎng)絡(luò)指令(VNNI)集,它可以在一個指令中執(zhí)行之前需要三個指令。然而,即便更進一步,第三代Xeon可擴展處理器Cooper Lake將增加對bfloat16的支持,進一步提高培訓(xùn)性能。
總之,英特爾試圖重新占領(lǐng)“更輕的AI工作負載”市場,同時在數(shù)據(jù)分析市場的其他部分站穩(wěn)腳跟,同時在其產(chǎn)品組合中添加非常專業(yè)的硬件(FPGA,ASIC)。這對英特爾在IT市場的競爭力至關(guān)重要。英特爾一再表示,數(shù)據(jù)中心集團(DCG)或“企業(yè)部分”預(yù)計將成為該公司未來幾年的主要增長引擎。
英偉達的答案
英偉達不止一次證明,它可以憑借出色的愿景和戰(zhàn)略戰(zhàn)勝競爭對手。英偉達明白將所有神經(jīng)網(wǎng)絡(luò)擴展為CNN并不容易,并且有很多應(yīng)用要么運行在除神經(jīng)網(wǎng)絡(luò)之外的其他方法上,要么是內(nèi)存密集型而不是計算密集型。
在GTC Europe,英偉達推出了一個新的數(shù)據(jù)科學(xué)平臺,供企業(yè)使用,該平臺建立在英偉達新的“RAPIDS”框架之上。基本思想是數(shù)據(jù)管道的GPU加速不應(yīng)局限于深度學(xué)習(xí)。
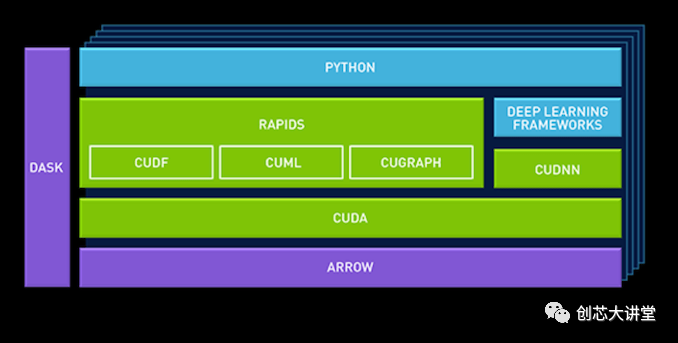
例如,CuDF允許數(shù)據(jù)科學(xué)家將數(shù)據(jù)加載到GPU內(nèi)存中并對其進行批處理,類似于Pandas(用于操作數(shù)據(jù)的python庫)。cuML是目前有限的GPU加速機器學(xué)習(xí)庫集合。最終,Scikit-Learn工具包中提供的大多數(shù)(全部?)機器學(xué)習(xí)算法應(yīng)該是GPU加速的,并且可以在cuML中使用。
英偉達還添加了一個柱狀內(nèi)存數(shù)據(jù)庫Apache Arrow。這是因為GPU在向量上運行,因此有利于內(nèi)存中的柱狀布局。
通過利用Apache arrow作為“中央數(shù)據(jù)庫”,英偉達避免了大量開銷。
確保存在典型Python庫(如Sci-Kit和Pandas)的GPU加速版本是朝著正確方向邁出的一步。但是Pandas僅適用于較輕的“數(shù)據(jù)科學(xué)探索”任務(wù)。通過與Databricks合作確保RAPIDS也用于重型,分布式“數(shù)據(jù)處理”框架Spark,英偉達正在邁出下一步,突破“深度學(xué)習(xí)”角色,并向“NVIDIA”展開其余部分數(shù)據(jù)管道。

然而,細節(jié)決定成敗。將GPU添加到經(jīng)過多年優(yōu)化的框架中,以便最優(yōu)地使用CPU內(nèi)核和服務(wù)器中可用的大量RAM,這并不容易。Spark被構(gòu)建為運行在幾十個強大的服務(wù)器內(nèi)核上,而不是運行在數(shù)千個微不足道的GPU內(nèi)核上。Spark已經(jīng)過優(yōu)化,可以在服務(wù)器節(jié)點集群上運行,使其看起來像是RAM內(nèi)存和核心的一個大塊。混合兩種內(nèi)存(RAM和GPU VRAM)并保持Spark的分布式計算特性并不容易。
其次,挑選最適合GPU的機器學(xué)習(xí)算法是一回事,但確保它們在基于gpu的機器上運行良好是另一回事。最后,在可預(yù)見的將來,GPU的內(nèi)存仍然少于CPU,即使是一致的平臺也不能解決系統(tǒng)RAM的速度只是局部VRAM速度的一小部分的問題。
誰將贏得下一個企業(yè)市場?
