?性能提高13倍、能耗降低10倍!谷歌DeepMind發(fā)表AI訓(xùn)練新方法
2024-07-08 11:46:12 EETOPDeepMind的方法被稱為JEST,即聯(lián)合樣本選擇(joint example selection),與傳統(tǒng)的AI模型訓(xùn)練技術(shù)截然不同。典型的訓(xùn)練方法專注于單個(gè)數(shù)據(jù)點(diǎn)進(jìn)行訓(xùn)練和學(xué)習(xí),而JEST則基于整個(gè)批次進(jìn)行訓(xùn)練。JEST方法首先創(chuàng)建一個(gè)較小的AI模型,用于從極高質(zhì)量的來源中評估數(shù)據(jù)質(zhì)量,并按質(zhì)量對批次進(jìn)行排名。然后,將這些評估結(jié)果與一個(gè)較大、質(zhì)量較低的數(shù)據(jù)集進(jìn)行比較。小型JEST模型確定最適合訓(xùn)練的批次,然后根據(jù)小模型的發(fā)現(xiàn)對大型模型進(jìn)行訓(xùn)練。
這篇論文(arxiv.org/pdf/2406.17711)對研究中使用的過程和研究的未來進(jìn)行了更全面的解釋。
DeepMind的研究人員在論文中明確指出,這種“引導(dǎo)數(shù)據(jù)選擇過程朝向較小、精心策劃的數(shù)據(jù)集的分布”的能力是JEST方法成功的關(guān)鍵。成功確實(shí)是對這項(xiàng)研究的恰當(dāng)描述;DeepMind聲稱,“我們的方法在迭代次數(shù)減少多達(dá)13倍和計(jì)算量減少多達(dá)10倍的情況下,超越了最先進(jìn)的模型。”
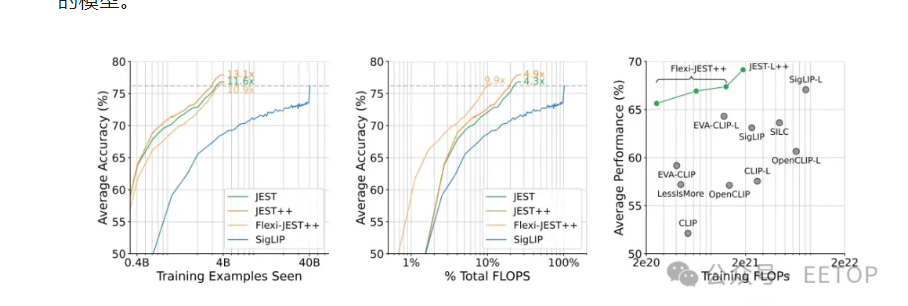
上圖顯示了 JEST 方法在速度和 FLOPS 效率方面如何超越 SigLIP(用于在圖像標(biāo)題對上訓(xùn)練模型的領(lǐng)先方法),以及與許多其他方法相比。(圖片來源:Google DeepMind、Evans 等)
當(dāng)然,這個(gè)系統(tǒng)完全依賴于其訓(xùn)練數(shù)據(jù)的質(zhì)量,因?yàn)槿绻麤]有高質(zhì)量的人為策劃的數(shù)據(jù)集,啟動技術(shù)將失效。對于這個(gè)方法來說,“垃圾進(jìn),垃圾出”這句箴言再合適不過了,它試圖在訓(xùn)練過程中“跳過”一些步驟。這使得JEST方法對于業(yè)余愛好者或業(yè)余AI開發(fā)者來說比大多數(shù)其他方法更難匹配,因?yàn)椴邉澇跏甲罡呒墑e訓(xùn)練數(shù)據(jù)可能需要專家級的研究技能。
JEST研究的出現(xiàn)恰逢其時(shí),因?yàn)榭萍夹袠I(yè)和世界各國政府正開始討論人工智能的極高電力需求。2023年,AI工作負(fù)載消耗了約4.3GW電力,幾乎與塞浦路斯的年電力消耗相當(dāng)。而且情況顯然沒有放緩的跡象:單個(gè)ChatGPT請求的電力成本是谷歌搜索的10倍,Arm的CEO估計(jì)到2030年AI將占據(jù)美國電網(wǎng)的四分之一。
是否以及如何在AI領(lǐng)域的大玩家中采用JEST方法還有待觀察。據(jù)報(bào)道,訓(xùn)練GPT-4花費(fèi)了1億美元,而未來更大的模型可能很快會達(dá)到十億美元的成本,因此各公司可能正在尋找方法以節(jié)省資金。希望JEST方法能夠在保持當(dāng)前訓(xùn)練生產(chǎn)率的同時(shí),大大降低電力消耗,降低AI成本,幫助地球。然而,更有可能的是,資本機(jī)器將繼續(xù)保持高速運(yùn)轉(zhuǎn),利用JEST方法在最大功率下進(jìn)行超快速訓(xùn)練輸出。成本節(jié)約與輸出規(guī)模相比,誰將勝出?
芯片精品課程推薦


EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章