微軟發(fā)布最輕量級大語言模型!可在CPU上高效運行
2025-04-18 11:42:24 EETOP微軟研究人員剛剛創(chuàng)建了 BitNet b1.58 2B4T,這是一個開源的 1 比特大語言模型(LLM),擁有 20 億個參數(shù),在 4 萬億個詞元上進行了訓(xùn)練。但這個人工智能模型的獨特之處在于它足夠輕量,可以在中央處理器(CPU)上高效運行,《科技創(chuàng)業(yè)》雜志稱蘋果 M2 芯片就能運行它。該模型在 Hugging Face 平臺上也可輕易獲取,任何人都能對其進行測試。
Bitnet 使用 1 比特權(quán)重,只有三種可能的值:-1、0 和 + 1 —— 從技術(shù)上講,由于支持三種值,它是一個 “1.58 比特模型” 。與采用 32 比特或 16 比特浮點格式的主流人工智能模型相比,這節(jié)省了大量內(nèi)存,使其運行效率更高,對內(nèi)存和計算能力的需求也更低。不過,Bitnet 的簡單性也有一個缺點 —— 與更大的人工智能模型相比,它的準確性較差。然而,BitNet b1.58 2B4T 憑借其龐大的訓(xùn)練數(shù)據(jù)彌補了這一點,據(jù)估計這些數(shù)據(jù)相當(dāng)于 3300 多萬本書。
這個輕量級模型背后的團隊將其與領(lǐng)先的主流模型進行了對比,包括 Meta 的 LLaMa 3.2 1B、谷歌的 Gemma 3 1B 和阿里巴巴的 Qwen 2.5 1.5B。在大多數(shù)測試中,BitNet b1.58 2B4T 與這些模型相比得分相對較高,甚至在一些基準測試中名列前茅。更重要的是,它在非嵌入式內(nèi)存中僅占用 400MB,不到第二小的模型(Gemma 3 1B,占用 1.4GB)的 30% 。
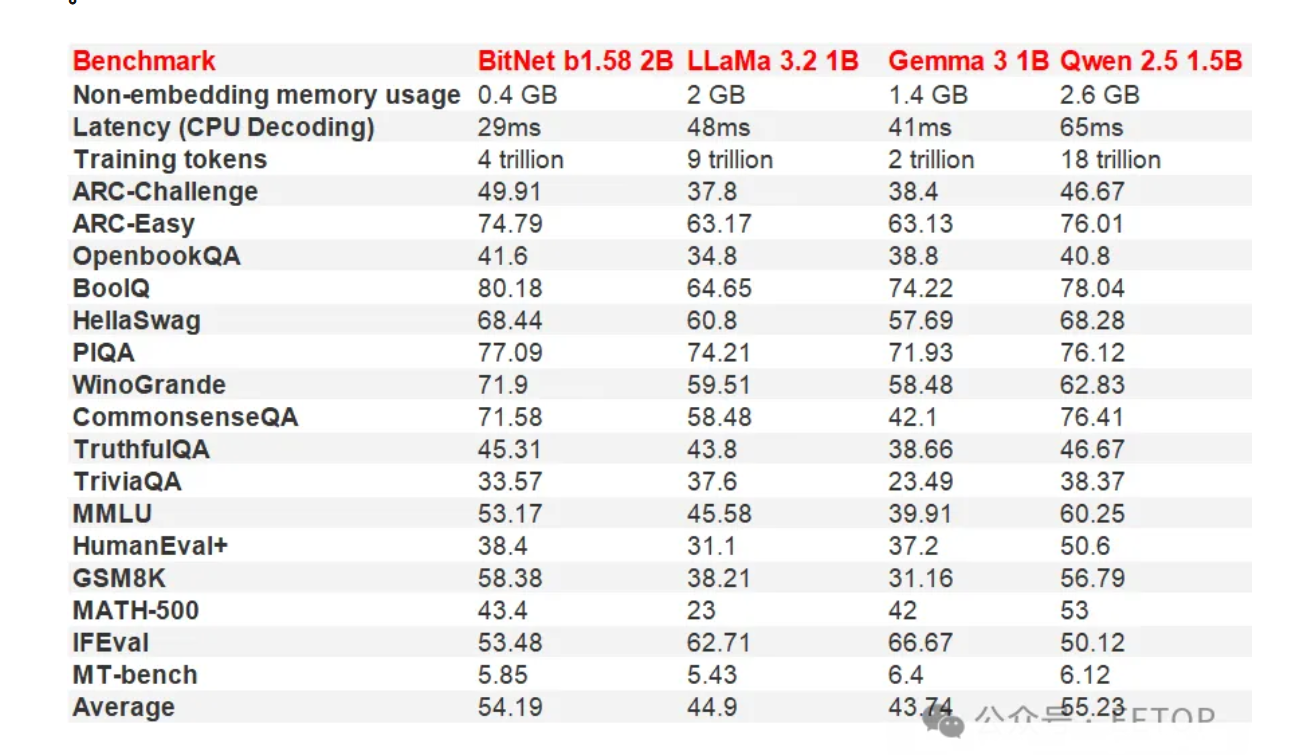
然而,這個大語言模型必須使用 bitnet.cpp 推理框架才能如此高效地運行。該團隊特別指出,“在使用標(biāo)準的 Transformer 庫時,即使是經(jīng)過必要修改的版本,這個模型也無法獲得性能效率提升” 。
如果你想在輕量級硬件上利用它的優(yōu)勢,就需要獲取 GitHub 上提供的該框架。該代碼庫稱 bitnet.cpp 提供了 “一套經(jīng)過優(yōu)化的內(nèi)核,支持在 CPU 上對 1.58 比特模型進行快速無損推理(接下來還將支持神經(jīng)網(wǎng)絡(luò)處理器和圖形處理器)” 。雖然目前它還不支持人工智能專用硬件,但它仍能讓任何擁有電腦的人在無需昂貴組件的情況下進行人工智能實驗。
人工智能模型常常因訓(xùn)練和運行時能耗過高而受到批評。但像 BitNet b1.58 2B4T 這樣的輕量級大語言模型可以幫助我們在性能較弱的硬件上本地運行人工智能模型。這可以減少我們對大型數(shù)據(jù)中心的依賴,甚至能讓那些沒有配備內(nèi)置神經(jīng)網(wǎng)絡(luò)處理器的最新處理器以及最強大圖形處理器的人也能使用人工智能。

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章