突破芯片制裁,現(xiàn)有工藝下提升計(jì)算芯片算力有哪些效手段?
2023-09-22 12:37:15 EETOP以深度學(xué)習(xí)為核心技術(shù)的人工智能有三大關(guān)鍵要素:算法、數(shù)據(jù)和算力。據(jù)預(yù)估,到2030年,通用算力將增長10倍,而人工智能算力將增長500倍。大模型需要大算力,算力是人工智能發(fā)展的核心驅(qū)動力。算力大小決定著AI迭代與創(chuàng)新的速度,也影響著經(jīng)濟(jì)發(fā)展的速度,算力的稀缺和昂貴已經(jīng)成為制約AI發(fā)展的核心因素。
芯片算力就是芯片每秒鐘能夠執(zhí)行乘累加運(yùn)算量的大小。算力就是在CMOS集成電路上執(zhí)行萬億次/秒的簡單乘累加操作,操作數(shù)越大算力越高!增大算力一般采用改進(jìn)電路結(jié)構(gòu),提高芯片面積、增加MAC數(shù)量或者說提高芯片工藝制程等方法。這些依賴物理工藝的提升法,并不涉及計(jì)算電路的本質(zhì)問題,即“二進(jìn)制數(shù)”高效運(yùn)算。
北京航空航天大學(xué)責(zé)任教授李洪革老師在EETOP于2023年8月24日在深圳舉辦的“芯片設(shè)計(jì)技術(shù)高峰論壇”上表示:“針對我國芯片制備受制裁的情況,探索CMOS冗余數(shù)、概率數(shù)、殘余數(shù)甚至高維數(shù)系的運(yùn)算機(jī)制,才是我國避免依賴芯片工藝還能提高算力的有效手段。”

李洪革,北京航空航天大學(xué)責(zé)任教授
什么是計(jì)算芯片?
CPU是最傳統(tǒng)的計(jì)算芯片,出現(xiàn)于大規(guī)模集成電路時代。可以說,有計(jì)算機(jī)以來就有CPU。它是計(jì)算機(jī)系統(tǒng)的運(yùn)算和控制核心,擅長各種任務(wù)的調(diào)度,是信息處理、程序運(yùn)行的最終執(zhí)行單元。1971年英特爾推出了世界上第一臺微處理器4004,有2300個晶體管,是第一個用于計(jì)算器的4位微處理器。雖然這款產(chǎn)品的功能相當(dāng)有限,且運(yùn)行速度慢,但是它是第一個運(yùn)用到個人使用的微機(jī)中,由此也開啟了CPU的發(fā)展之路。
第二類計(jì)算芯片就是GPU。1999年,NVIDIA公司在發(fā)布其標(biāo)志性產(chǎn)品GeForce256時,首次提出了GPU的概念。GeForce256是由NVIDIA研發(fā)的第五代顯示核心,擁有2300萬個晶體管,是256-bit顯示架構(gòu),擁有4條像素流水線。每一條有4個像素單元,1個材質(zhì)單元。三角形生成率是每秒1500萬個,像素生成率則是每秒4億8000萬個。NVIDIA率先將硬件T&L整合到GPU中。在此之前,電腦中處理影像輸出的顯示芯片,通常很少被視為是一個獨(dú)立的運(yùn)算單元。GeForce 256憑著它的功能和速度,在各顯卡的強(qiáng)力競爭下,令NⅥDIA的電腦圖形工業(yè)霸主地位更堅(jiān)固。
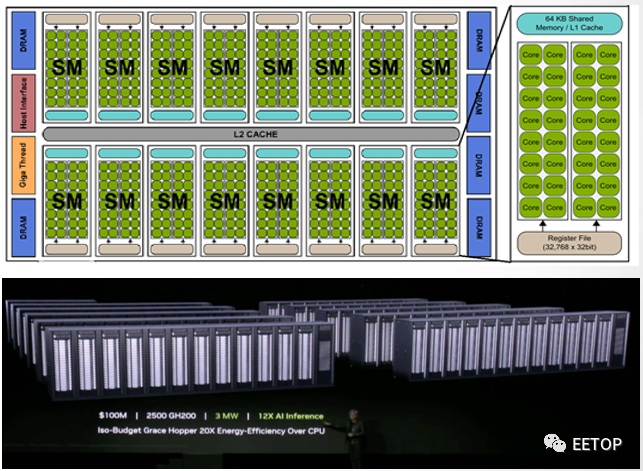
1億美元買2500塊GH200組成的Iso-Budget數(shù)據(jù)中心,功耗是3MW,AI推理性能達(dá)到CPU系統(tǒng)的12倍,能效達(dá)20倍。
