?視覺轉換器挑戰加速器架構
2023-07-16 10:37:03 EETOP在快速發展的人工智能世界中,CNN 及其相關產品似乎很長一段時間以來一直在推動邊緣人工智能引擎架構的發展。雖然神經網絡算法的性質已經發生了重大變化,但它們都被認為可以在一個異構平臺上通過DNN的各層處理進行高效處理:一個NPU用于張量運算,一個DSP或GPU用于矢量運算,一個CPU(或集群)管理剩余的運算。
在視覺處理中,這種架構運行良好,因為在視覺處理中,矢量和標量類操作與張量層的交錯并不明顯。處理過程從規范化操作(灰度、幾何尺寸等)開始,由矢量處理高效處理。然后是一系列深度層,通過漸進的張量運算對圖像進行過濾。最后,一個類似于softmax的函數(同樣基于矢量)對輸出進行歸一化處理。這些算法和異構架構都是圍繞這種缺乏交錯的假定而設計的,所有重型智能都在張量引擎中無縫處理。
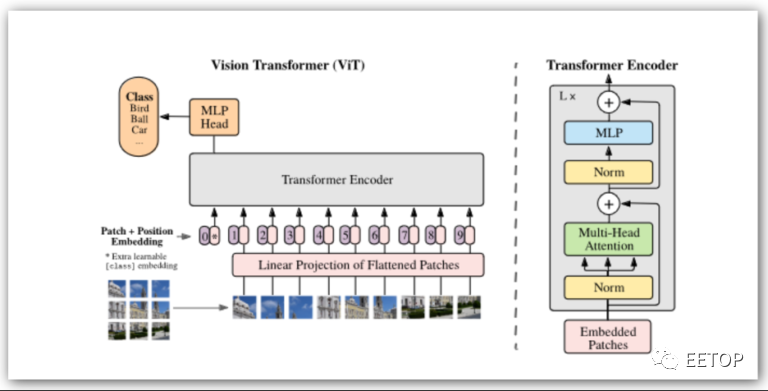
視覺轉換器 (Vision Transformers,簡稱ViT) 架構由 Google Research/Google Brain 于 2017 年發布,旨在解決自然語言處理 (NLP) 中的問題。CNN 及其同類通過串行處理局部注意力過濾器來發揮作用。圖層中的每個過濾器都會選擇局部特征 - 邊緣、紋理或類似特征。堆疊過濾器積累自下而上的識別結果,最終識別出更大的物體。
在自然語言中,句子中某個單詞的含義并不完全由句子中相鄰單詞決定;相距甚遠的單詞可能會對解釋產生關鍵影響。連續應用局部注意最終可以從遠處獲得權重,但這種影響會減弱。更好的方法是全局關注,即同時關注句子中的每個單詞,在這種情況下,距離并不是加權的因素,大型語言模型的顯著成功證明了這一點。
雖然 Transformer 在 GPT 和類似應用中最為人所知,但它們也在視覺 Transformer(稱為 ViT)中迅速普及。圖像以塊(例如 16×16 像素)的形式進行線性化,然后通過Transformer將其處理為字符串,并有充足的并行機會。對于每個序列,連續進行一系列張量和向量運算。無論Transformer支持多少個編碼器塊,都會重復此過程。
與傳統神經網絡模型的最大區別在于,這里的張量和矢量操作是大量交錯進行的。在異構加速器上運行這樣的算法是可能的,但在引擎之間頻繁切換上下文可能不會非常有效。
直接比較似乎表明,ViT能夠達到與CNNs/DNNs相當的精度水平,在某些情況下可能性能更好。然而,更有趣的是其他一些見解。ViT可能更偏重于對圖形拓撲結構的洞察,而不是自下而上的像素級識別,這可能是它們對圖像失真或黑客攻擊更穩健的原因。此外,目前還在積極開展ViT的自我監督訓練工作,這可以大大減少訓練工作量。
本文由EETOP編譯自semiwiki






