在最后一個投資者日,英偉達的一張PPT清楚地表明了企業(yè)領(lǐng)域的下一場戰(zhàn)斗將是什么:數(shù)據(jù)分析。請注意昂貴的雙Xeon“Skylake”Scalable如何被視為基線。這是一個相當(dāng)?shù)穆暶? 將最新的英特爾動力系統(tǒng)之一降低到一個完全優(yōu)秀的簡單基線。
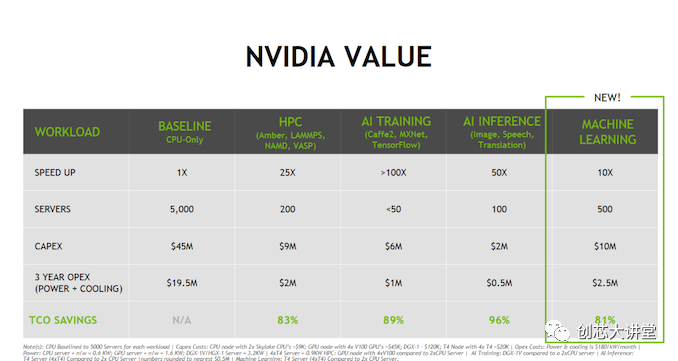
英偉達的整個商業(yè)模式圍繞著這樣一個理論:購買昂貴的硬件,如DGXs和特斯拉,對你的TCO有好處(“買得越多,省得越多”)。不要購買5000臺服務(wù)器,而是購買50臺DGX。盡管DGX消耗的功率增加了5倍,而且耗資12萬美元而不是9,000美元,但你的狀況會好得多。當(dāng)然,這是最好的營銷方式,也可能是最差的營銷方式,這取決于你如何看待它。但即使這些數(shù)字略有夸大,這也是一個強有力的信息:“從我們的深度學(xué)習(xí)的大本營到英特爾當(dāng)前的增長市場(推論、高性能計算和機器學(xué)習(xí)),我們將以巨大優(yōu)勢擊敗英特爾。”
不相信嗎?這就是英偉達和IDC對市場演變的看法。
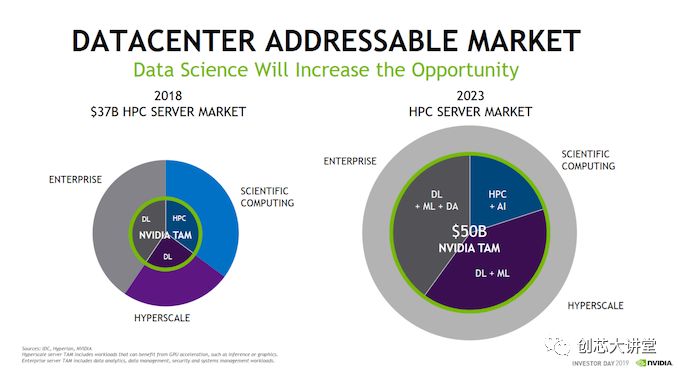
目前,在總計1000億美元的市場中,計算密集型或高性能子市場約為370億美元。英偉達認為,這個子市場將在2023年翻一番,他們將能夠解決500億美元的問題。換句話說,從廣義上講,數(shù)據(jù)分析市場將幾乎占整個服務(wù)器市場的一半。
即使這是一種高估,但很明顯,時代在變,而且風(fēng)險非常高。神經(jīng)網(wǎng)絡(luò)更適合GPU,但如果英特爾可以確保大多數(shù)數(shù)據(jù)管道在CPU上運行得更好,并且您只需要GPU用于最密集和可擴展的神經(jīng)網(wǎng)絡(luò),那么它將使英偉達重新回到更適合的角色。另一方面,另一方面,如果英偉達能夠加速更大一部分數(shù)據(jù)傳輸,它將征服大部分屬于英特爾并迅速擴展的市場。在這場激烈的戰(zhàn)斗中,IBM和AMD必須確保他們獲得市場份額。IBM將提供更好的基于英偉達 GPU的服務(wù)器,AMD將嘗試構(gòu)建合適的軟件生態(tài)系統(tǒng)。
測試筆記
隨著市場的發(fā)展,很明顯,除了AMD和ARM之外,英偉達的專業(yè)產(chǎn)品對英特爾在數(shù)據(jù)中心及其他領(lǐng)域的主導(dǎo)地位構(gòu)成了真正的威脅。因此,對于我們今天的測試,我們將專注于機器學(xué)習(xí),并了解英特爾新推出的DL Boosted產(chǎn)品如何應(yīng)對ML領(lǐng)域的競爭。
當(dāng)然,在英特爾方面,我們正在關(guān)注該公司新的Cascade Lake Xeon可擴展CPU。該公司提供了28個核心型號中的兩個,其中包括165瓦Xeon Platinum8176,以及更快的205瓦Xeon Platinum8280。
用于與Cascade Lake的比較評測,我們使用了英偉達最新的“圖靈(Turing)”泰坦(Titan)RTX卡。雖然這些并不是真正的數(shù)據(jù)中心卡,但它們是基于Turing的,這意味著它們提供了英偉達最新的功能。在我工作的大學(xué)里,我們的深度學(xué)習(xí)研究人員使用這些GPU來訓(xùn)練人工智能模型,因為泰坦卡價格低廉,而且有大量GPU內(nèi)存可用。
另外,Titan RTX卡可以同時用于訓(xùn)練(混合FP32/16)作為推理(FP16和INT8)。目前的特斯拉仍然基于英偉達的Volta架構(gòu),該架構(gòu)沒有可供推斷的INT8。
最后,不排除,我們也包括AMD的第一代EPYC平臺在我們所有的測試。AMD沒有像英特爾那樣的硬件策略,也沒有像VNNI那樣的具體指令,但最近該公司提供了各種各樣的驚喜。
測試基準(zhǔn)配置和方法
