頂級芯片大師、微處理器傳奇人物 Jim Keller 談:摩爾定律、計算機架構(gòu)、未來計算機技術(shù)發(fā)展趨勢
2020-04-16 12:44:18 老石談芯很多世界頂尖的“建筑師”可能是你從未聽說過的人,他們設(shè)計并創(chuàng)造出了很多你可能從未見過的神奇結(jié)構(gòu),比如在芯片內(nèi)部源于沙子的復(fù)雜體系。如果你使用手機、電腦,或者通過互聯(lián)網(wǎng)收發(fā)信息,那么你就無時無刻不在受益于這些建筑師們的偉大工作。
Jim Keller就是這群“建筑師”里的一員。作為微處理器領(lǐng)域的傳奇人物,他現(xiàn)任英特爾資深副總裁,兼任硅工程事業(yè)部(Silicon Engineering Group)的總經(jīng)理。在此之前,他曾任職DEC、AMD、博通、蘋果、特斯拉等公司,擔任工程副總裁或首席架構(gòu)師等工作。
在他幾十年的職業(yè)生涯中,他領(lǐng)導(dǎo)設(shè)計了多種x86和ARM的處理器架構(gòu),包括AMD的K7、K8、K12和Zen,蘋果用于iPhone4和iPad的A4、A5移動處理器,特斯拉的自動駕駛處理器,等等。此外,他還是x86-64指令集的作者之一。

Jim Keller,圖片來自英特爾
不久前,Jim Keller做客MIT的網(wǎng)紅學(xué)者Lex Fridman的播客節(jié)目,并分享了自己對于摩爾定律、計算機體系結(jié)構(gòu)、人工智能等技術(shù)問題的見解與思考。兩人的對談天馬行空,并不拘泥于某個具體技術(shù)或領(lǐng)域,而是由某個觀點出發(fā),討論技術(shù)背后的驅(qū)動因素,并對芯片與人工智能產(chǎn)業(yè)的發(fā)展和變革做了深入剖析,聽來讓人受益匪淺。
 Lex Fridman,圖片來自他的Twitter
Lex Fridman,圖片來自他的Twitter
老石對Jim Keller的主要觀點進行了整理和采編,按討論的主題分成兩篇文章,以饗讀者。在本文中,主要介紹了Jim Keller對摩爾定律、計算機架構(gòu)、未來計算機技術(shù)的發(fā)展趨勢等。文章比較長,但全部是他幾十年從業(yè)經(jīng)驗的深入淺出的闡述,值得細品。
本文是老石談芯 - 大師系列的第四篇,更多大師系列文章,請參見《馬克博爾:延續(xù)摩爾定律的人》、《Doug Burger:FPGA在人工智能時代的獨特優(yōu)勢》。
什么是微處理器、什么是微架構(gòu)、什么是指令集
對于計算機而言,它有著比較明確的設(shè)計層級劃分,這也是這門科學(xué)的特殊魅力之一。原子位于最底層,對原子進行有序排列后,就會得到諸如硅或金屬等材料,于是我們可以用這些材料制作晶體管。
在往上,我們可以使用晶體管組成邏輯門,然后再構(gòu)建邏輯單元,比如加法器、乘法器、或者指令解碼器等等。有了這些邏輯單元,我們就能將它們組合成更加復(fù)雜的處理單元。在現(xiàn)代處理器中,大概由10到20個這樣的處理單元組成。
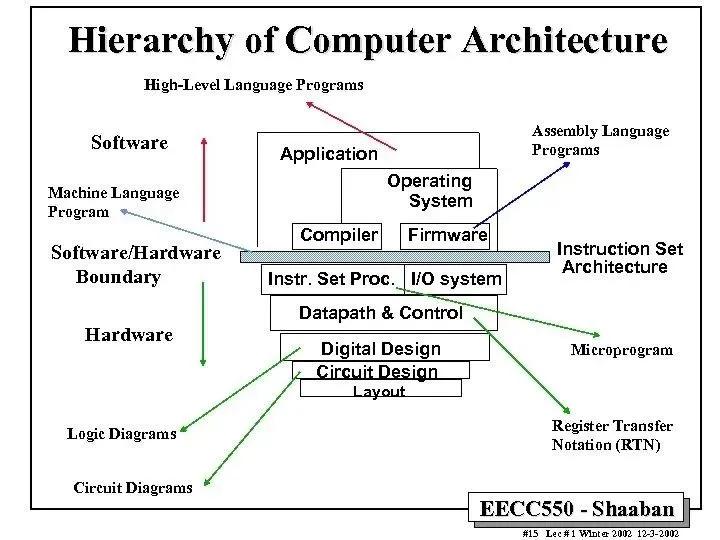 圖片來自羅徹斯特理工RIT
圖片來自羅徹斯特理工RIT