GPU即圖像處理器,是Graphics Processing Unit的縮寫,又被稱為顯示核心、視覺處理器、顯示芯片。它和CPU的工作流程和物理結(jié)構(gòu)大致相似,不過在處理圖形數(shù)據(jù)和復(fù)雜算法方面擁有比CPU更高的效率。CPU大部分面積為控制器和寄存器,而GPU是基于大的吞吐量設(shè)計(jì),有很多的算術(shù)運(yùn)算單元和很少的緩存。相較CPU,GPU的工作則更為單一,只處理最簡單的數(shù)學(xué)計(jì)算指令,但它內(nèi)部有幾千個處理單元可以同時做處理,因此特別擅長做簡單但大規(guī)模的并發(fā)計(jì)算,此外,GPU具有高并行結(jié)構(gòu),且擁有更多的ALU(Arithmetic Logic Unit,算術(shù)邏輯運(yùn)算單元),用于數(shù)據(jù)計(jì)算處理,這樣的結(jié)構(gòu)更適合對密集型數(shù)據(jù)進(jìn)行并行處理。
還有一類計(jì)算芯片,即TPU。它始于算力瓶頸,首秀便是2016年轟動世界的人機(jī)大戰(zhàn)——AlphaGo對戰(zhàn)李世石。那一年,AlphaGo以4:1總分打敗圍棋世界冠軍李世石,隨后獨(dú)戰(zhàn)群雄。區(qū)別于GPU,谷歌TPU是一種ASIC芯片方案,是一種專為某種特定應(yīng)用需求而定制的芯片。第一代谷歌僅用于深度學(xué)習(xí)推理,TPU采用了28nm工藝制造,功耗約為40W,主頻700MHz,同時,TPU通過PCIe Gen3 x16總線連接到主機(jī),實(shí)現(xiàn)了12.5GB/s的有效帶寬,平均比CPU/GPU快15倍到30倍,能耗比指標(biāo)更高達(dá)30到80倍TOPS/W,單組TPU 的浮點(diǎn)計(jì)算力達(dá) 180 Teraflops(萬億次每秒)。近日,谷歌推出其第五代TPU,可以通過采用400 TB/s互連來配置多達(dá)256個芯片。谷歌表示,在 256 個芯片配置下,INT8 的算力將達(dá)到 100 PetaOps。不過,通常,ASIC芯片的開發(fā)不僅需要花費(fèi)數(shù)年的時間,且研發(fā)成本也極高。也就不差錢的谷歌,能一次又一次延續(xù)過往輝煌。
過往算力主要圍繞超算場景,更依賴于CPU發(fā)揮,而隨著計(jì)算場景更多元化、計(jì)算應(yīng)用更復(fù)雜化之后,全球算力需求呈現(xiàn)出指數(shù)級增加,導(dǎo)致傳統(tǒng)計(jì)算方式已經(jīng)無法滿足新時代要求。在AI大算力時代的當(dāng)下,CPU+GPU異構(gòu)融合則是另一種思路,并正逐步成為主流。
事實(shí)上,AI的算力服務(wù)器基本都是采用CPU+GPU的模式,比如最典型的英偉達(dá)A100服務(wù)器,就配置了2顆CPU和8顆GPU,其中2顆CPU負(fù)責(zé)任務(wù)和數(shù)據(jù)調(diào)度,8顆GPU是真正負(fù)責(zé)模型訓(xùn)練計(jì)算的。再來看ChatGPT,它的“橫空出世”加速了算力發(fā)展。從公開的數(shù)據(jù)顯示,一代ChatGPT模型訓(xùn)練,只用了5GB的文本數(shù)據(jù);二代用來40GB;3.5代用了45TB。ChatGPT模型的本質(zhì)上是概率模型,這種模型的訓(xùn)練和推理,其實(shí)里面的每一步計(jì)算都不復(fù)雜,全都是最基礎(chǔ)的矩陣運(yùn)算,比如矩陣乘法、矩陣加法等。只是需要做的運(yùn)算量非常大。不過,他們相互之間并沒有前后順序的依賴,可以并發(fā)同時做。GPU就非常合適。一個GPU里有幾千個處理單元,簡單的問題重復(fù)做,很快就可以做完了。