我們所有的測試都是在Ubuntu Server18.04 LTS上進行的。您會注意到DRAM容量因我們的服務(wù)器配置而異。這當(dāng)然是因為Xeons可以訪問六個內(nèi)存通道,而EPYC CPU有八個通道。據(jù)我們所知,我們所有的測試都適合128GB,因此DRAM容量對性能影響不大。但它會對總能耗產(chǎn)生影響,我們將對此進行討論。
最后但并非最不重要的是,我們要注意性能圖表是如何進行顏色編碼的。Orange是AMD的EPYC,深藍色是Intel最好的(Cascade Lake / Skylake-SP),淺藍色是上一代Xeon(Xeon E5-v4)。Gray已被用于即將被替換的Xeon v1。

我們啟用了超線程和英特爾虛擬化加速。
Xeon - NVIDIA Titan RTX工作站

AMD EPYC 7601 - (2U機箱)

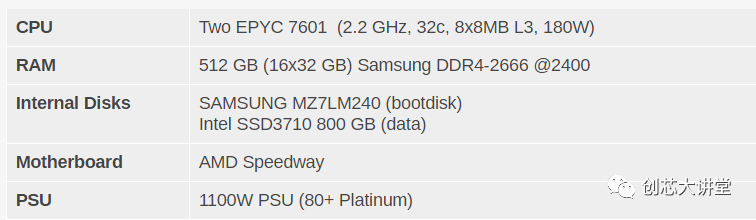
其他說明
兩臺服務(wù)器均由標(biāo)準(zhǔn)的歐洲230V(最大16安培)電源線供電。我們的Airwell CRAC監(jiān)測室溫并保持在23°C。
CPU性能
在我們進入新的AI基準(zhǔn)測試之前,讓我們快速了解一下英特爾提供的常用CPU基準(zhǔn)測試和性能聲明。
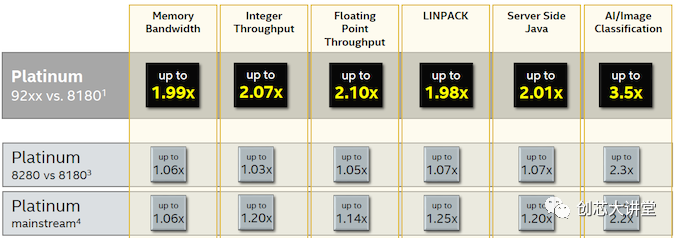
為了進行比較,我們將重點關(guān)注第二排 - 第一排是將價格極為驚人的400W雙芯片英特爾鉑金9282與更合理的產(chǎn)品進行比較,并向所有人提供英特爾鉑金8180.第二行說明了所有內(nèi)容:幾MHz與第一代Xeon可擴展部件相比,RAM速度稍高,可使性能提高3%(整數(shù))至5%(FP)。浮點性能的更高提升可能是因為英特爾的第二代部件可以使用更快的DDR4-2933 DIMM,從而為內(nèi)核提供更多帶寬。
中端SKU得到更大的推動,因為一些x2xx Xeon 可擴展部件比以前的x1xx部件獲得更多內(nèi)核和更多L3緩存。例如,6252具有24個核心和35.75 MB L3,而6152具有22個核心和30.25 MB L3。
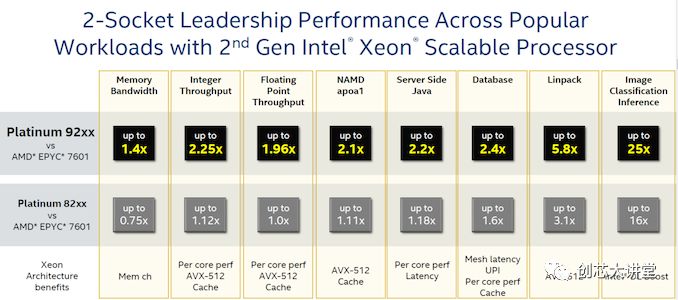
然而,與AMD的EPYC 7601的比較值得我們關(guān)注,因為這里有一些有趣的數(shù)據(jù)。再次,400W,$50k小芯片CPU與180W $4k芯片CPU的比較沒有任何意義,所以我們忽略了第一行。
Linpack數(shù)據(jù)并不令人驚訝:更昂貴的Skylake SKU為現(xiàn)有的雙256位FMAC增加了512位FMAC,提供的AVX吞吐量比AMD的EPYC高出4倍。由于每個FP單元現(xiàn)在能夠執(zhí)行256位AVX而不是128位,因此AMD的下一代將在這一領(lǐng)域更具競爭力。
圖像分類結(jié)果清楚地表明,英特爾試圖讓人們相信某些AI應(yīng)用程序應(yīng)該只在CPU上運行,而不需要GPU。
英特爾聲稱數(shù)據(jù)庫性能比EPYC好得多,這一事實非常有趣,正如我們之前指出的,AMD的4個NUMA芯片確實有缺陷。引用我們的Xeon Skylake vs . EPYC的評論:
開箱即用,EPYC CPU是一個相當(dāng)普通的事務(wù)數(shù)據(jù)庫CPU…事務(wù)數(shù)據(jù)庫目前仍將是Intel的領(lǐng)域。
在數(shù)據(jù)庫中,緩存(一致性)延遲起著重要作用。看看AMD在第二代EPYC服務(wù)器芯片上是如何解決這一弱點的,將是一件很有趣的事情。
SAP S&D
在我們開始使用數(shù)據(jù)分析ML基準(zhǔn)之前的最后一站:SAP。企業(yè)資源規(guī)劃軟件是“傳統(tǒng)”企業(yè)軟件的完美典范。
SAP S&D 2-Tier基準(zhǔn)測試可能是供應(yīng)商完成的所有服務(wù)器基準(zhǔn)測試中最真實的基準(zhǔn)測試。它是一個完整的應(yīng)用程序,生活在一個繁重的關(guān)系數(shù)據(jù)庫之上。
