面向未來的PCI-Express交換機推理服務器
2025-03-28 11:40:38 EETOP點擊關注半導體創芯網,后臺告知EETOP論壇用戶名,獎勵200信元
在數據中心系統的發展歷程中,能被英偉達選為其人工智能系統的組件供應商,這無疑是至高無上的贊譽。
這也正是新興互連芯片制造商阿斯特拉實驗室(Astera Labs)感到頗為得意的原因。該公司正與博通(Broadcom)和美滿電子(Marvell)等公司在 PCI-Express 交換機、PCI-Express 重定時器以及 CXL 內存控制器等領域展開競爭。英偉達認可其即將推出的使用Blackwell GPU 加速器的服務器節點,采用阿斯特拉實驗室的 PCI-Express 6.0 交換機和重定時器,將 X86 GPU 與Blackwell GPU 相連,在某些情況下還會連接網絡接口卡和存儲設備。
MGX 是一套服務器參考設計,它構成了英偉達自身人工智能服務器的基本架構,原始設備制造商(OEM)和原始設計制造商(ODM)也會基于此進行復刻,以便分得一杯羹。
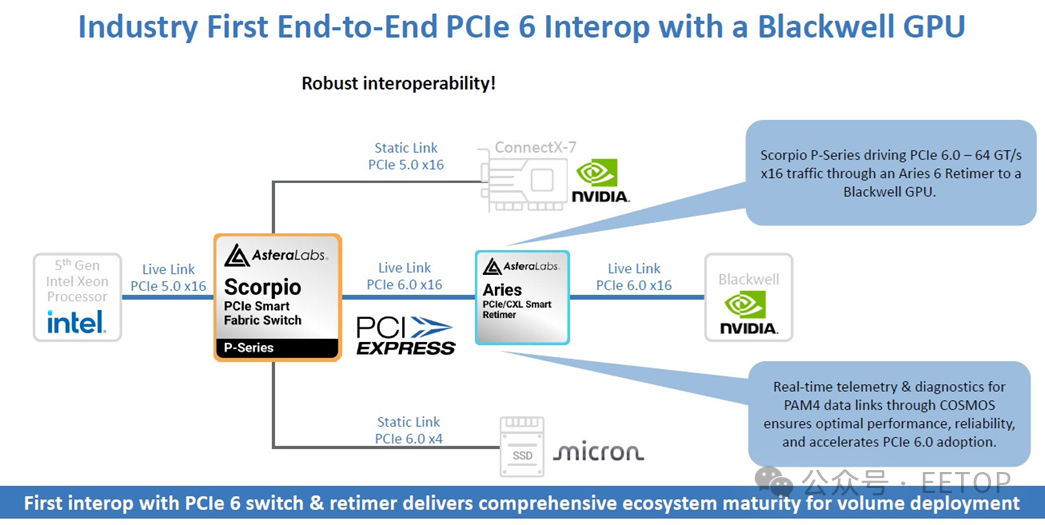
在上周舉行的 2025 年 GPU 技術大會(GPU Technical Conference 2025)上,阿斯特拉實驗室做了兩件事。首先,該公司展示了其 “天蝎座”(Scorpio)P 系列 PCI-Express 6.0 結構交換機和 “白羊座”(Aries)PCI-Express 6.0 重定時器,與英偉達的 Hopper H100 和 H200 GPU,以及用于 HGX 配置的各種Blackwell B100 和 B200 GPU 之間的互操作性(大家熟悉的雙 CPU 搭配八 GPU 的設計,如今Hopper 架構的被稱為 HGX NVL8,Blackwell 架構的則叫 DGX NVL16)。其次,阿斯特拉實驗室展示了一款由 ODM 服務器制造商緯創(Wistron)設計的推理服務器,該服務器基于Hopper GPU,并使用阿斯特拉的交換機和重定時器將各個組件連接在一起。
目前還完全不清楚英偉達自身在其系統中哪些地方使用了阿斯特拉的芯片,我們只是借這一消息來了解一下阿斯特拉所提供的產品。不過,英偉達硬件工程副總裁安德魯?貝爾(Andrew Bell)確實在一份聲明中表示,“天蝎座” 交換機已集成到 “基于Blackwell的 MGX 平臺” 中,所以就是這樣。基于數字信號處理器(DSP)的 “白羊座” 重定時器雖未被提及,但如果你需要擴展 PCI-Express 5.0 或 6.0 鏈路以拉開組件之間的距離,同樣也需要這類設備。
從概念上講,整個架構是這樣的:

如你所見,你可以使用重定時器將 GPU 連接到網絡或存儲結構,以及另一個用于直接將 GPU 相互連接的 PCI-Express 結構,這與英偉達使用 NVLink 端口和 NVSwitch 交換機的方式非常相似。目前,對于 GPU 加速器而言,這種 PCI-Express 結構上不存在內存尋址功能,但這正是由 AMD、博通、思科系統(Cisco Systems)、谷歌(Google)、慧與(Hewlett Packard Enterprise)、英特爾(Intel)、Meta Platforms和微軟(Microsoft)牽頭開展的超高速加速器鏈路(UALink)項目的目標所在。
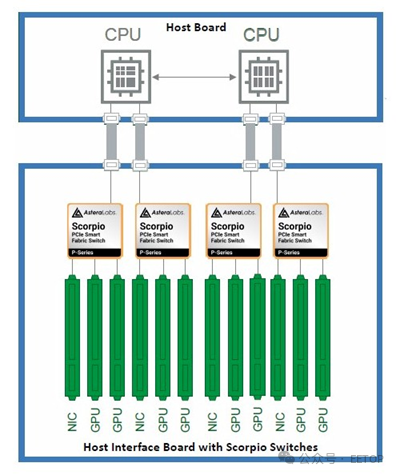
“天蝎座” P 系列交換機用于將 CPU 連接到 GPU、網絡接口和存儲設備,“天蝎座” 交換機還有另一個版本,即 X 系列,用于創建 GPU 網格,這與英偉達的 NVSwitch 的作用類似,顯然其帶寬要低得多。這款 X 系列芯片需要定制化的合作項目,不出所料,在 2025 年的 GPU 技術大會上,阿斯特拉絕對不會提及這款芯片。
P 系列和 X 系列交換機都向后兼容一直到 PCI-Express 1.0 的設備。
就 PCI-Express 6.0 而言,以下是阿斯特拉與英偉達共同測試的內容:
“天蝎座” P 系列交換機于 2024 年 9 月開始提供樣品,目前正在逐步擴大量產規模。
阿斯特拉與 ODM 合作伙伴緯創展示的機器,是英偉達 MGX H100/H200 NVL 推理服務器的一個具體實現。MGX 系列模塊化機器于 2023 年 5 月推出,其理念是將 GPU 加速應用于不同類型的工作負載,并采用適合相應用途的外形規格。
從概念上看,MGX 推理服務器是這樣的:

這是一個 4U 機架式機箱,后部有一個雙插槽 X86 服務器作為系統主機,配備 PCI-Express 交換機,連接到兩個BlueField 3數據處理單元(DPU,位于前方右側)以及八個 H100 或 H200 PCI-Express 5.0 GPU(位于前方,占據了大部分空間)。沒有 NVSwitch 內存互連,但每張 GPU 卡上都有 NVLink 內存端口,并且可以使用橋接器將兩個或四個相鄰的 GPU 連接成共享內存配置,以便共享內存并針對更大的內存進行計算。
這種 MGX 參考架構還有其他配置,例如配備一個BlueField 3 DPU 和四個 ConnectX-7 智能網卡,每兩個 GPU 對應一個智能網卡。
以下是每個 “天蝎座” 交換機連接兩個 GPU 和一個網卡的 MGX 推理系統原理圖:
每對通過 NVLink 橋接器連接的 GPU,都有一個 ConnectX-7 網卡,用于與外部世界通信,并通過 “天蝎座” P 系列交換機進行數據傳輸。我們推測,這對 GPU 也可以通過 “天蝎座” 交換機以 PCI-Express 6.0 速度進行通信。如果 GPU 支持 PCI-Express 6.0,x16 通道的速度可達 256GB/秒;如果僅支持 PCI-Express 5.0,則速度只有 128GB/秒。
在主機 CPU 和 GPU 之間需要多少帶寬,以及 NVLink 非統一內存訪問(NUMA)的級別(NVL2 或 NVL4),取決于你所進行的人工智能類型。
這款 MGX 推理服務器設計的一個重要特點是它具有模塊化特性。(因此 MGX 中的 “M” 代表 “Modular”,即模塊化的 GPU,我們不確定 “X” 代表什么)
以下是緯創實際的 “xWing” 推理服務器 GPU 系統板的樣子:

這種設計每個 “天蝎座” 交換機連接兩個 GPU,并且在板的左側有一個網卡插槽。
沒有一款 MGX 推理服務器設計能夠對擁有數萬億參數的生成式人工智能(GenAI)模型進行推理。但對于許多人工智能推理工作負載來說,它們的規模恰到好處。
原文:
https://www.nextplatform.com/2025/03/27/future-proofing-inference-servers-with-pci-express-switches/
關鍵詞: PCI-Express 交換機 服務器