RFV7RJ0tZCjfZE2W1Zdb0vaVTmWcTWNcZhKtx8nGGTiaopOfQ/640?wx_fmt=jpeg" data-type="jpeg" data-w="1080" data-index="4" src="http://www.xebio.com.cn/uploadfile/2023/0922/20230922123759672.jpg" _width="677px" crossorigin="anonymous" alt="圖片" data-fail="0" style=";padding: 0px;outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;vertical-align: bottom;height: auto !important;width: 677px !important;visibility: visible !important"/>
不過,算力不足、能效過低,是當(dāng)前人工智能硬件平臺面臨的兩大艱巨挑戰(zhàn)。李洪革老師在演講中表示:“提高芯片算力的關(guān)鍵在于系統(tǒng)設(shè)計(jì)和芯片加工。系統(tǒng)設(shè)計(jì),重在高性能微架構(gòu)和先進(jìn)算術(shù)運(yùn)算,芯片加工則有賴于先進(jìn)工藝制程和先進(jìn)封裝制備。”
下面,我們重點(diǎn)從系統(tǒng)設(shè)計(jì)的角度來談?wù)劊绾翁嵘?a href="http://www.xebio.com.cn/semi" target="_blank" class="keylink">芯片的算力。
從系統(tǒng)設(shè)計(jì)提升芯片算力
高性能微架構(gòu)
現(xiàn)在,無論是CPU還是GPU,采用的都是70年前的馮.諾伊曼體系架構(gòu)。馮諾依曼體系結(jié)構(gòu)是現(xiàn)代計(jì)算機(jī)的基礎(chǔ)。根據(jù)馮諾依曼體系,CPU的工作分為以下 5 個階段:取指令階段、指令譯碼階段、執(zhí)行指令階段、訪存取數(shù)和結(jié)果寫回。在該體系結(jié)構(gòu)下,程序和數(shù)據(jù)統(tǒng)一存儲,指令和數(shù)據(jù)需要從同一存儲空間存取,經(jīng)由同一總線傳輸,無法重疊執(zhí)行。
在馮諾依曼架構(gòu)中,計(jì)算和存儲功能分別由中央處理器和存儲器完成。計(jì)算機(jī)的 CPU 和存儲器是相互獨(dú)立發(fā)展的,
也就是CPU和內(nèi)存是在不同芯片上的,而它們之間的通信要通過總線來進(jìn)行。數(shù)據(jù)量少的時候沒問題,但一旦數(shù)據(jù)變多,總線本身就會擁擠成為瓶頸。而現(xiàn)在的GPU,并行處理能力越來越強(qiáng)。當(dāng)數(shù)據(jù)傳輸速度不夠時,就會限制算力的天花板, 嚴(yán)重影響目標(biāo)應(yīng)用程序的功率和性能。
