一張晶圓只做一顆芯片!中國科學家發表論文——大芯片:挑戰、模型和架構
2024-01-05 12:10:34 EETOP中國科學院計算技術研究所的研究人員剛剛在《Fundamental Research》雜志上發表了一篇論文討論了光刻和小芯片的局限性,并提出了一種他們稱之為“大芯片”的架構,該架構模仿了不幸的晶圓級Trilogy Systems 在 20 世紀 80 年代的努力以及Cerebras Systems 在 2019年推出成功的晶圓級架構。
(https://www.sciencedirect.com/science/article/pii/S2667325823003709)

我們知道埃隆·馬斯克(Elon Musk) 的特斯拉正在打造自己的“Dojo”超級計算機芯片,但這不是晶圓級設計,而是將Dojo D1 核心復雜地封裝成某種東西,如果你瞇著眼睛看,它看起來就像是由 360 個小芯片構建的晶圓級插槽。也許通過 Dojo2 芯片,特斯拉將轉向真正的晶圓級設計。看起來并不需要做很多工作就能完成這樣的壯舉。
中國科學院的這篇論文討論了很多關于為什么需要開發晶圓級器件的問題,但沒有提供太多關于他們開發的大芯片架構實際上是什么樣子的細節。它并沒有表明 Big Chip 是否會像特斯拉對 Dojo 那樣采用小芯片方法,或者像 Cerebras 從一開始就一路向晶圓級發展。
據中科院研究人員介紹,名為“浙江”的大芯片實施將在22 納米工藝。
“浙江”大芯片由 16 個小芯片組成,每個小芯片有 16 個RISC-V 內核。研究人員表示,該設計能夠在單個分立器件中擴展至100 個小芯片,我們過去稱之為插槽,但對我們來說聽起來更像是系統板。目前尚不清楚這 100 個小芯片將如何配置,也不清楚這些小芯片將實現什么樣的內存架構(陣列中將有 1,600 個內核)。
我們所知道的是,隨著“浙江”大芯片迭代,有 16 個RISC-V 處理器使用芯片上的網絡在共享主內存上進行對稱多處理,相互連接,并且小芯片之間有 SMP 鏈接,因此每個塊可以在整個復合體中共享內存。
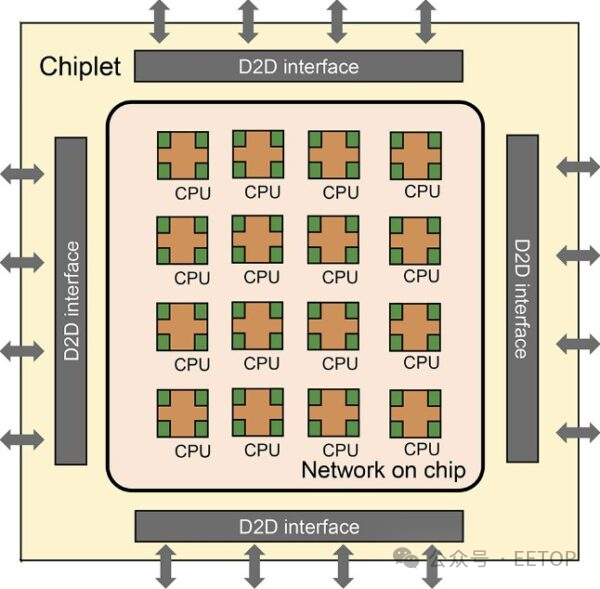
以下是如何使用中介層將 16 個小芯片捆綁在一起形成具有共享內存的 256 核計算復合體,從而實現芯片間 (D2D) 互連:
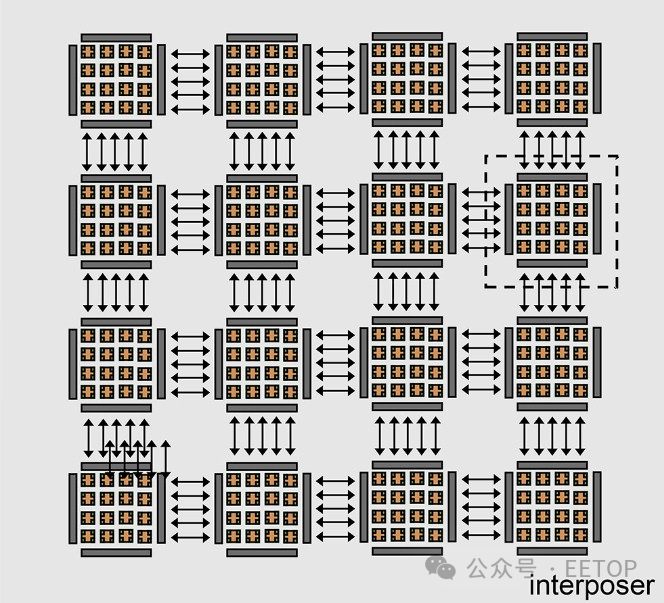
中科院研究人員表示,絕對沒有什么可以阻止這種小芯片設計以晶圓級實現。然而,對于這次迭代,看起來它將是使用 2.5D 中介層互連的小芯片。
互連與計算元件一樣重要,這在系統和子系統設計中始終如此。
“該接口是使用基于時間復用機制的通道共享技術設計的,”研究人員在談到D2D 互連時寫道。“這種方法減少了芯片間信號的數量,從而最大限度地減少了 I/O 凸塊和內插器布線資源的面積開銷,從而可以顯著降低基板設計的復雜性。小芯片終止于頂部金屬層,微型 I/O 焊盤就建在該金屬層上。”