當這些處理單元組合在一起,就可以運行計算機程序了,而這些程序也有著很多抽象層,比如從最底層的指令集,到匯編語言,再到C、C++、Java、JavaScript等等。而所有的這些也構(gòu)成了從原子到數(shù)據(jù)中心的抽象層次。
在這個意義上,當人們設(shè)計計算機時,首先都要對設(shè)計目標有著明確認識。在當前,對計算機的設(shè)計目標有著一系列的衡量指標,比如它的運行速度等等。在一個設(shè)計團隊中,可能有著數(shù)千人,他們分別負責計算機設(shè)計的不同領(lǐng)域和不同方面。對于我個人來說,我對自己在這個團隊中負責哪個方面的工作并不是特別在意。
指令集就是用來編碼計算機的一些最基本的操作,比如加法、乘法、存儲、分支等。事實上,在過去很長的一段時間里,包括x86和ARM在內(nèi)的各類處理器的指令集是相當穩(wěn)定的。因此,目前在領(lǐng)域里并沒有太多有趣的工作。
對于一段程序,大概有90%的代碼都基于25個最基本的微指令,而這些微指令都已經(jīng)十分穩(wěn)定和成熟了。拿英特爾舉例,它的x86架構(gòu)自發(fā)明至今已經(jīng)有大概25年了。基于我們很久之前定義的一些基本原則,它至今都工作的不錯。
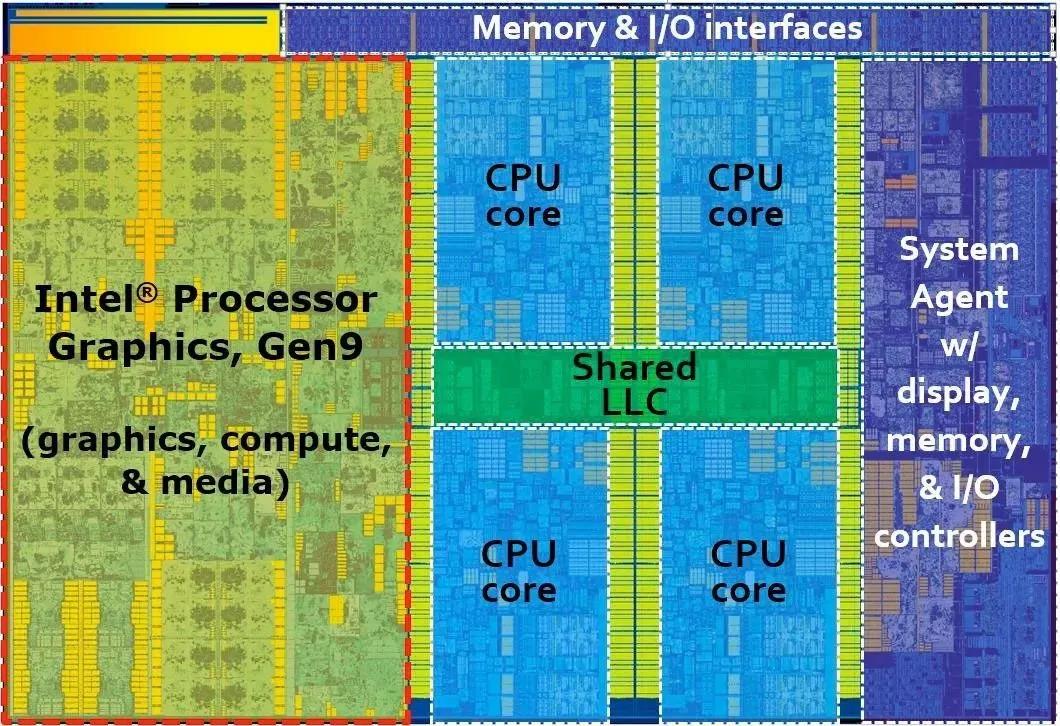 Skylake芯片布局圖,圖片來自TechPowerUp
Skylake芯片布局圖,圖片來自TechPowerUp
以前,計算機的工作方式是取指令,然后順序執(zhí)行這些指令。對于現(xiàn)代計算機而言,它的工作方式是取大量指令,比如500條指令,然后尋找并構(gòu)建這些指令的依賴圖,然后在獨立的執(zhí)行單元里分別執(zhí)行這個依賴圖的子集。
很多人說計算機設(shè)計應(yīng)該簡潔和干凈,但事實上市面上銷售的既“簡潔”又“干凈”的計算機數(shù)量基本為零。在當前的各種計算機中,小到手機,大到數(shù)據(jù)中心,都是通過大量取指、并計算依賴圖的方式進行計算的。
現(xiàn)代計算機基本都支持深度亂序執(zhí)行,它們有著一系列機制負責記錄和追蹤哪些操作即將結(jié)束或可能會結(jié)束。但為了快速運行,計算機必須大量取指,并從中尋找可能的并行性。
想象我們看一本書,書里有很多句子和段落,它們共同組成了書的內(nèi)容。而上面介紹的那種計算機設(shè)計方法,就好比嘗試打亂句子或者段落的排列順序,而不影響它們所表達的內(nèi)容。比如,在介紹一個人的時候,你可以說他是高富帥,但這幾點的順序可以任意排列。你也可以說那個很高的人穿著一件紅色的衣服,而此時這句話里就有了依賴關(guān)系。
我所說的計算機,包括CPU和GPU。對于CPU,它有著很窄的并行度,這根本上是由它順序執(zhí)行的架構(gòu)所決定,這也和人的思考方式相同,我將其稱為“串行敘事(serial narrative)”。
而對于GPU,它的單個處理單元負責處理一個像素點,但它有著上百萬個這樣的單元。當你看一幅圖或一幀畫面時,你并不會在意計算機先處理哪個像素點。因此我將其稱為“天生并行(given parallelism)”。而它也可以看成是串行敘事的大量集合。
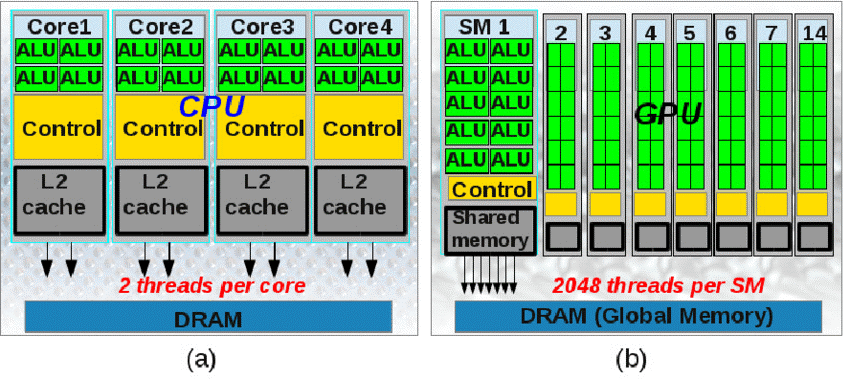 CPU與GPU的架構(gòu)對比,圖片來自網(wǎng)絡(luò)
CPU與GPU的架構(gòu)對比,圖片來自網(wǎng)絡(luò)
在現(xiàn)代計算機中,除了對并行性的探究之外,對分支的預(yù)測也是非常重要的。平均來說,每六條指令中就有一條分支語句,而目前人們可以做到遠超過90%的預(yù)測正確性。
在20年前,我們做分支預(yù)測時會直接記錄上一次的預(yù)測結(jié)果,并預(yù)測這一次仍將重復(fù)這個分支,而這種簡單的預(yù)測方法可以達到85%的正確性。之后,有人提出采用若干位存儲預(yù)測結(jié)果,并使用一個計數(shù)器對之前的預(yù)測結(jié)果進行統(tǒng)計。如果之前走了一個分支,則計數(shù)加一,如果走了另一個分支,則計數(shù)減一,諸如此類。所以如果當這個計數(shù)器大于0,則預(yù)測第一個分支,如果小于0則預(yù)測另一個分支。這種預(yù)測方法將正確性提高到了92%。然后人們認識到,對于某個分支節(jié)點的判斷,很多時候還取決于之前的程序是如何執(zhí)行的,因此這又進一步提升了預(yù)測的準確性。
不過,這些都不是現(xiàn)代計算機做分支判斷的方法。現(xiàn)代計算機中采用了類似神經(jīng)網(wǎng)絡(luò)的方法,簡單來說,它考慮了所有的運行過程,并對這些運行過程進行了不同的深度模式識別,并綜合這些結(jié)果得到分支預(yù)測的答案。事實上,在現(xiàn)代計算機里還有一個小型的超級計算機,專門用來計算這些分支和預(yù)測。
如果我們還使用上面的計數(shù)器的方法做分支預(yù)測,為了達到85%的正確率我們需要上千位的計數(shù)器,而為了達到99%的正確率我們則需要上千萬位。也就是說,為了取得線性的預(yù)測正確性提升,需要付出的代價則是指數(shù)級的。
然而,很多時候并不需要做到100%的預(yù)測正確性,因為有可能不同分支接下來要運行的程序和這些分支并沒有關(guān)系。比如在看書的時候,有時候段與段之間的聯(lián)系并不是非常緊密,如果有一段沒讀懂,也并不會影響后面的閱讀。
人腦與計算機的異同
我個人認為,由于目前人們并沒有真正了解人類大腦是如何工作的,所以很難將人腦與計算機做直接的比較。不過對于計算機來說,通常來講它由兩個主要部分組成,一個是存儲器,一個是計算器。到目前為止,幾乎所有的計算機架構(gòu)的工作機理,都是從存儲器中拿數(shù)據(jù),通過計算單元進行計算,然后將結(jié)果寫回存儲器。
對于人腦來說,神經(jīng)元通過各種方式進行連接,它們可以是局部互聯(lián)的,也可以是全局互聯(lián)。而數(shù)據(jù)和信息則通過類似于分布式的方法進行保存。基于此,研究人員構(gòu)建了所謂的人工神經(jīng)網(wǎng)絡(luò),并提出了很多對應(yīng)的數(shù)學(xué)理論對其進行支撐。但這種結(jié)構(gòu)和人腦的實際結(jié)構(gòu)還是有著很大的區(qū)別。
計算機系統(tǒng)的確定性
如果你在CPU上運行一段C語言程序,那么每次你都會得到一樣的運行結(jié)果。但對于現(xiàn)在的AI應(yīng)用來說,其中的神經(jīng)網(wǎng)絡(luò)采用了很低精度的數(shù)據(jù)表示,而且輸入數(shù)據(jù)也有著極大的噪聲。在這種情況下,何必追求完全正確且精確的計算呢?