前陣子,美國對中國GPU的限制,就是對芯片總線代寬和算力聯(lián)合做限制。所以英偉達(dá)在這個新規(guī)下,能對中國銷售的A800芯片,它的總線帶寬就必須從原來的A100的600GB每秒降低到400GB每秒,所以數(shù)據(jù)的傳輸代寬越來越成為GPU的瓶頸。
這也正是GPU當(dāng)前面臨的存儲墻瓶頸,即“存儲墻”與“功耗墻”瓶頸,嚴(yán)重制約了系統(tǒng)算力和能效的提升。業(yè)界很多也都在研究相關(guān)的解決方案,以實(shí)現(xiàn)更為有效的數(shù)據(jù)運(yùn)算和更大的數(shù)據(jù)吞吐量,其中“存算一體”被認(rèn)為是未來計(jì)算芯片的架構(gòu)趨勢。就是把之前集中存儲在外面的數(shù)據(jù)改為存在GPU的每個計(jì)算單元內(nèi),每個計(jì)算單元既負(fù)責(zé)存儲數(shù)據(jù),又負(fù)責(zé)數(shù)據(jù)計(jì)算。
存算一體芯片市場廣闊,目前,國內(nèi)外企業(yè)、科研院所紛紛布局。據(jù) Gartner 預(yù)測,全球內(nèi)存計(jì)算市場將以每年 22% 的速度持續(xù)增長,截至 2020 年底有望達(dá)到 130 億美元 。關(guān)于存算一體,我們不再詳細(xì)探討,后期,將再專門撰寫關(guān)于存算一體的主題文章。
先進(jìn)算術(shù)運(yùn)算
邏輯電路和算術(shù)電路是計(jì)算芯片的設(shè)計(jì)基礎(chǔ)。二進(jìn)制邏輯是目前數(shù)據(jù)計(jì)算、信息傳輸?shù)幕A(chǔ)。眾所周知,二進(jìn)制邏輯(布爾代數(shù))中,通常用0和1表示兩個變量值中的一個。在計(jì)算N*N維的矩陣乘法時,每計(jì)算一個矢量元素將需要N^2個加法和乘法!硬件實(shí)現(xiàn)受限于布爾邏輯(二進(jìn)制數(shù))和馮氏架構(gòu)代來的物理瓶頸,使得當(dāng)前的AI計(jì)算芯片在算力突破方面面臨極大的挑戰(zhàn)。。
為了減小二進(jìn)制計(jì)算的硬件資源消耗,一種有別于布爾邏輯的概率(邏輯)計(jì)算(Stochastic Computing,SC,或Stochastic Logic)在1967年由美國哈羅德標(biāo)準(zhǔn)電信實(shí)驗(yàn)B.Gaines和W.Poppe I baum提出,并詳細(xì)分析和說明概率計(jì)算。概率邏輯是基于單比特位的偽隨機(jī)序列的計(jì)算,其激活“1”的概率與激活函數(shù)與權(quán)重成正比。概率計(jì)算機(jī)中,算術(shù)運(yùn)算是借助于表示數(shù)據(jù)的邏輯電平的隨機(jī)和不相關(guān)性來執(zhí)行的,并且由其“高電平”所占的概率來決定。也就是所發(fā)生的“高電平”脈沖的頻率表示其概率值。即遵循古典概型伯努利所證實(shí)的“當(dāng)試驗(yàn)次數(shù)愈來愈大時,頻率接近概率”。概率計(jì)算已經(jīng)在圖像處理、通信、神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)中被使用。