我們在之前的一篇文章中深入分析了SAP Benchmark :
不同供應(yīng)商提供了許多基準(zhǔn)測試結(jié)果。為了獲得(或多或少)蘋果與蘋果的比較,我們僅限于在SQL Server 2012Enterprise上運行的“SAPS結(jié)果”。
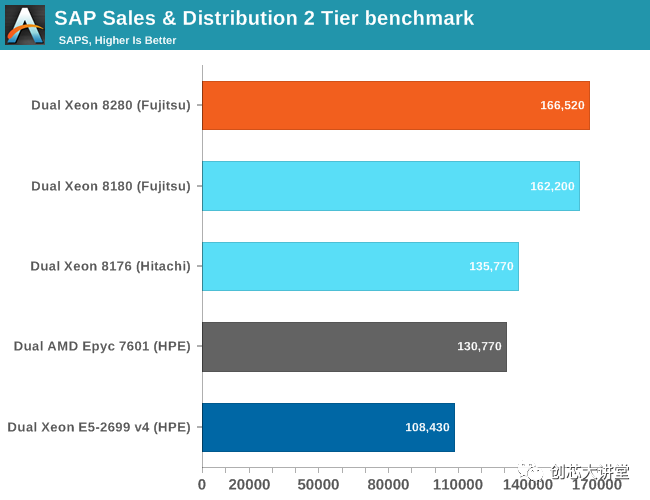
基于Xeon 8180和8280的服務(wù)器的富士通基準(zhǔn)測試與我們可以獲得的一樣多:與測試和調(diào)優(yōu)相同的人,相同的操作系統(tǒng)和數(shù)據(jù)庫。略高的時鐘(+ 200 Mhz,+ 8%)使性能提高3%。兩個CPU都有28個內(nèi)核,但8280的時鐘速度提高了8%,從某種意義上說,這種時鐘速度的提升并沒有帶來更大的性能提升,這令人驚訝。我們得到的結(jié)論是,Cascade Lake的時鐘頻率可能比Skylake略慢,因為兩個SPEC CPU基準(zhǔn)測試也只增加了3%到5%。
因此,在典型的企業(yè)堆棧中,您需要在相同的價格/能耗下獲得約3%的性能提升。然而,AMD便宜得多(編輯:很快就會更新)$ 4k EPYC 7601并沒有那么落后。考慮到EPYC已經(jīng)在昂貴的兩倍8176(2.1 GHz,28個核心)的誤差范圍內(nèi),8276具有稍高的時鐘速度(2.2 Ghz)并不會顯著改善問題。即使是Xeon 8164(26 GHz,2 GHz)也能提供與EPYC 7601 大致相同的性能,但仍然要高出 50%。
考慮到AMD在Zen 2架構(gòu)方面取得了多大進展,以及頂級SKU將內(nèi)核數(shù)量增加一倍(64比32),看起來AMD羅馬將對Xeon銷售施加更大壓力。
Apache Spark 2.1基準(zhǔn)測試
Apache Spark是大數(shù)據(jù)處理的典范。加速大數(shù)據(jù)應(yīng)用程序是我工作的大學(xué)實驗室(西佛蘭德大學(xué)學(xué)院的Sizing Servers Lab)的首要項目,因此我們制作了一個基準(zhǔn),它使用了許多Spark功能并基于實際使用情況。

該測試在上圖中描述。我們首先從從CommonCrawl收集的300 GB壓縮數(shù)據(jù)開始。這些壓縮文件是大量的Web存檔。我們在運行中解壓縮數(shù)據(jù)以避免長時間的等待,這主要與存儲相關(guān)。然后,我們使用Java庫“BoilerPipe”從存檔中提取有意義的文本數(shù)據(jù)。使用Stanford CoreNLP自然語言處理工具包,我們從文本中提取實體(“含義詞”),然后計算這些實體中出現(xiàn)次數(shù)最多的URL。然后使用交替最小二乘算法來推薦哪些URL對于某個主題最有趣。
我們將最新的服務(wù)器轉(zhuǎn)換為虛擬集群,以更好地利用所有這些核心。我們運行8個執(zhí)行器。研究員Esli Heyvaert也升級了我們的Spark基準(zhǔn)測試,因此它可以在Apache Spark 2.1.1上運行。
結(jié)果如下:
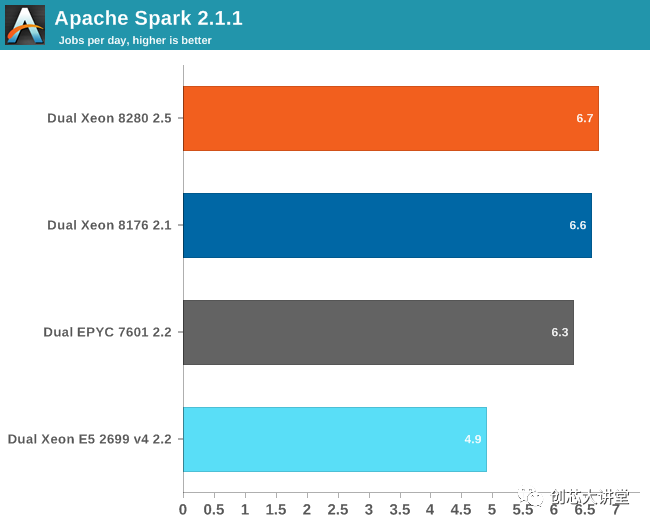
我們的Spark基準(zhǔn)測試需要大約120 GB的RAM才能運行。在存儲I / O上花費的時間可以忽略不計。數(shù)據(jù)處理非常平行,但是混洗階段需要大量的內(nèi)存交互。ALS階段在許多線程上的擴展性不佳,但不到總測試時間的4%。
由于我們不知道的原因,我們可以讓我們的2.7 GHz 8280比2.1 GHz Xeon 8176 表現(xiàn)更好。我們懷疑我們使用新的Xeon芯片與舊的(Skylake-SP)服務(wù)器的事實可能是原因,嘗試不同的Spark配置(執(zhí)行程序,JVM設(shè)置)沒有幫助。BIOS更新對我們也沒有幫助。
好吧,這是大數(shù)據(jù)處理與大多數(shù)“傳統(tǒng)”機器學(xué)習(xí)相結(jié)合:NER和ALS。一些“深度學(xué)習(xí)”怎么樣?
卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練
很長一段時間,CNN的前進方向是增加層數(shù) - 增加“更深入學(xué)習(xí)”的網(wǎng)絡(luò)深度。正如你可能猜到的那樣,這導(dǎo)致收益遞減,并使已經(jīng)很復(fù)雜的神經(jīng)網(wǎng)絡(luò)更難調(diào)整,導(dǎo)致更多的訓(xùn)練錯誤。
所述RESNET-50基準(zhǔn)是基于剩余網(wǎng)絡(luò)(因此RESNET),其具有更少的訓(xùn)練誤差的優(yōu)點作為網(wǎng)絡(luò)變得更深。
同時,作為一些內(nèi)部管家,對于普通讀者,我會注意到下面的基準(zhǔn)與Nate為我們的Titan V評論所進行的測試不能直接比較。它是相同的基準(zhǔn),但Nate運行了英偉達的Caffe2 Docker映像中包含的標(biāo)準(zhǔn)ResNet-50培訓(xùn)實現(xiàn)。但是,由于我的團隊主要使用TensorFlow作為深度學(xué)習(xí)框架,我們傾向于堅持使用它。所有基準(zhǔn)測試
tf_cnn_benchmarks.py --num_gpus = 1 --model =resnet50 --variable_update = parameter_server
該模型在ImageNet上訓(xùn)練并為我們提供吞吐量數(shù)據(jù)。
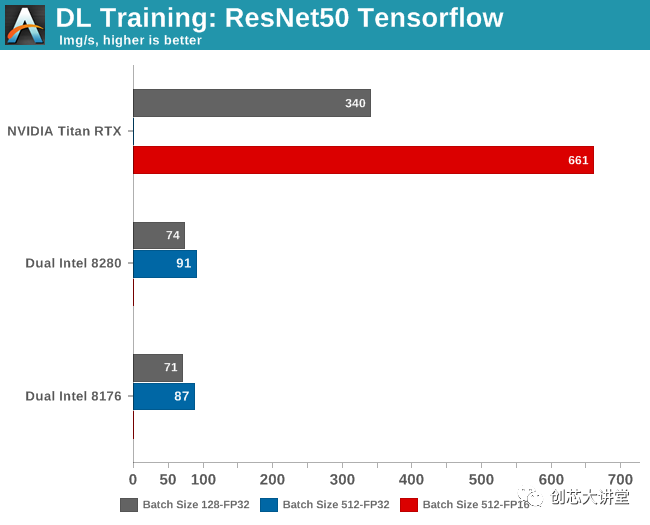
缺少幾個基準(zhǔn),這是有充分理由的。在Titan RTX上以FP32精度運行批量大小為512個訓(xùn)練樣本會導(dǎo)致“內(nèi)存不足”錯誤,因為該卡“僅”具有24 GB可用空間。
同時在Intel CPU上,半精度(FP16)尚不可用。AVX512 _ BF16(bfloat16)將在Cascade Lake的繼任者Cooper Lake中推出。
已經(jīng)觀察到,使用較大批次可以導(dǎo)致模型質(zhì)量的顯著降低,如通過其概括的能力所測量的。因此,雖然較大的批量大小(512)可以更好地利用GPU內(nèi)部的大規(guī)模并行性,但批量較小(128)的結(jié)果也很有用。該模型的準(zhǔn)確性僅損失了幾個百分點,但在許多應(yīng)用中,甚至幾個百分點的損失都很重要。
因此,盡管您可以很快得出結(jié)論,Titan RTX的速度比最佳CPU快7倍,但根據(jù)您想要的精度,它可以更準(zhǔn)確地說它的速度提高了4.5到7倍。
循環(huán)神經(jīng)網(wǎng)絡(luò):LSTM
我們的忠實讀者知道我們喜歡現(xiàn)實世界的企業(yè)基準(zhǔn)。因此,在我們尋求更好的基準(zhǔn)和更好的數(shù)據(jù)的過程中,MCT IT學(xué)士 (荷蘭語)的研究負責(zé)人Pieter Bovijn 將現(xiàn)實世界的AI模型轉(zhuǎn)變?yōu)榛鶞?zhǔn)。
模型的輸入是時間序列數(shù)據(jù),用于預(yù)測時間序列在未來的行為方式。由于這是典型的序列預(yù)測問題,我們使用長短期記憶(LSTM)網(wǎng)絡(luò)作為神經(jīng)網(wǎng)絡(luò)。作為一種RNN,LSTM在一定的持續(xù)時間內(nèi)選擇性地“記住”模式。
然而,LSTM的缺點是它們的帶寬密集程度更高。我們引用最近一篇關(guān)于該主題的論文:
由于冗余數(shù)據(jù)移動和有限的片外帶寬,LSTM在移動GPU上執(zhí)行時表現(xiàn)出非常低效的存儲器訪問模式。
所以我們對LSTM網(wǎng)絡(luò)的表現(xiàn)非常好奇。畢竟,我們的服務(wù)器Xeons擁有足夠的帶寬,擁有38.5 MB的L3和6個DDR4-2666 / 2933通道(每個插槽128-141 GB / s)。我們使用50 GB的數(shù)據(jù)運行此測試,并將模型訓(xùn)練5個時期。
當(dāng)然,您可以充分利用可用的AVX / AVX2 /AVX512 SIMD電源。這就是我們使用3種不同設(shè)置進行測試的原因
1. 我們開箱即用TensorFlow與conda
2. 我們使用PyPi repo的Intel優(yōu)化TensorFlow進行了測試
3. 我們使用Bazel 從源代碼優(yōu)化 。這使我們可以使用最新版本的TensorFlow。
結(jié)果非常有趣。
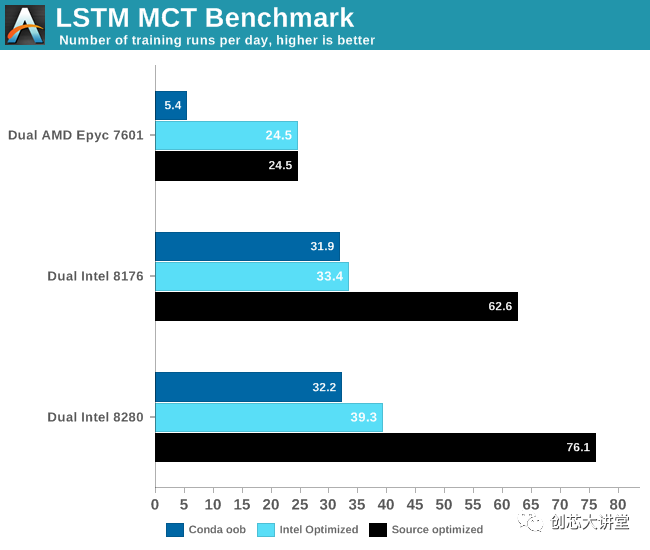
最密集的TensorFlow應(yīng)用程序通常在GPU上運行,因此在CPU上進行測試時必須格外小心。AMD的Zen核心只有兩個128位FMAC,并且僅限于(256位)AVX2。英特爾的高端Xeon處理器 有兩個256位FMACs和一個512位FMAC。換句話說,在紙面上,英特爾的至強可以在每個時鐘周期內(nèi)提供比AMD高四倍的FLOP。但只有軟件是正確的。英特爾一直與谷歌密切合作,為英特爾新Xeon優(yōu)化TensorFlow出于必要:它必須在英偉達 Tesla太昂貴的情況下提供可靠的替代方案。與此同時,AMD希望ROCm能夠繼續(xù)發(fā)展,未來軟件工程師將在Radeon Pro上運行TensorFlow。
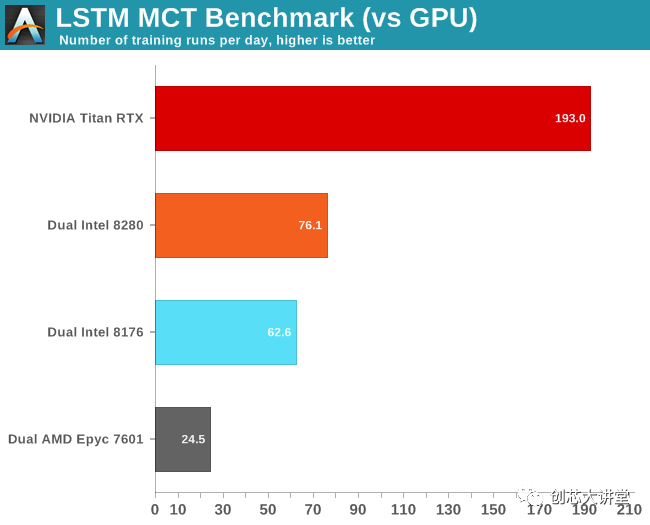
當(dāng)然,最大的問題是這與GPU相比如何。讓我們看看我們的英偉達 Titan RTX如何處理這種工作量。
首先,我們注意到FP16沒有太大的區(qū)別。其次,我們非常驚訝我們的Titan RTX比我們的雙Xeon設(shè)置快了不到3倍。
通過英偉達的系統(tǒng)管理接口(SMI)進一步調(diào)查,我們發(fā)現(xiàn)GPU確實以最高的渦輪速度運行:1.9 GHz,高于預(yù)期的1.775 GHz。同時利用率不時降至40%。
最后,這是另一個示例,說明實際應(yīng)用程序的行為與基準(zhǔn)測試的不同,以及軟件優(yōu)化的重要性。如果我們剛剛使用了conda,上面的結(jié)果將會非常不同。使用正確的優(yōu)化軟件使應(yīng)用程序運行速度提高了2到6倍。此外,這另一個數(shù)據(jù)點證明CNN可能是GPU的最佳用例之一。您應(yīng)該使用GPU來減少復(fù)雜LSTM的訓(xùn)練時間。不過,這種神經(jīng)網(wǎng)絡(luò)有點棘手 - 你不能簡單地添加更多的GPU來進一步減少訓(xùn)練時間。
推論:ResNet-50
在根據(jù)訓(xùn)練數(shù)據(jù)訓(xùn)練您的模型之后,等待真正的測試。你的人工智能模型現(xiàn)在應(yīng)該能夠?qū)⑦@些知識應(yīng)用到現(xiàn)實世界中,并對新的現(xiàn)實數(shù)據(jù)做同樣的事情。這個過程叫做推理。推理不需要反向傳播,因為模型已經(jīng)經(jīng)過訓(xùn)練——模型已經(jīng)確定了權(quán)重。推理還可以利用較低的數(shù)值精度,并已證明,即使使用8位整數(shù)的精度有時是可以接受的。
從高級工作流執(zhí)行的角度來看,一個工作的AI模型基本上是由一個服務(wù)控制的,而這個服務(wù)又是由另一個軟件服務(wù)調(diào)用的。因此模型應(yīng)該響應(yīng)非常快,但是應(yīng)用程序的總延遲將由不同的服務(wù)決定。長話短說:如果推斷性能足夠高,感知到的延遲可能會轉(zhuǎn)移到另一個軟件組件。因此,Intel的任務(wù)是確保Xeons能夠提供足夠高的推理性能。
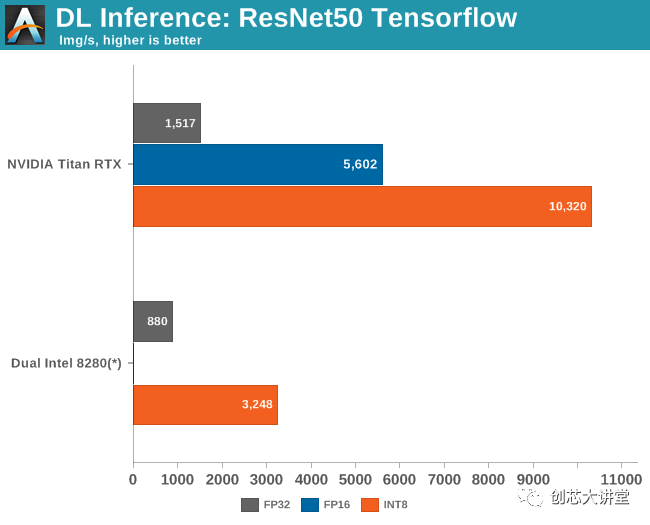
