Imagination推出邊緣AI&圖形處理E-Series GPU IP
2025-05-09 19:15:43 周菊香,EETOP隨著 deepseek 等輕量化大模型快速發展, Edge端 AI 應用正在進入爆發期,從智能終端供應設備到車載系統,對邊緣側的算力提出了前所未有的需求。在這樣的背景下,Imagination Technologies隆重推出 Imagination E-Series GPU IP,重新定義了邊緣人工智能和圖形系統設計。
在近期召開的媒體發布會上,Imagination中國區技術總監艾克分享說:“E系列GPU是Imagination劃時代的一款GPU產品,是針對邊緣側推出的一種更高效、更靈活的AI和圖像處理的解決方案。首款 E-Series GPU IP 將于 2025 年秋季正式上市,目前已完成授權。汽車、消費電子、桌面及移動版本亦在同步開發中。”

據介紹,E-Series延續了Imagination GPU 一貫強大的圖形處理能力,包括對光線追蹤的支持。在此基礎上,E系列GPU具備兩項核心創新,即Neural Cores(神經核)和Burst Processors(爆發式處理器)。
l Neural Cores(神經核):性能可擴展至200 TOPS INT8 ,AI 性能較前代D系列( D-Series )提升高達 400%;支持多種主流 AI 數值格式,能夠與更廣泛的GPU及異構計算軟件生態實現無縫協同。其算力可通過OpenCL 等主流 API直接調用,開發者借助oneAPI、Apache TVM 或 LiteRT等開放標準工具,能將工作負載遷移至神經核。
l Burst Processors:爆發式處理器是E系列引入的全新技術,該技術通過縮短流水線深度、減少數據在GPU內部的移動,實現能效提升。在 AI 推理、游戲和用戶界面等工作負載下平均功耗效率再提升 35%。
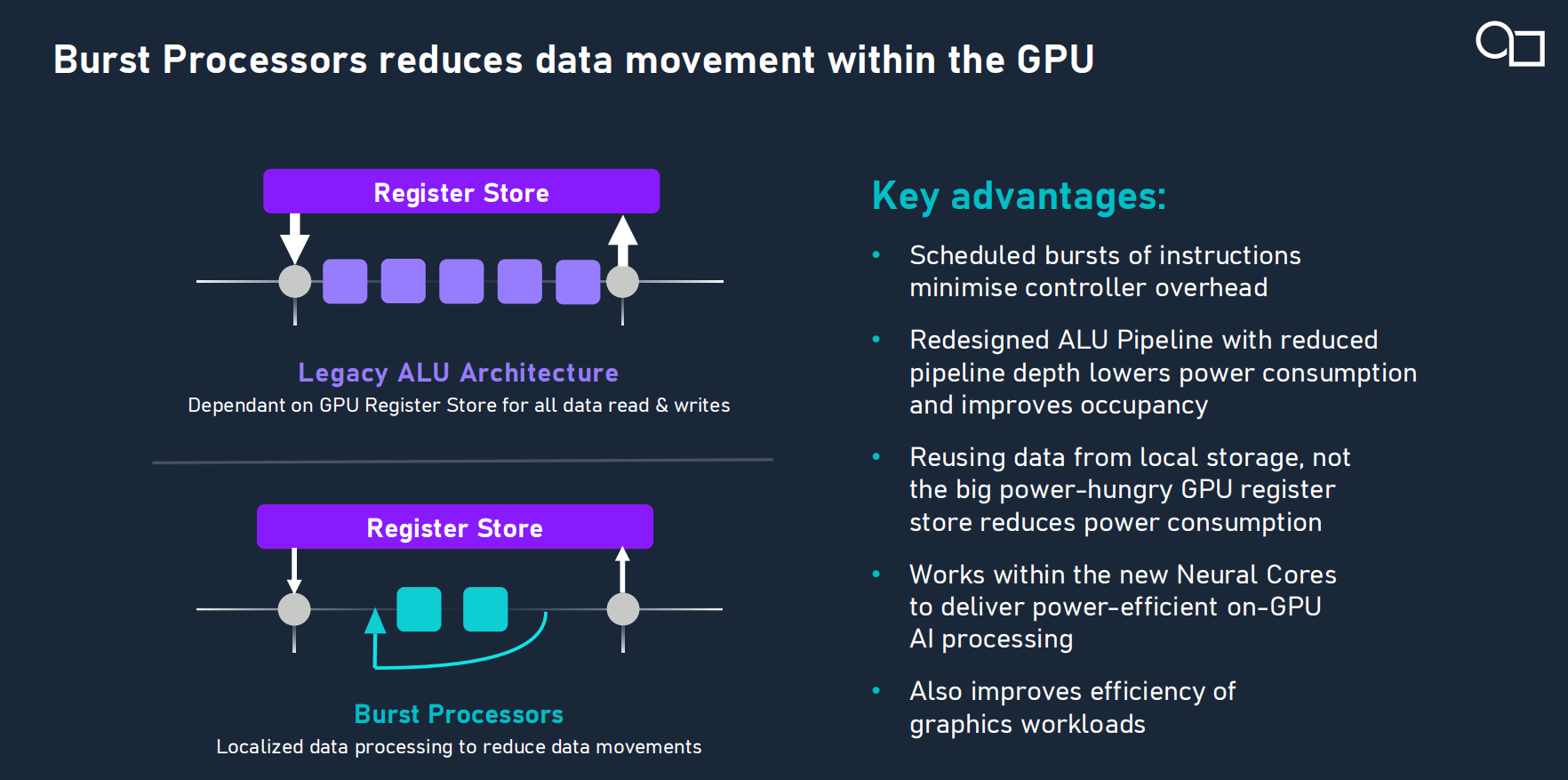
Imagination 產品管理副總裁Kristof Beets特別強調的說:“35% 的能效提升是依靠硬件架構的創新來實現的,具體包括整體調度、數據的存取以及數據類型,以及新加入的處理流水線。不是通過工作負載的重新分配,算法的優化來實現的,也不是通過工藝制程來實現的,純粹就是硬件架構的革新帶來的能效提升。”
E系列架構創新的幾個關鍵
E系列GPU的核心創新在于通過將AI算力與GPU核心渲染管線深度融合,實現了硬件層面的統一調度與資源共享。這一架構突破,不僅解決了傳統GPU與AI加速器解耦設計的效率瓶頸,更通過硬件級融合,為異構計算提供了高密度、低延時的協同計算范式。