傳統(tǒng)概率計(jì)算的優(yōu)點(diǎn):電路邏輯簡單,極大減少電路面積,實(shí)現(xiàn)更高并行度;同等噪聲水平,可實(shí)現(xiàn)比二進(jìn)制更可靠的數(shù)值計(jì)算;在電路結(jié)構(gòu)不變,可動態(tài)調(diào)節(jié)計(jì)算準(zhǔn)確性和時間。然而,傳統(tǒng)概率也存在的明顯不足。如,實(shí)現(xiàn)二進(jìn)制數(shù)相同精度,概率脈沖長度需達(dá)到2n,時間消耗大幅增加;連續(xù)多次計(jì)算時,中途須轉(zhuǎn)換回二進(jìn)制再重新互斥編碼,降低計(jì)算效率。
北京航空航天大學(xué)教授李洪革老師在演講中談到:“盡管概率計(jì)算比二進(jìn)制計(jì)算存在硬件消耗上的巨大優(yōu)勢,但其基于脈沖頻率表示概率數(shù)值的本質(zhì)帶來了較大的計(jì)算時延的問題。”基于此,李洪革老師的研究團(tuán)隊(duì)提出了混合概率邏輯計(jì)算取代原始單比特流概率計(jì)算的思想。該方法利用多位流的期望值來取代傳統(tǒng)概率計(jì)算。
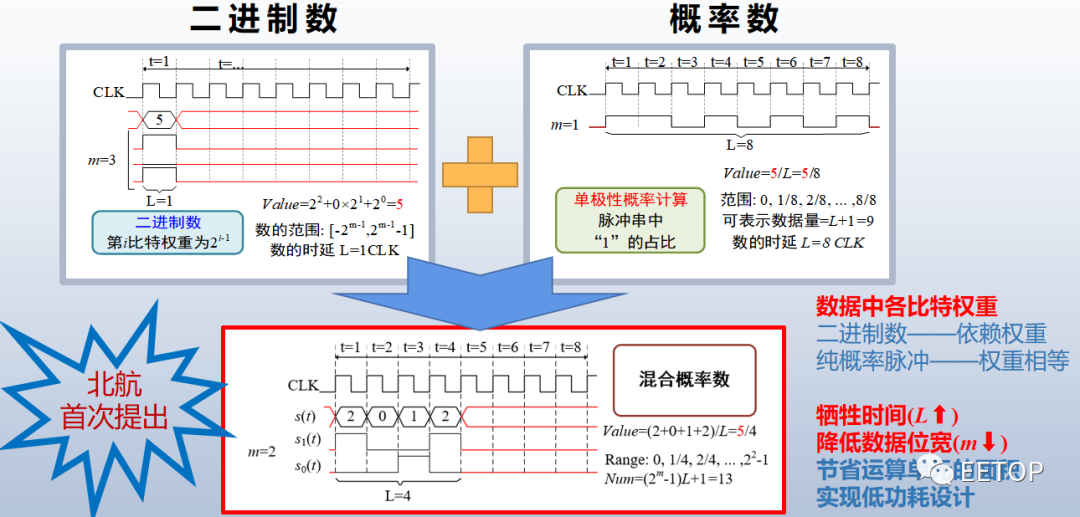
與傳統(tǒng)的單比特流相比,混合邏輯計(jì)算突破了傳統(tǒng)SC長時延的制約,實(shí)現(xiàn)了低時延和低面積。實(shí)驗(yàn)證明了混合邏輯計(jì)算規(guī)則的合理性,使用該方法乘法器延遲降低了1/2m,且達(dá)到零錯誤計(jì)算。對于8-bit輸入數(shù)據(jù),混合邏輯作為乘法器的面積效率是經(jīng)典SC方法的11.3倍。在2022年伊始,該思想被國際電路與系統(tǒng)頂會ISCAS和IEEE 權(quán)威期刊TVLSI等多位國際專家所認(rèn)可并全文接收。
結(jié)束語
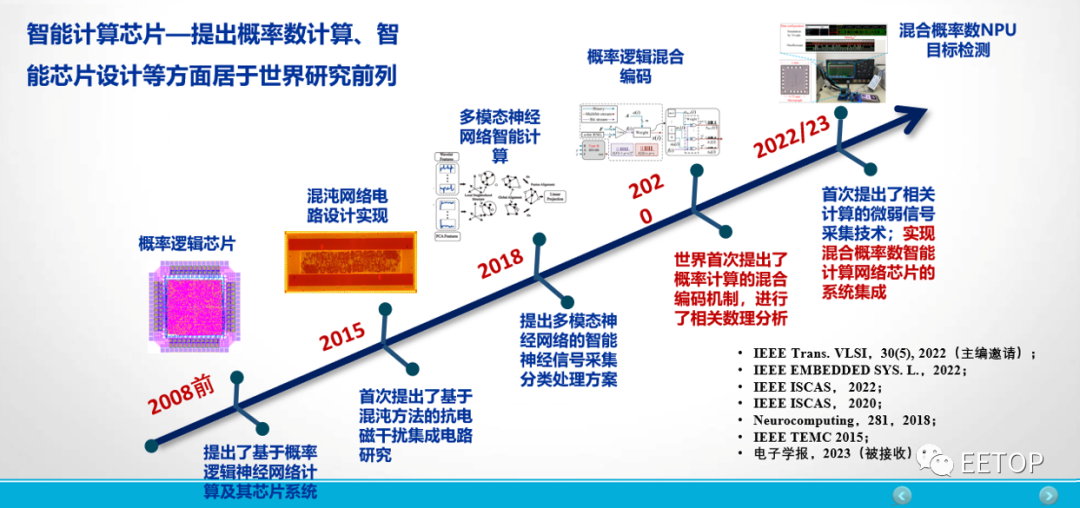
人類社會一直在孜孜不倦地追求對信息處理的計(jì)算能力的提升,ChatGPT的出現(xiàn)便是一個很好的案例。馮·諾依曼(Von Neumann)架構(gòu)計(jì)算機(jī)在某些特殊應(yīng)用場景中的局限性也逐步凸顯。類腦計(jì)算、概率計(jì)算等新興計(jì)算模式和結(jié)構(gòu)不斷涌現(xiàn),將滿足人工智能、數(shù)據(jù)中心等應(yīng)用對高負(fù)載、低能耗計(jì)算的需求,成為未來智能計(jì)算的突破口。
北京航空航天大學(xué)教授李洪革帶領(lǐng)的類腦芯片研究團(tuán)隊(duì)提出:“類腦芯片如果還是按照二進(jìn)制數(shù)來實(shí)現(xiàn),那么可能勢必?cái)[脫不了GPU、CPU本身對數(shù)進(jìn)行定義的局限性。能否轉(zhuǎn)換思維,將片上運(yùn)算轉(zhuǎn)換成非二進(jìn)制數(shù),即基于脈沖序列來表示的數(shù)—即概率脈沖數(shù)。”據(jù)了解,目前,該研究團(tuán)隊(duì)已經(jīng)實(shí)現(xiàn)了混合概率計(jì)算類腦脈沖神經(jīng)網(wǎng)絡(luò)芯片的設(shè)計(jì)、測試和應(yīng)用。期待在李洪革老師的帶領(lǐng)下,能為國產(chǎn)計(jì)算芯片的發(fā)展帶來革新,并成為未來智能計(jì)算的突破口。

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章