RISC-V 加速芯片,496核!RTL開源!
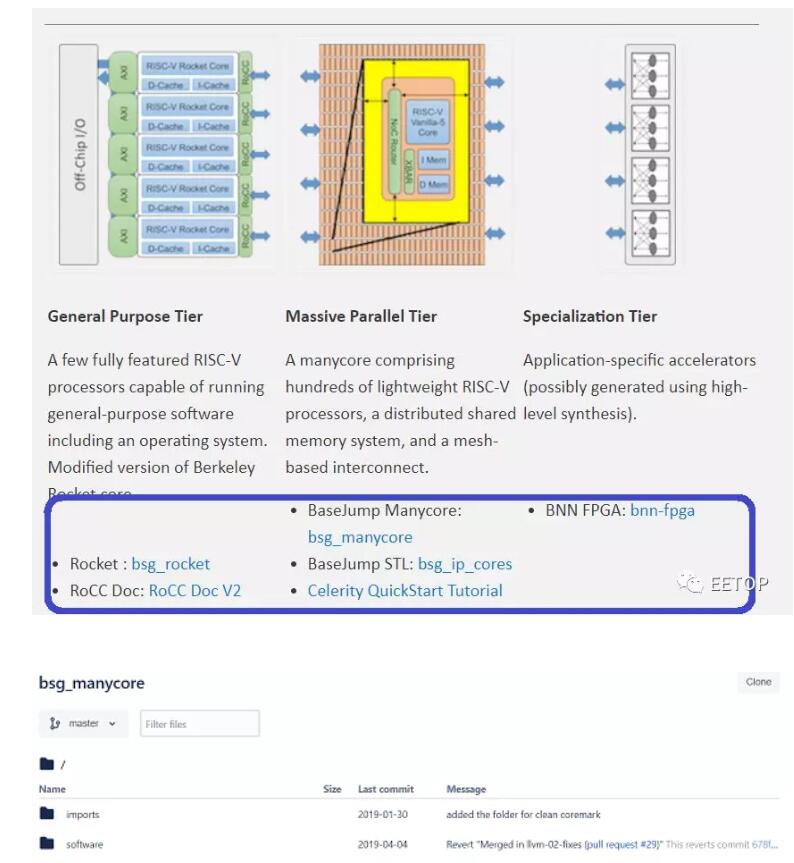
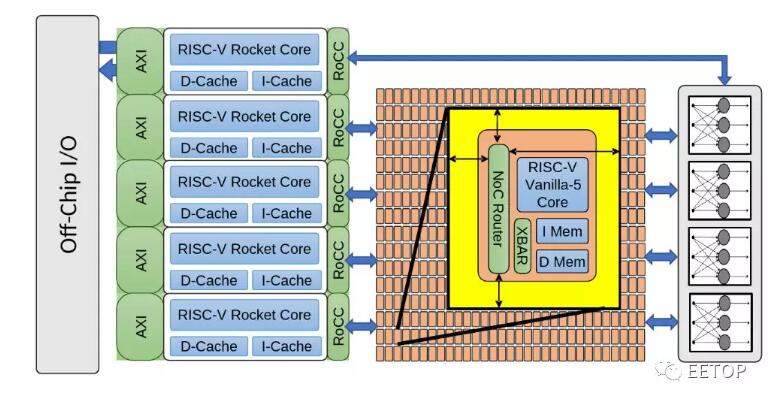
2020-01-13 13:13:40 wikichip接下來先對整個CeleritySoC做一個快速概述,Celerity是一個多核多層的AI加速器。總體而言,該芯片包括三個主要層:通用層,大規模并行層和專用層。為什么要使用分層SoC?主要原因是為了在典型的CPU設計上實現高靈活性和更高的電源效率(盡管效率不及ASIC NPU)。通用層幾乎可以執行任何操作:通用計算、內存管理以及控制芯片的其余部分。因此,他們集成了Free Chip Project的五個高性能亂序RISC-V Rocket內核。下一層是大規模并行層,它將496個低功耗定制設計的RISC-V內核集成到一個網格中。這些稱為Vanilla-5的自定義內核是有序標量內核,其占用的空間比Rocket內核少40倍。最后一層是集成二值神經網絡(BNN)加速器的專業化層。這三層都是緊密鏈接的,并與以400 MHz的DDR存儲器接口。
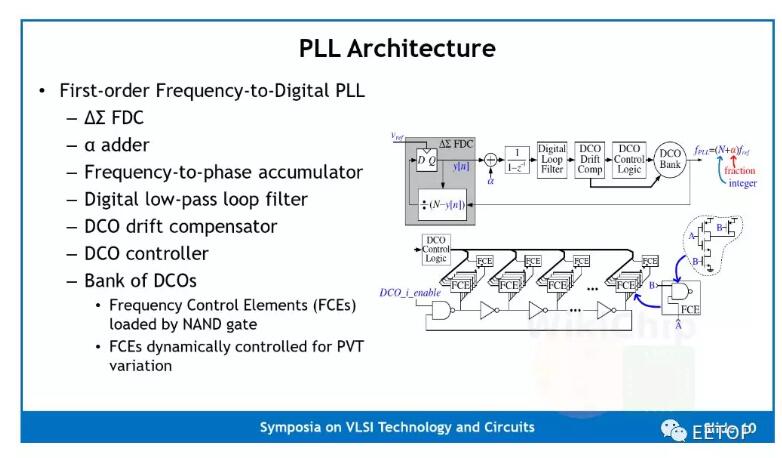
Celerity上的多核網絡(Manycore Mesh)時鐘由一個定制的鎖相環(PLL)提供。這是一個相當簡單的一階ΔΣ頻率數字轉換器(FDC)PLL。該實現單元采用16個DCO組成一個組,每個實現單元為環形振蕩器,其中反相元件加載有如下幻燈片上的電路圖所示的NAND門fce,如以下幻燈片中的電路圖所示。這樣做是為了僅使用標準單元來實現整個設計。為此,整個數字PPL是一個完全綜合和自動放置和路由設計。該PLL在其16納米芯片上的頻率范圍為10 MHz至3.3GHz。
與許多學術項目一樣,硅面積也非常重要的,整個芯片為25平方毫米(5×5)。對于Celerity而言,許多關鍵的架構設計決策都以限制硅面積的需求為主導,這意味著降低了復雜性。Manycore本身是16乘31的Vanilla-5 RISC-V小型內核陣列。該陣列的第32行用于外部主機,該主機用于與芯片上的其他組件連接(例如,將消息/數據發送到Rocket核心進行最終處理)。整個網格為3.38毫米乘4.51毫米(15.24毫米²),約占整個芯片的61%。Vanilla-5核心是5級有序流水線RV32IM核心,因此它們支持整數和乘法擴展。硅芯片實現,這些內核能夠達到1.4 GHz,比他們在Hot Chips 29上展示的第一個硅芯片高350 MHz。