E系列 GPU原生調度的關注點是放在利用率的提升上。它由數據驅動,讓運算的流水線盡可能保持忙碌,通過同時處理多個并行的圖形處理和AI工作負載,來調度圖形和AI工作去減少系統延遲,并保證 ALU 盡可能的繁忙。當 ALU 的利用率越高,也就意味著整體帶寬延遲就越低。
艾克介紹說:“Burst 技術是E系列的一個突破性技術。它深度集成于GPU硬件的底層,通過動態識別連續可歸類的背靠背(back to back)指令,合并批量任務,可對盡可能多的數據進行復用和共享,從而提高數據利用率,減少指令解碼器的開銷。”
在底層硬件之上的一層是可以通過軟件編程來實現資源調度,在更高層級上的調度決策,則由軟件指導來進行優先級的調配。如果同時要進行圖形處理和 AI 處理,那么就可以由系統去定義當前更想要把優先級調整給AI,還是圖形處理,靈活性取決于對兩者之間的負載平衡的需求。
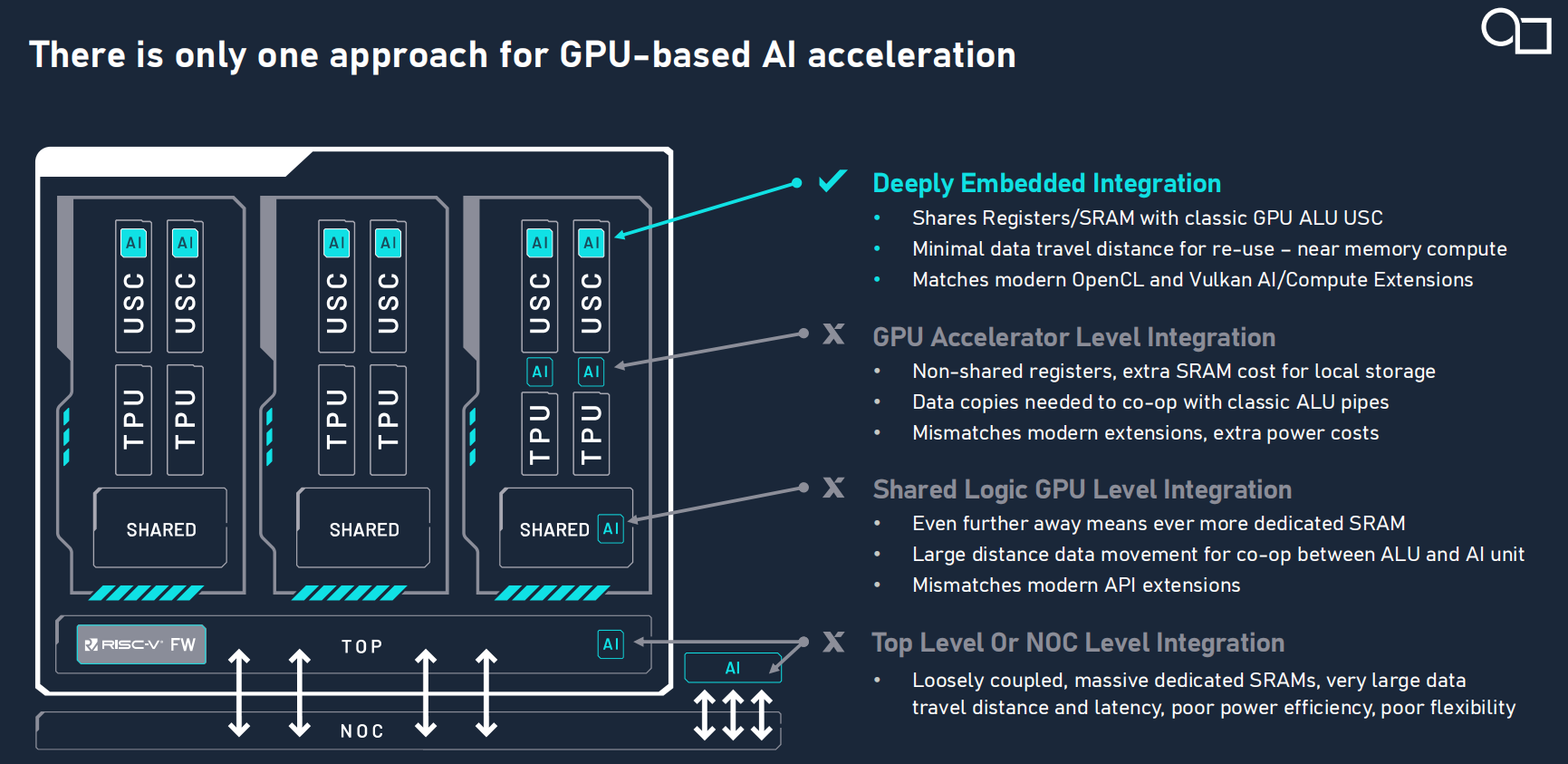
這種全新的調度方法,讓它能夠提升所有不同類型計算的能效,無論是圖形計算、通用并行計算,還是專門針對AI的處理。Kristof Beets表示:“ 這種深度集成的方式整個改變了原來 GPU 的指令調度方式,能夠讓我們去配合市場上更高層級的軟件堆棧,并且在執行各項計算任務的時候,不會影響延遲。”
