阿里云采用以太網取代英偉達NVlink,實現1.5萬個GPU互連!
2024-06-30 10:44:18 EETOP阿里云資深技術專家,網絡研究團隊負責人翟恩南通過GitHub分享了他的研究論文,揭示了阿里云服務提供商為其數據中心設計的用于大型語言模型(LLM)訓練的架構。這份PDF文檔題為《Alibaba HPN: A Data Center Network for Large Language Model Training》,詳細介紹了阿里巴巴如何使用以太網使其15,000個GPU之間實現相互通信。

一般的云計算產生的都是穩定但較小的數據流,速度低于10 Gbps。而LLM訓練則會周期性地產生高達400 Gbps的數據突發流量。根據該論文,這種LLM訓練的特點使得傳統數據中心常用的負載均衡方案——等價多路徑(ECMP)容易出現哈希極化問題,導致流量分配不均等問題。
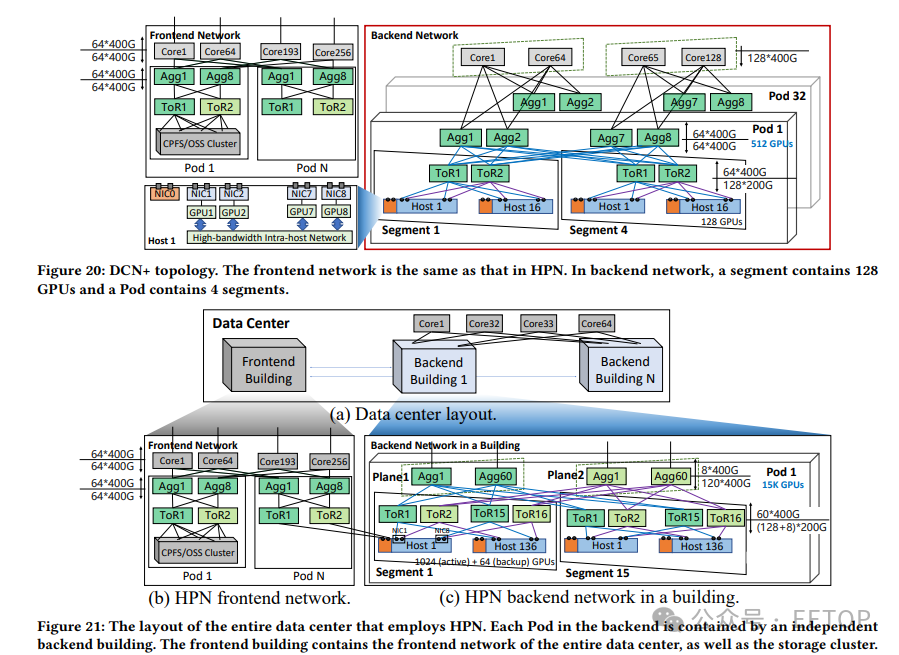
為避免這種情況,翟恩南和他的團隊開發了高性能網絡(HPN),采用了“2級雙平面架構”,減少了可能出現ECMP問題的次數,同時讓系統“能夠精確選擇能夠承載大流量的網絡路徑”。HPN還使用了ToR(Top of Rack))交換機,使它們能夠相互備份。這些交換機是LLM訓練中最常見的單點故障,需要GPU同步完成迭代。
阿里云將其數據中心劃分為主機,每個主機配備八個GPU。每個GPU都有其網絡接口卡(NIC),配備兩個端口,每個GPU-NIC系統稱為通道(rail)。主機還配備一個額外的NIC以連接到后端網絡。每個通道分別連接到兩個不同的ToR交換機,確保即使一個交換機故障也不會影響整個主機。
盡管放棄了用于主機間通信的NVlink,阿里云仍然在主機內網絡中使用了Nvidia的專有技術,因為主機內GPU之間的通信需要更大的帶寬。然而,由于通道之間的通信速度較慢,每歌主機提供的“專用400 Gbps RDMA網絡吞吐量,總帶寬達到3.2 Tbps”,足以最大化PCIe Gen5x16顯卡的帶寬。
阿里云還使用了一款51.2 Tb/sec的以太網單芯片ToR交換機,因為多芯片解決方案比單芯片交換機不穩定,故障率高四倍。然而,這些交換機運行時發熱量大,市面上沒有合適的散熱器能防止它們因過熱而關閉。因此,阿里自創了一種新的解決方案,即創建一個以更多支柱為中心的均熱板散熱器,以更有效地傳輸熱能。
翟恩南和他的團隊將在今年8月于澳大利亞悉尼舉行的SIGCOMM(數據通信特別興趣小組)會議上展示他們的工作。包括AMD、Intel、Google和Microsoft在內的多家公司都對這個項目感興趣,主要原因是這些公司聯手創建了Ultra Accelerator Link——一種旨在與NVlink競爭的開放標準互連集成系統。尤其是阿里云已經使用HPN超過八個月,這意味著該技術已經經過了實際驗證。
然而,HPN仍存在一些缺點,最大的缺點是其復雜的布線結構。每個主機有九個NIC,每個NIC連接到兩個不同的ToR交換機,這增加了插孔和端口混淆的可能性。盡管如此,這項技術據稱比NVlink更經濟,從而使任何建立數據中心的機構都能在設置成本上節省大量資金(甚至可能使其避免使用Nvidia技術,特別是在中美芯片戰中受到制裁的公司)。