為了降低多核陣列的復雜性,Celerity利用分區的全局地址空間進行單芯片數據包和遠程存儲編程模型。

該陣列利用了全局分區地址空間(GPAS)。換句話說,不是使用高速緩存,而是使用32位地址方案將整個內存地址空間映射到網絡中的所有節點上。這種方法也意味著無需虛擬化或轉換,從而大大簡化了設計。他們聲稱,與等效的一致性緩存系統相比,該設計可將區域開銷降低20倍。值得指出的是,由于該多核陣列的目標工作負載是AI加速(相對于更通用的計算),因此它們可以采用顯式分區(explicitly partitione)的暫存器存儲方案,因為這些工作負載表現出高度并行的定義良好的獨立流模式。而且,對于這種類型的代碼,控制存儲器局部性的能力可能證明是非常有利的。陣列中的每個核都可以自由執行加載并存儲到任何本地地址,但是,它只能執行對遠程地址的存儲。沒有遠程負載意味著它們將路由器面積減少了10%,并且由于可以對遠程存儲進行流水線處理,因此可以防止流水線停頓。
這種遠程存儲編程模型方案允許他們使用兩個網絡,實現這一個數據網絡和credit網絡用于管理未完成的存儲。

如前所述,第32行用于外部主機。實際上,這意味著內存映射擴展到位于陣列底部的16個路由停靠點,允許消息進出多核陣列,到達芯片上的大核和其他外圍設備。
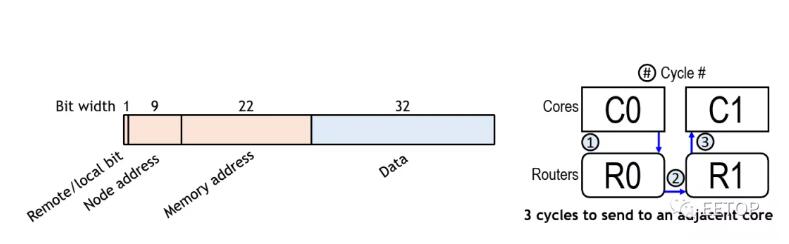
Celerity并沒有使用非常常見的wormholerouting(被Kilocore,Piton,Tile64等使用),而是將地址和數據合并到單個flit數據包中。該設計擺脫了發送數據和元數據都需要的頭/尾部信息。另外,由于沒有保留的路由,它擺脫了HOL阻塞。每個flit均為80b寬-控制位16位,數據位32位,節點地址位10位,存儲器地址位22位。flit節點地址保留了將數據發送到任何目的地的能力。該設計的主要好處是,由于僅將單個flit注入網絡,因此可以使用一個有序管道在每個周期中執行一個存儲。
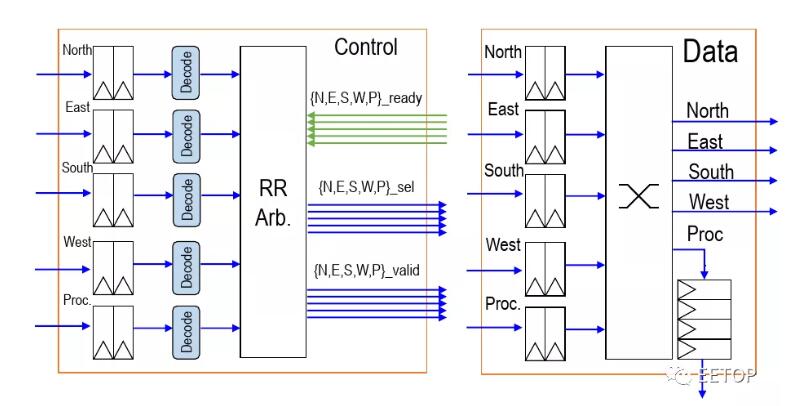
在多核陣列中的496個節點中,每個節點都有一個路由。路由本身在每個基本方向(N,S,E,W)的輸入處都包含兩個元素的FIFO,以及在網絡擁塞情況下用作臨時存儲的控制處理器。他們使用循環仲裁(round-robin arbitration)來確定數據包的優先級,從而可以在每個周期對每個方向進行仲裁(arbitrate )。他們使用尺寸順序的布線(在一個方向上減小偏移,然后再移動到另一方向)。通過簡單的設計,他們可以將整個路由實現為單級設計,而節點之間沒有管道寄存器。換句話說,每跳只需要一個周期。例如,任何相鄰的核心存儲區的延遲只有3個周期-轉到本地路由,跳到相鄰路由,最后去鄰居的記憶空間,路由器與內核位于相同的時鐘域,這意味著它們還可以在高達1.4 GHz的頻率下運行。
