被Armv9 重點引入的SVE2是何方神圣?
2021-04-06 12:10:34 EETOP編譯整理3月30日,Arm召開了最新架構Armv9的發布會,并展示了SVE的高級形式“ SVE2”的存在。
在Armv9發布時,Arm發布了《SVE2簡介》,從這本白皮書中我們可以大概了解一下SVE2。
可伸縮矢量擴展-SVE(Scalable Vector Extension)是Arm AArch64架構下的下一代SIMD指令集,旨在加速高性能計算。
而SVE2本質上是SVE的擴展,但是最初的SVE是針對HPC的(因此第一個實現是富士通的A64FX),而SVE2實現了NEON兼容的指令。從某種意義上說,最大的不同是它被定位為NEON的后繼產品(Photo01)。

Photo01:正如我將在后面詳細解釋的那樣,它比SVE更易于使用。
Photo02展示了SVE2的主要功能,SVE是為HPC設計的,從某種意義上說,配置上已經完全放棄了對NEON的兼容,但是SVE2是非常接近NEON的配置。

Photo02:顯示了指令的預期用途。
同時,與SVE相比,它可以實現靈活的數據訪問,并可用于廣泛的應用。雖然考慮到要維持對SVE的向后兼容性,但是只有ID 寄存器需要變更,反過來說只要對應就可以了。藍色標記的功能是NEON或SVE提供的功能。例如,在“ NEON型DSP指令”的情況下,它最初來自NEON一代。
這種處理方式原本是DSP的特長,這種指令被稱為DSP式的 "指令",但已經被原封不動地接管了。但是,究竟是指令本身兼容,還是編寫了具有相同功能的指令(指令本身不兼容),目前還不清楚。換句話說,目前還不清楚是否會包含類似DSP的 "機制",比如Helium中包含的Low Overhead Branch Extension。
“Cross-lane match detect/count”以后的特征主要是繼承自SVE。
新功能是與比特Bit shuffle和加密相關的指令。由于指令集列表尚未發布(當前僅是SVE),所以目前還不是很清楚,但是看起來它的配置與x86 SSE / AVX非常相似。
從NEON轉到這里有一個小障礙。是指將操作的結果做成不同大小時的對應關系(Photo03)。