由于DL Boost技術(shù),英特爾有一個特殊的“秘訣”,可以在Cascade Lake上達到最佳推理性能。DLBoost包含矢量神經(jīng)網(wǎng)絡(luò)指令,允許使用INT8操作代替FP32。整數(shù)運算本質(zhì)上更快,并且通過僅使用8位,您獲得理論峰值,這是高四倍。
更復(fù)雜的是,當(dāng)我們的Cascade Lake服務(wù)器崩潰時,我們正在嘗試推理。對于它的價值,我們從未達到每秒超過2000張圖像。但由于我們無法進一步實驗,我們給了英特爾懷疑的好處并使用了他們的數(shù)字。
與此同時,9282的出版引起了不小的轟動,因為英特爾聲稱最新的Xeons比英偉達的旗艦加速器(特斯拉V100)略勝一籌:7844比7636每秒的圖像。英偉達通過強調(diào)性能/瓦特/美元立即作出反應(yīng),并在報刊上獲得了大量報道。然而,我們拙見的最重要的一點是,特斯拉V100的結(jié)果無法比擬,因為每秒7600張圖像是在混合模式(FP32 / 16)而非INT8中獲得的。
一旦我們啟用INT8,2500美元的Titan RTX速度不會低于一對價值10萬 美元的Xeon 8280。
英特爾無法贏得這場戰(zhàn)斗,而不是一蹴而就。盡管如此,英特爾的努力以及NIVIDA的回應(yīng)表明英特爾在提高推理和培訓(xùn)績效方面的重要性。說服人們投資高端 Xeon而不是使用特斯拉V100的低端Xeon。在某些情況下,由于推理軟件組件只是軟件堆棧的一部分,因此比英偉達的產(chǎn)品慢3倍。
事實上,要真正分析所有角度的情況,我們還應(yīng)該測量完整的AI應(yīng)用程序的延遲,而不僅僅是測量推理吞吐量。但是,這將花費我們更多的時間來使這一個正確......
探索并行HPC
與服務(wù)器軟件基準(zhǔn)測試一樣,HPC基準(zhǔn)測試需要大量研究。我們絕對不是HPC專家,所以我們將自己限制在一個HPC基準(zhǔn)測試中。
NAMD由伊利諾伊大學(xué)厄巴納 - 香檳分校的理論和計算生物物理學(xué)小組開發(fā),是一套用于數(shù)千個核心極端并行化的并行分子動力學(xué)代碼。NAMD也是SPEC CPU2006 FP的一部分。
公平地說,NAMD主要是單精度。而且,正如您可能知道的那樣,Titan RTX旨在擅長單精度工作負載; 所以NAMD基準(zhǔn)測試與Titan RTX非常匹配。特別是現(xiàn)在NAMD的作者揭示了:
在Pascal(P100)或更新的支持CUDA的GPU上運行時,性能顯著提高。
不過,這是一個有趣的基準(zhǔn),因為NAMD二進制文件是使用英特爾ICC編譯的,并針對AVX進行了優(yōu)化。對于我們的測試,我們使用了“ NAMD _2.13_ Linux-x86 _ 64-multicore ”二進制文件。這個二進制文件支持AVX指令,但只支持Intel Xeon Phi 的“特殊” AVX-512指令。因此,我們還編譯了一個AVX-512 ICC優(yōu)化二進制文件。這樣我們就能真正衡量AVX-512的運算能力。Xeon與英偉達的GPU加速相比。
我們使用了最流行的基準(zhǔn)負載apoa1(載脂蛋白 A1)。結(jié)果以每個掛鐘日的模擬納秒表示。我們測量500步。
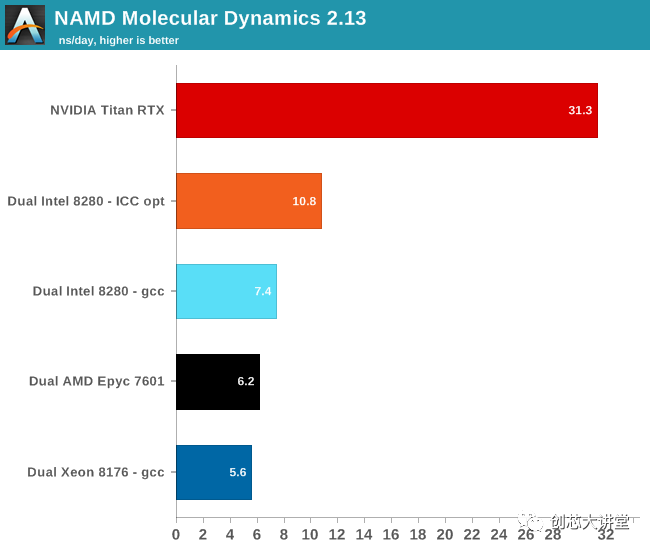
使用AVX-512可將此基準(zhǔn)測試的性能提升46%。但同樣,這款軟件在GPU上的運行速度要快得多,這當(dāng)然是可以理解的。至多,Xeon有28個內(nèi)核,運行頻率為2.3 GHz。每個循環(huán)可以完成32次單精度浮動操作。總而言之,Xeon可以做2個TFLOP(2.3 G * 28 * 32)。所以雙Xeon設(shè)置最多可以完成4個TFLOP。泰坦RTX,在另一方面,可以做 16TFLOP 小號,或4倍之多。最終結(jié)果是,NAMD在Titan上的運行速度比雙Intel Xeon快3倍。