雖然一個大芯片計算引擎作為多芯片或晶圓級復合體可能很有趣,但重要的是如何將這些設備互連以提供百億億級計算系統。以下是中科院研究人員對此的看法:
“對于當前和未來的超大規模計算,我們預測分層芯片架構是一種強大而靈活的解決方案,”研究人員在描述這種計算和內存的分層結構時寫道,如下圖所示,這是中科院論文的一段冗長引文。“分層小芯片架構被設計為具有多個內核和許多具有分層互連的小芯片。在chiplet內部,內核使用超低延遲互連進行通信,而chiplet之間則以得益于先進封裝技術的低延遲互連,從而在這種高可擴展性系統中實現片上延遲和NUMA效應可以最小化。存儲器層次結構包含核心存儲器、片內存儲器和片外存儲器。這三個級別的內存在內存帶寬、延遲、功耗和成本方面有所不同。在分層chiplet架構的概述中,多個核心通過交叉交換機連接并共享緩存。這就形成了一個pod結構,并且pod通過chiplet內網絡互連。多個pod形成一個chiplet,chiplet通過chiplet間網絡互連,然后連接到片外存儲器。需要仔細設計才能充分利用這種層次結構。合理利用內存帶寬來平衡不同計算層次的工作負載可以顯著提高chiplet系統效率。正確設計通信網絡資源可以確保小芯片協同執行共享內存任務。”
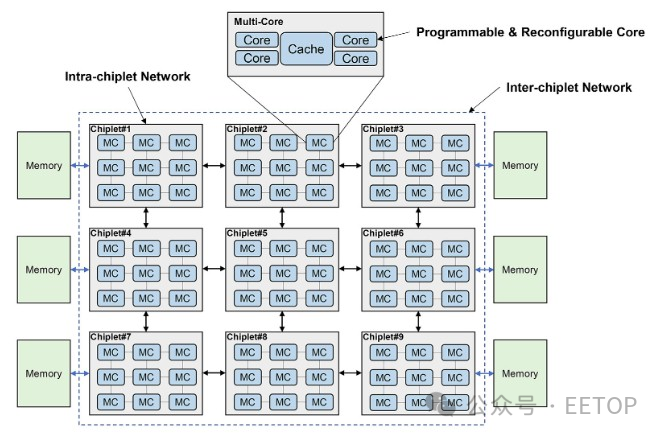
很難反駁這句話中所說的任何內容,但 中科院 研究人員并沒有說明他們將如何實際處理這些問題。這是最困難的部分。
有趣的是,該圖中的內核被稱為“可編程”和“可重新配置”,但我們不確定這意味著什么。它可能需要使用可變線程技術(例如 IBM 的Power8、Power9 和 Power10 處理器)來完成更多工作,而不是在核心中混合使用 CPU 和FPGA 元件。
中科院研究人員表示,大芯片計算引擎將由超過 1 萬億個晶體管組成,占據數千平方毫米的總面積,采用小芯片封裝或計算和存儲塊的晶圓級集成。對于百億億次 HPC 和 AI 工作負載,我們認為中科院很可能正在考慮 HBM 堆疊DRAM 或其他一些替代double-pumped主內存,例如英特爾和 SK Hynix 開發的MCR 內存。RISV-V 內核可能會有大量本地 SRAM 進行計算,這可能會消除對 HBM 內存的需求,并允許使用 MCR double-pumped技術加速 DDR5 內存。很大程度上取決于工作負載以及它們對內存容量和內存帶寬的敏感程度。
Big Chip 論文列出了一份未來技術的愿望清單,例如光電計算、近內存計算以及可以添加到 Big Chip 復合體中的3D 堆棧式緩存和主內存 - 看起來像是使用光學 I /O 處理器是首選。但并未透露其正在研究的內容以及何時可以交付。
本文由EETOP綜合整理編譯自nextplatform
關鍵詞: Cerebras