Photo03:所以在NEON中使用這樣的用法的情況下,重寫起來有點麻煩也是沒辦法的事
NEON的寬度固定為128bit,而SVE/SVE2的最小單位為128bit,可擴展到2048bit寬度。仔細想想,NEON的方法也不是不可以,但是需要考慮一下。特別是可擴展性部分,很麻煩,需要根據SVE寄存器的大小,從程序上處理 "數據放在哪里"。與此相比,SVE方法具有可擴展性和易部署性。
這是NEON與128/256 / 512bit SVE(Photo04)之間的性能比較。
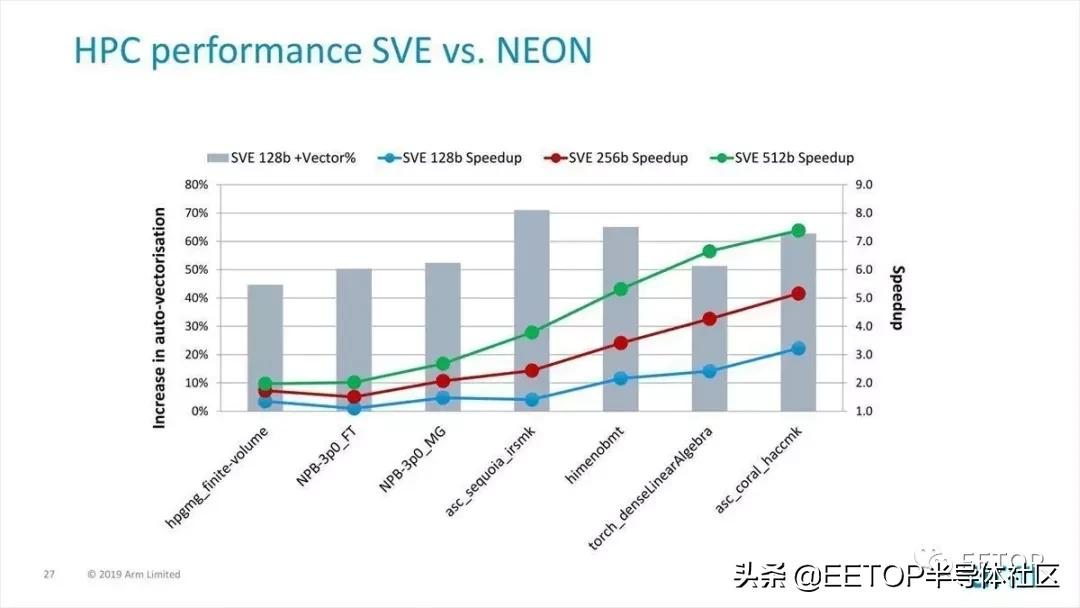
Photo04:柱狀圖(左軸)為矢量化率,折線(右軸)為性能比
這是之前在安藤教授的文章中出現的一張幻燈片,根據應用的不同,性能提升率自然也會發生變化,但差別還是蠻大的:在NAS Parallel Benchmark中提升了2倍,在ASC Coral HACC中提升了8倍。
那么SVE2呢? SVE2的性能與HPC的SVE相同(SVE2并沒有進一步提高性能),但DSP/多媒體的性能是128bit的1.2倍,256bit的2倍,512bit的3.5倍(Photo05)。
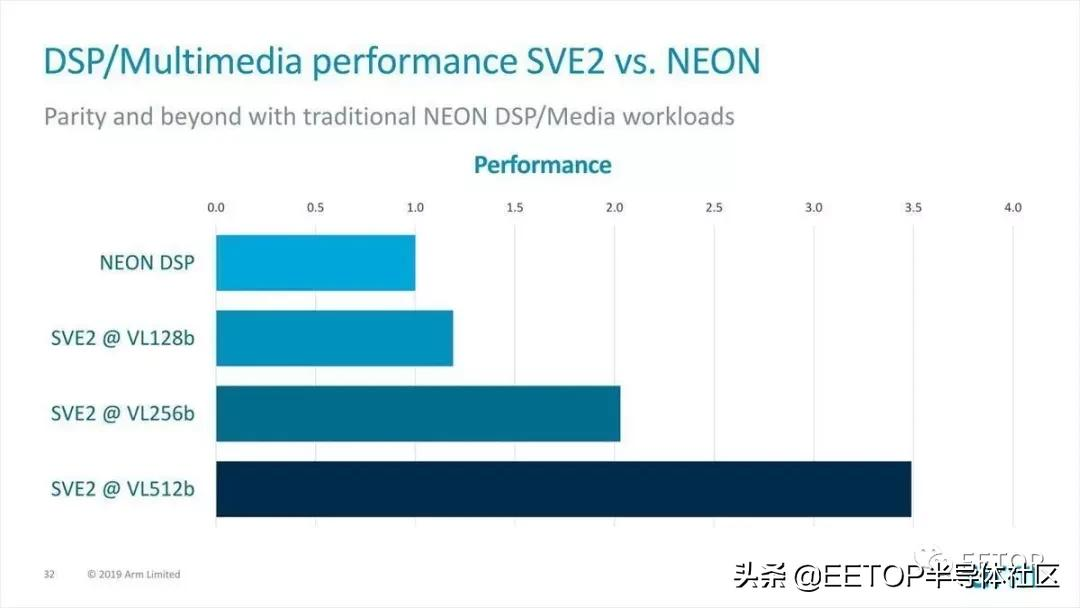
Photo05:即使使用相同的寬度(128位),速度也將快約1.2倍,但本質在于,它很容易加寬寬度并相應地加快速度。
Photo06是對范圍更廣的應用程序的比較。
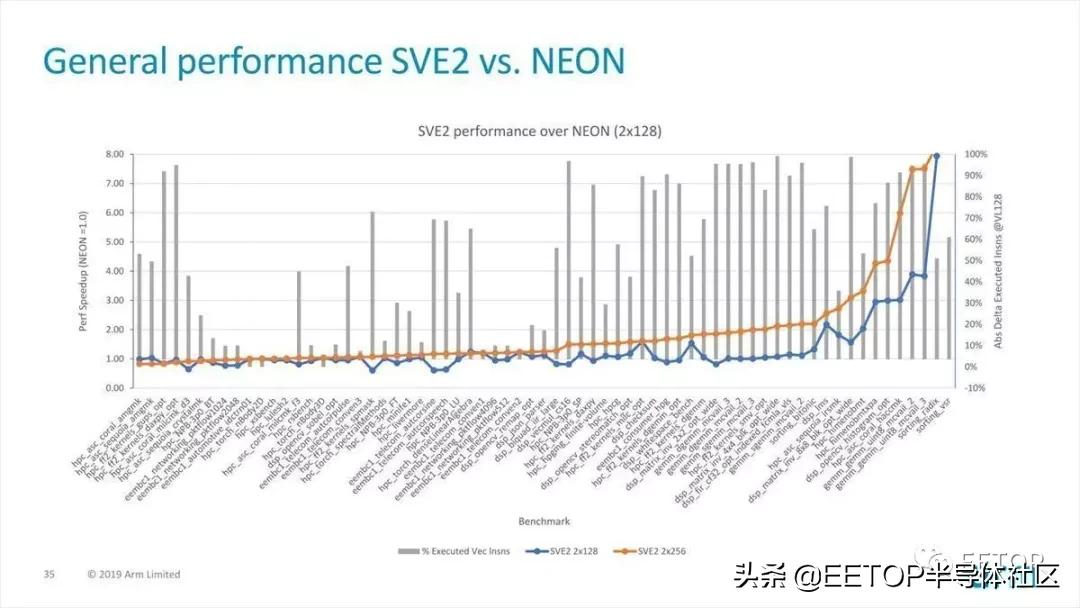
Photo06:與上面的Photo05一樣,豎線是矢量化率,折線是性能提高率。比較為NEON×2與128位SVE2×2與256位SVE2×2
如果矢量化效果不好(如eembc_automotive_idctrn01),性能與VNEON相差不大,但如果矢量化效果好,性能將大大提高。
順便說一句,除此以外,在Linano Connect Bangkok 2019上推出的“ Arm Architecture中的新技術”不僅包括SVE2,還包括筆者在此介紹的Transaction Memory(Photo07)。