人們通過研究證明,當允許一定程度的誤差時,很多算法可以在更短的時間內(nèi)完成計算,也從而帶來功耗的降低和系統(tǒng)性能的提升。
另一方面,在諸如HPC等的很多應(yīng)用中,如果同一個計算的每次結(jié)果都不相同,那也是不可接受的。而且,如果此時計算結(jié)果錯誤,往往很難確定究竟是算法錯誤還是計算機制錯誤。因此,在計算機系統(tǒng)的確定性與隨機性之間,人們需要做仔細的權(quán)衡。
在進一步,即使每次運行結(jié)果都相同,也不代表在計算機中執(zhí)行了相同的計算、或使用了相同的數(shù)據(jù)通路。事實上,對于很多在現(xiàn)代計算機中運行的程序來說,運行一百遍會得到相同的結(jié)果,但每一次運算在計算機里面運行的順序、采用的計算單元、涉及的硬件結(jié)構(gòu)等等都不盡相同。
計算機架構(gòu)應(yīng)該每5年推倒重來
當設(shè)計或改進計算機架構(gòu)的時候,人們?nèi)菀紫萑脒@樣的誤區(qū)。比如,有人提出需求說希望計算機比現(xiàn)在運行的要更快10%,于是架構(gòu)師就開始看哪里可以增加存儲器、哪里可以增加運算單元、亦或是增加數(shù)據(jù)總線寬度等等。
漸漸的你會發(fā)現(xiàn),每個運算單元都會變得越來越復(fù)雜,系統(tǒng)性能也逐漸到達瓶頸。也就是說,不管你再增加多少存儲、增加多少運算單元、增加多少總線寬度,計算機的性能都無法提升更多了。
這時,聰明的架構(gòu)師會認識到,性能瓶頸是由之前的系統(tǒng)劃分、以及這些復(fù)雜運算單元的相互耦合造成的。于是,他們會對系統(tǒng)進行重構(gòu)。這樣的結(jié)果,是系統(tǒng)性能得到進一步提升,然后每個計算單元的復(fù)雜性也會大幅下降。
我認為,像這樣的系統(tǒng)級重構(gòu),每三到五年應(yīng)該來一次。也就是說,如果你想從根本上提升計算機架構(gòu),至少每隔五年需要從新開始進行設(shè)計。
20多年前,我是64位x86指令集的最早設(shè)計者之一。盡管指令集沒有發(fā)生太多有趣的改變,但基于這些指令集的x86架構(gòu)在這些年間的變化巨大。英特爾和AMD都有很多各自的架構(gòu)出現(xiàn)。然而,目前我說的這些根本性重構(gòu)基本是10年一次,而我希望是至少五年一次。
對計算機結(jié)構(gòu)的重新設(shè)計會帶來兩個問題。對于需要每個季度發(fā)布業(yè)績的團隊來說,他們往往對這種系統(tǒng)級重構(gòu)畏手畏腳。然而對于有長遠目標的團隊來說,重構(gòu)時帶來的短期風險也會影響他們達成長期目標。
因此,一個常見的方式是同時做多個項目,這樣你可以在優(yōu)化已有設(shè)計的時候,同時開發(fā)全新的架構(gòu)。
那些市場部的人經(jīng)常喜歡向人們保證,新的計算機架構(gòu)比前一代的每個方面都更快更好。事實上,一個工程師會告訴你,平均來講新的架構(gòu)會更好,但由于性能曲線的存在,會有比前一代更慢的產(chǎn)品,而這也有可能對客戶造成影響。
摩爾定律不死