有兩個網絡-一個數據網絡和一個credit計數器網絡。該路由器使用一個受源代碼控制的credit計數器,每當一個遠程存儲包被注入網絡時,該計數器就會遞減。通過credit計數器網絡返回,該網絡使用與上面描述的數據相同的架構,但只有9位,因為它只包含節點地址。
那么,這些意味著什么呢?Celerity團隊報告了在600 mV至980 mV工作頻率從500 MH一直到1.4GHz。我們相信Celerity現在是時鐘頻率第二高的大學芯片,僅次于Kilocore(盡管值得指出的是,由于封裝方面的限制,Kiloecore只能支持其1000個內核中的160個)。在1.4 GHz時,整個網格的最大計算能力為694.4 INT 32 GOPS。他們以每秒Giga-RISC-V指令(GRVIS)而不是GOPS報告其數字,以便強調一個事實,即這些指令是完整的RISC-V指令,而不僅僅是整數運算。請注意,由于Vanilla-5內核是RV32IM,它們支持RISC-V整數和乘法擴展,但不支持浮點運算,因此所有AI工作負載都必須進行量化。由于將節點互連的路由器與核心位于相同的時鐘域,每個路由器每個周期支持5個flit,因此每個節點的總聚合帶寬為748Gbps,總聚合網絡帶寬為371Tb/s。
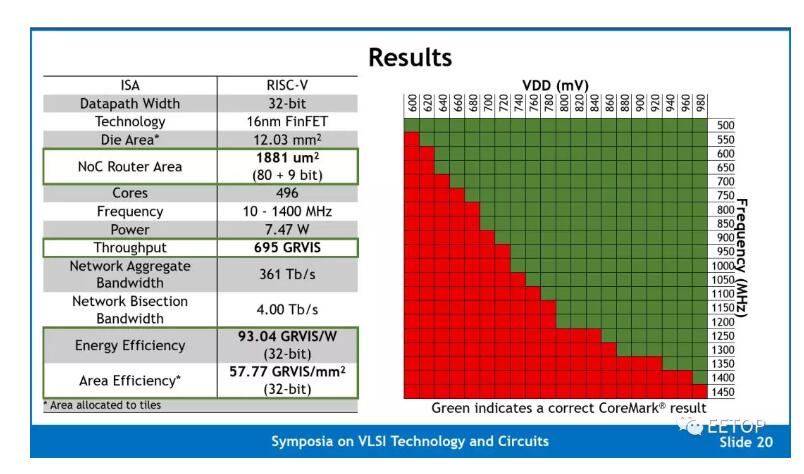
不幸的是,Celerity團隊沒有報告任何與人工智能相關的常見基準測試結果。相反,他們選擇使用CoreMark,當他們達到580.25 CoreMark /MHz時,總得分為812350。CoreMark在過去幾年中一直是RISC-V社區的比較基準。CoreMark的問題在于,它通常會為簡單的有序設計生成令人難以置信的樂觀分數,這些設計似乎能夠很好地與調優的現代無序設計競爭,而真實世界的工作負載則顯示出非常不同的結果。鑒于該芯片的前提是產生一個高度靈活的人工智能加速器,我們希望鼓勵Celerity團隊產生更有意義的結果,如正式的MLPerf提交。
Celerity的開源RTL設計已在Celerity網站公開(開源鏈接:http://opencelerity.org/),部分截屏如下: