英特爾全新Gaudi2處理器,為中國算力最大化釋放AI價值
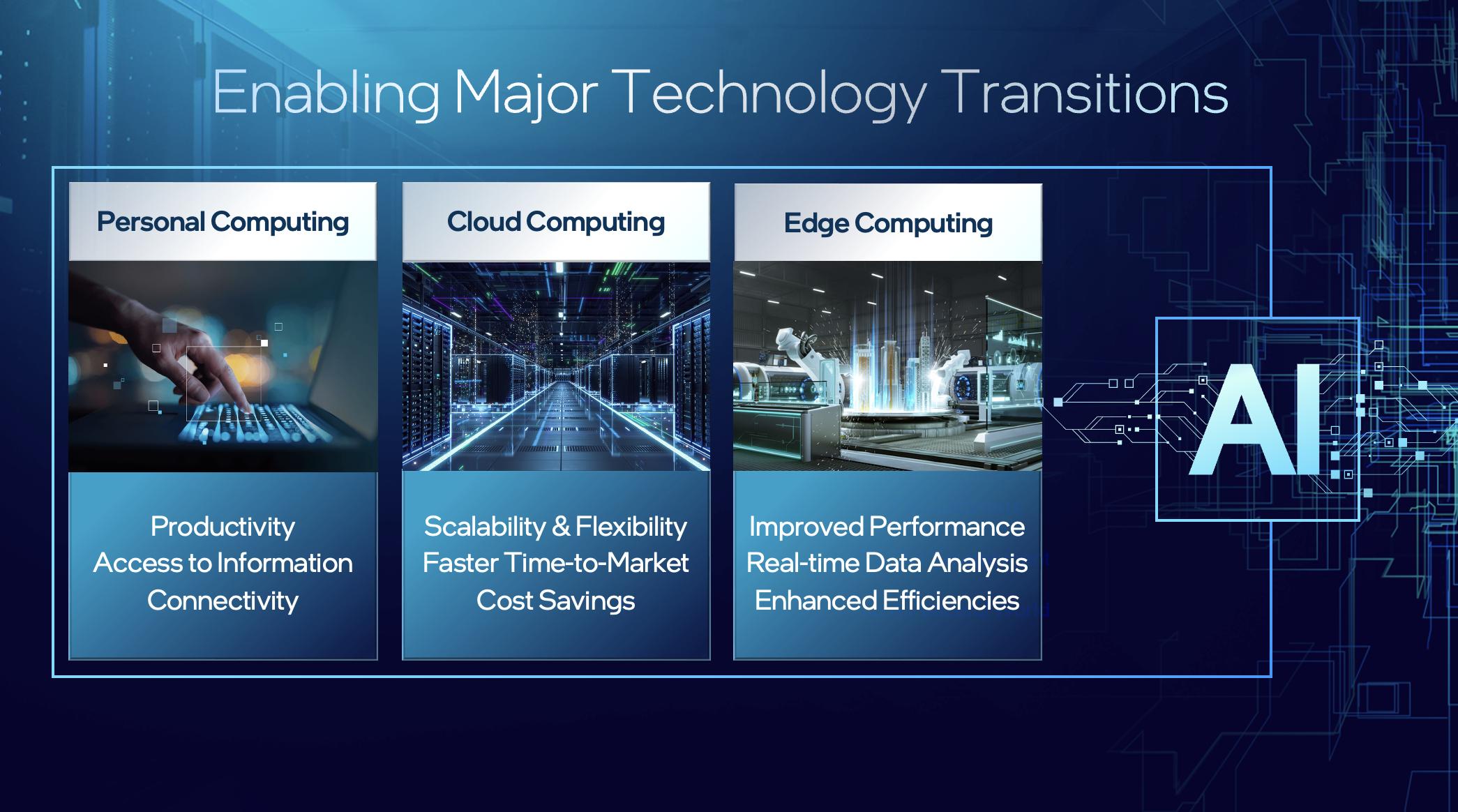
2023-07-13 12:36:34 EETOP2023年7月11日,EETOP應邀出席英特爾在北京金隅喜來登大酒店舉行的全新Gaudi2處理器發布會。回顧以往,英特爾助力推動了PC在中國的普及率,帶動了國內生產力的大力飛躍。在當今的信息化大數據模型時代,英特爾正在著力推進邊緣計算的增長,讓智能計算更靠近生成數據的邊緣。
英特爾正在利用自身的行業領先優勢,助力人工智能在中國的全面綻放,將海量數據轉變為可行洞察,實現無處不在的智能,以便充分發掘數據的價值。
人工智能(AI)是一項存在已有40多年的技術,在過去十年間,人們見證了一些令人矚目的進展。近期火爆的生成式AI和LLM(大規模語言模型)極大地加速了AI的發展,并衍生出了諸多計算需求。生成式AI和LLMs使機器能夠通過跟蹤順序數據(如句子中的單詞)中的關系來學習上下文及其含義。
去年,當OpenAI發布了ChatGPT后,它成為最快達到1億用戶的應用程序,并迅速改變了世界。生成式AI和LLMs不僅進一步挖掘AI的潛力,也促使英特爾開始以不同的方式看待計算,以便以最具成本效益的方式部署這項技術。
AI的數據流包括廣泛而復雜的工作負載和多模態數據集。而面對AI的計算需求,并沒有一種通用的解決方案。如今,很大一部分AI工作負載是在通用處理器上運行,這也受多重技術和經濟因素影響。通用處理器廣泛應用于數據攝取階段和經典機器學習中,用于訓練中小型模型。x86架構的大規模普及和其內置的AI能力使通用處理器已經成為解決AI數據流的理想解決方案。

當今,人們對于像生成式AI這樣的LLMs的深度學習訓練非常關注。如英特爾Gaudi深度學習加速器和GPU等的加速計算解決方案在這方面被廣泛應用。然而,最大的增長動力是AI的優化和部署。這正是通用處理器如內置AI加速器的英特爾至強可擴展處理器的應用領域。英特爾已經優化了基于至強的推理平臺,以便在云、網絡或智能邊緣部署多樣化的AI應用程序。
英特爾致力于讓客戶更易于在計算發生的任何地方部署AI。其中,我們在第四代英特爾至強可擴展處理器中集成AI加速器。第四代英特爾至強可擴展處理器最重要的特性之一,是新的AMX人工智能加速引擎,與上一代相比,它可以提供高達10倍的人工智能推理和訓練性能提升。AMX擴大了能夠在Xeon上運行的人工智能工作負載范圍,而無需額外的離散加速器。
內置AMX加速器等創新技術,第四代至強能夠支持大多數大型AI模型,包括實時、中等吞吐量、低延遲稀疏推理,以及中、小型規模的訓練和邊緣推理。此外,英特爾還通過廣泛的生態系統、專用于簡化流程的軟件工具以及優化的編譯器,讓客戶能夠更輕松地部署我們的解決方案。同時,借助oneAPI和OpenVINO,我們通過提供易于編程,且可在英特爾硬件上擴展的上游優化庫,為開發人員提供了使用硬件架構的開放性和可選擇性,即可在多種架構上使用一個代碼庫。
英特爾對于更高級別軟件堆棧的投入,幫助開發者更輕松地使用他們所熟悉的AI框架,例如Pytorch、TensorFlow和DeepSpeed。在與開放的生態系統合作擴展技術方面久經考驗,Intel致力于通過對開發者生態系統、工具、技術和開放平臺的長期投入,使得這一在AI領域內的公司傳統得以延續。所有這些工作,使客戶能夠在其基礎設施中已有的通用處理器上,輕松部署AI。
英特爾面向中國市場推出Gaudi2
Gaudi2旨在滿足越來越多的大語言模型的計算需求,例如生成式人工智能。對于在中國運行深度學習訓練和推理工作負載的客戶來說,與市場上其他面向大規模生成式AI和大語言模型的產品相比,Gaudi2是更理想的選擇。除了在性能表現上超過A100之外,Gaudi2在各種最先進的模型上相對于A100提供了約2倍的性價比。Gaudi2首先將通過我們的合作伙伴浪潮信息向中國客戶提供。
英特爾在中國打造基于Gaudi2的大規模集群。并且正在加大投資力度,以進一步擴展對大規模語言模型的AI軟件開發支持。同時在世界其他地區已經建立了類似基于Gaudi2的集群,并實現了97%的規模效率,這意味著從1個節點到512個節點的性能擴展幾乎沒有對性能產生影響。

Sandra Rivera,英特爾公司執行副總裁 數據中心與人工智能事業部總經理
這些集群將作為英特爾開發者云的一部分向中國客戶提供,并為開發人員提供一個地方,在這里他們可以分析和優化從小型到大型的新興AI工作負載,而無需昂貴的硬件成本。

生成式AI和LLM的計算需求需要大規模的擴展,這些MLPerf的結果有力地證明了Gaudi2系統出色的可擴展性和由此帶來的成本效率提升。
Gaudi2實現了全方位的能效比提升。(如下為性能每瓦的指標,數值越高越好。)對于訓練計算機視覺模型,Gaudi2的每瓦性能是A100的2倍,對于176B參數的BLOOMZ推理,其每瓦性能是A100的60%。這一優勢使客戶能夠顯著降低在數據中心運行深度學習工作負載的能效和環境資源成本。
另一個推動效率的因素是易用性。英特爾致力于支持客戶輕松構建新模型,以及將當前基于GPU的模型業務和系統遷移到全新Gaudi服務器。基于此,英特爾打造了針對Gaudi平臺深度學習訓練和推理優化的SynapseAI?軟件套件:
- 其集成PyTorch、TensorFlow、DeepSpeed框架;支持Kubernetes編排;定制編譯器。
- 現階段,其也擁有持續強大的軟件合作伙伴生態系統:Hugging Face、PyTorch Lightning、RedHat
其中,在超過5萬個模型在Hugging Face平臺上使用Optimum Habana軟件庫進行了優化:
- 通過我們的開發者網站提供支持,如文檔、參考模型、工具、操作指南等
- 進行網絡研討會、教程和實踐研討會

幾十年來,英特爾一直致力于為中國市場提供領先的數據中心創新,并堅定地致力于與大家一起推動人工智能時代的成功。同時通過基于標準的異構產品組合為客戶提供經濟高效的解決方案,使他們能夠在任何地方部署人工智能。
英特爾將繼續致力于用Xeon處理器構建一個通用計算的開放生態系統,該處理器具有內置AI加速器AMX、Gaudi2深度學習加速器的離散加速以及具有易于編程軟件的可擴展系統。Intel期待與中國的合作伙伴一起建設未來,在人工智能的前沿進行創新。






