總結(jié)一下,讓我們來看看第二代Xeon Scalable的性能,以及它在功能方面帶來的好處。使用Cascade Lake,英特爾將性能提高了3%到6%,提高了安全性,修復(fù)了一些非常重要的漏洞/攻擊,添加了一些SIMD指令,并改進了整個服務(wù)器平臺。這不是什么驚天動地,但是你得到更多相同的價格和功率范圍,那么什么不喜歡?
5年前,當(dāng)AMD沒有像Zen(2)體系結(jié)構(gòu)這樣的東西時,ARM供應(yīng)商仍然在努力應(yīng)對提供痛苦的單線程性能緩慢的內(nèi)核,并且深度學(xué)習(xí)處于早期階段。但這不是2014年,當(dāng)時英特爾的表現(xiàn)優(yōu)于最接近的競爭對手3倍!最終,Cascade Lake在CPU(而且只有CPU)運行良好的領(lǐng)域提供服務(wù)。但即使有英特爾的DL Boost努力,如果新芯片必須與GPU進行正面交鋒,而后者并不完全畏縮,那還不夠。
現(xiàn)實情況是,英特爾的數(shù)據(jù)中心集團面臨來自各方的巨大壓力。盡管整個服務(wù)器市場正在增長,但數(shù)據(jù)中心多年來第一次出現(xiàn)收入下降。
它已經(jīng)持續(xù)了一段時間,但正如我們親身經(jīng)歷的那樣,基于機器學(xué)習(xí)的AI應(yīng)用程序正在成功推出,它們是軟件和硬件的游戲規(guī)則改變者。因此,未來的服務(wù)器CPU評論將永遠不會完全相同:它不再是Intel與AMD甚至ARM,而是英偉達。英偉達在深度學(xué)習(xí)市場上非常成功,他們有足夠的信心在英特爾主導(dǎo)多年的領(lǐng)域采用英特爾:HPC,機器學(xué)習(xí),甚至數(shù)據(jù)處理。英偉達已準(zhǔn)備好加速數(shù)據(jù)管道的更大部分和更廣泛的AI應(yīng)用程序。
英特爾Cascade Lake中的功能如DL Boost(VNNI)是英特爾首次嘗試推遲 - 以削減英偉達在推理性能方面的巨大優(yōu)勢。與此同時,下一個Xeon - CooperLake將嘗試更接近英偉達的訓(xùn)練表現(xiàn)。

這張以“領(lǐng)先表現(xiàn)”為賣點的PPT還很方便地描述了英特爾在哪些市場處于非常脆弱的地位,盡管英特爾目前在數(shù)據(jù)中心占據(jù)主導(dǎo)地位。雖然PPT的重點是英特爾Xeon 9200,這可能是一個很容易為高端鉑金8200 Xeons的PPT。
英特爾瞄準(zhǔn)了高性能計算、人工智能和高密度的基礎(chǔ)設(shè)施來銷售其昂貴的Xeons。但隨著市場轉(zhuǎn)向不那么傳統(tǒng)的商業(yè)智能、更多的機器學(xué)習(xí)和GPU加速的高性能計算,高端Xeons的市場正在萎縮。英特爾擁有非常廣泛的人工智能產(chǎn)品組合,從Movidius (edge inference)到Nervana NNP(用于DL培訓(xùn)的ASIC),他們將需要它來取代Xeon在這些細分市場的份額。
中檔的Xeon與Nervana NNP協(xié)處理器結(jié)合使用可能會很好,而且對于大多數(shù)人工智能應(yīng)用程序來說,它肯定是比Xeon 9200更好的解決方案。同樣的道理也適用于高性能計算:我們愿意打賭,如果你使用中檔Xeons和一個快速的英偉達 GPU,你的情況會好得多。根據(jù)AMD的EPYC 2的定價,即使是這樣也可能會有爭議。
免責(zé)聲明:本文由作者原創(chuàng)。文章內(nèi)容系作者個人觀點,轉(zhuǎn)載目的在于傳遞更多信息,并不代表EETOP贊同其觀點和對其真實性負責(zé)。如涉及作品內(nèi)容、版權(quán)和其它問題,請及時聯(lián)系我們,我們將在第一時間刪除!

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章



