Photo07:Arm本身還是只在少數CPU IP中支持多線程,但也有一些CPU支持4路SMT,比如Marvell(原Broadcom的)Thunder X2。內存被認為對同步這些處理器很有用。
首先,雖然對事務內存(Transaction Memory)的研究已經廣泛開展了一段時間,但IBM的POWER8是第一個在量產產品中實現的。接下來,英特爾在Haswell一代支持它為TSX(事務同步擴展),但以AMD為例,現在也不支持事務存儲。它不一定是一個廣泛使用的功能。
Arm目前還沒有宣布會支持這一功能,但據說將來的Arm處理器將支持它 (Photo07)。
在執行TME時,自然會假設有兩個或更多的線程會嘗試訪問相關的內存區域,因此在某些情況下可能無法建立事務(回滾)。其實現方式是將每個線程的狀態寫入狀態寄存器并返回(Photo09)。

Photo 08

Photo09
順便說一句,事務內存通常有兩種類型的方法,即HLE(硬件鎖定清除)和RTM(受限跨轉錄存儲),并且Intel支持這兩種方法,但是Arm似乎僅支持HLE(照片10)。

Photo10:不幸的是,沒有關于為什么不支持RTM的解釋
HLE和RTM之間的區別在Ando博士的評論中也有詳細介紹,因此,如果您閱讀此書,請查看用法示例(Photo 11),它與Intel的TSX盡可能接近。

Photo11:確切地說,這類似于將HLE與TSX一起使用
截至目前,Arm還沒有透露哪一代Arm內核將支持TME,但似乎不久之后LLVM和GNU Tools/Glibc就已經支持了。當然,在智能手機中使用TME的意義不大,所以我認為它只適用于Neoverse,但如果在不久的將來支持它,我不會感到驚訝。