戈登·摩爾對摩爾定律的表述大概是,晶體管數(shù)量每兩年會翻倍。我對摩爾定律的理解是,計算機的性能每2到3年提高一倍。這項表述在過去的若干年里都相當正確。近年來,人們引入了所謂的“收縮因子”(shrinking factor),它大概是0.6左右。也就是說,每2到3年的性能提升從1除以0.5變成了1除以0.6。
我從事計算機設(shè)計已經(jīng)有40年了,一開始人們說摩爾定律在接下來的10到15年會死,我當時還信了。10年之后人們又說過10到15年摩爾定律將死,然后幾年后又成了5年后會死,過了幾年又成了10年,諸如此類。后來,我就不再關(guān)心摩爾定律什么時候會真正失效了。
然后我加入了英特爾,在這里也有人說摩爾定律將死,而這讓我很無語,因為英特爾正是代表摩爾定律本身的公司。對于我來說,摩爾定律將死就是一個偽命題,這和擔心某天我們會缺少食物、缺少空氣等等一樣。

很多人認為摩爾定律代表的不過是晶體管變的越來越小,但實際上摩爾定律代表的是推動這一變化背后的千千萬萬個技術(shù)創(chuàng)新。對于某個技術(shù)來說,它會隨著時代的演進而逐漸落伍,但大量這樣的技術(shù)創(chuàng)新結(jié)合在一起,就能推動整個領(lǐng)域不斷向前。
以前,晶體管的長寬高大約各是1000個原子,現(xiàn)在晶體管的尺寸變成了長寬高各10個原子,因此尺寸縮小了一百萬倍。現(xiàn)在的技術(shù)允許人們直接對原子進行排列,這理論上會得到更小的晶體管。但在實際生產(chǎn)中,你是無法對10的23次方個原子一一排列的。因此,科學(xué)家們在物理、化學(xué)、材料等多個領(lǐng)域進行了很多創(chuàng)新,使得我們能穩(wěn)定的制造高良率的半導(dǎo)體器件,而這些創(chuàng)新也是摩爾定律背后的根本推動力量。
作為計算機架構(gòu)師來說,我們需要做的是考慮如何利用這些不斷增加的晶體管,并基于此設(shè)計更高效的計算機架構(gòu)。我的老朋友Raja Koduri曾說過,晶體管尺寸每縮小10倍,就會衍生出一種全新的計算模式。他也將現(xiàn)在的計算模式分成了標量計算、向量計算、矩陣計算和空間計算四類,分別對應(yīng)基于CPU、GPU、AI ASIC和FPGA的計算。同時,我們也要考慮很多制約因素,比如人本身不會變的更聰明,而且團隊的規(guī)模不會不斷增長。以前我們會使用更快的計算機來幫助我們設(shè)計計算機本身,但現(xiàn)在這種方式已經(jīng)不再有效,我們也因此需要對設(shè)計軟件進行不斷的重構(gòu)和更新。
 4種計算模式,圖片來自英特爾
4種計算模式,圖片來自英特爾
結(jié)語
科技的發(fā)展離不開大師的推動。作為從業(yè)者,我們應(yīng)該高興生于這個風起云涌的年代,因為這里隨處充滿了無窮的機遇和挑戰(zhàn)。作為普通人,我們也應(yīng)該高興生活在這個時代,因為能夠享受科技的發(fā)展為生活帶來的無盡便利。
在下一篇文章中,老石將繼續(xù)分享Jim Keller對人工智能的理解,以及他在職業(yè)生涯中的諸多哲學(xué)層面的思考。敬請期待。

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章