E系列GPU在架構上的另一項非常重要的設計,是在每一個計算單元中都有將近0.5Mb的寄存器空間。這是一個專門針對常見人工智能相關計算增加的就矩陣乘法加速器,可以實現更好的傳統圖像處理以及后期圖像處理。它的面積成本非常低,本質上沒有額外增加芯片面積,只不過是在其中又增加了 AI 相關的高效處理管線。
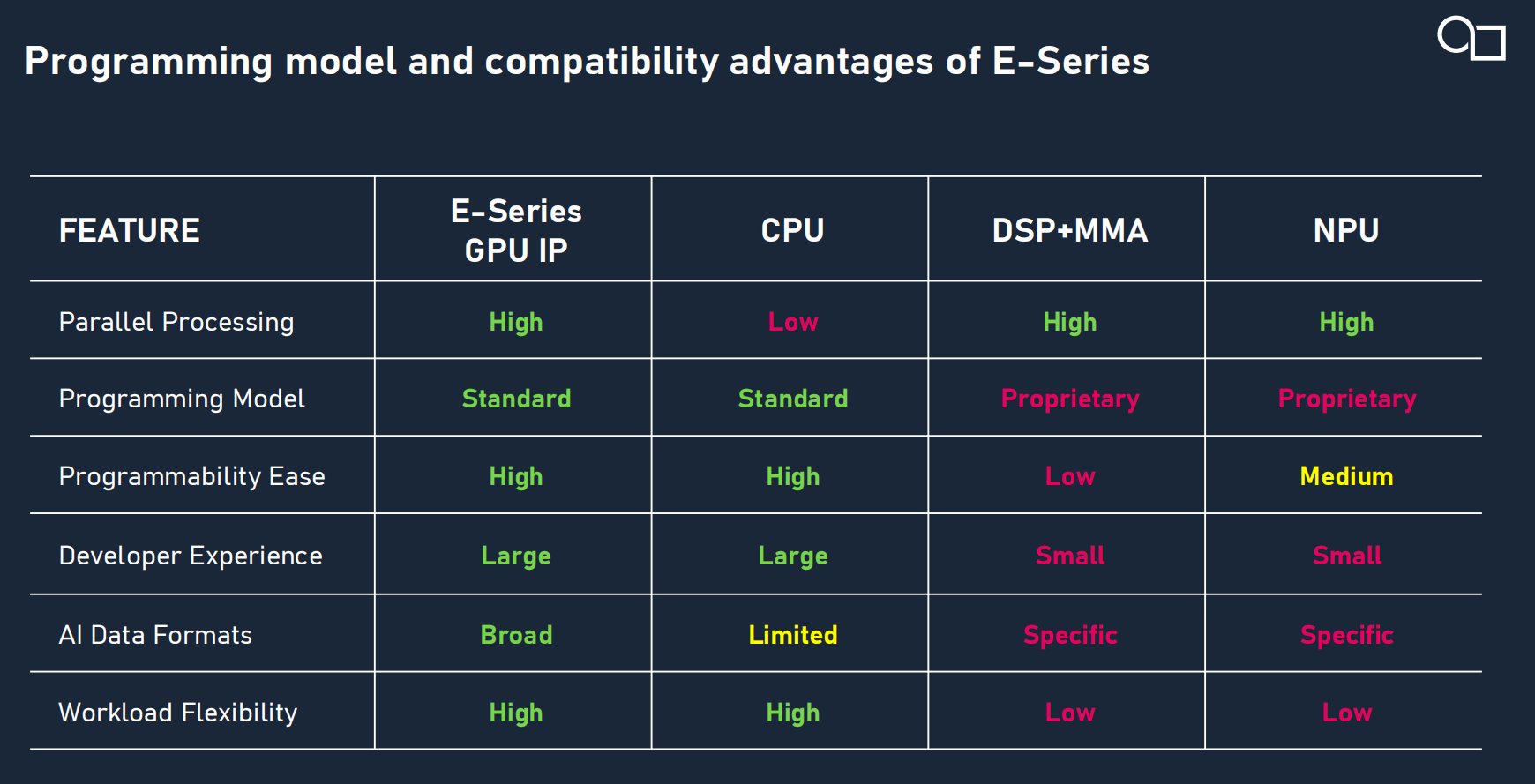
過去十年間,業界使用的模型已經一代接一代的發生了巨大的變化,而且新的AI創新還在不斷涌現并將持續多年。在這種時候,欠缺靈活性的 NPU 就面臨著挑戰。NPU 本身的設計目標就是為了支持特定數量的 AI 應用。一旦出現了新的 AI 應用,那這個 NPU 就處理不了,就不得不交回給 CPU 去處理。由此就會產生非常大的延遲,對性能的影響也是巨大的。而 GPU 的優勢就在于可以去應對未來AI 和圖形處理的這些挑戰。它不需要去升級硬件,只需要針對應用,對軟件進行一些改進就可以,通過可編程的 GPU 引擎的方式在管線內去進行 AI 計算處理。此外,對于未來的人工智能網絡,GPU擁有更高的靈活性和可編程性,可以去應對新AI 處理模型,并且可以以幾乎沒有延遲的方式去應對未來的這些 AI 新模型。
當前,聯網設備日益復雜,處理器需同時支持圖形與AI多項工作負載。為保障用戶體驗,實現高質量服務(QoS)和清晰劃分任務優先級至關重要。E-Series在前代產品的多任務處理能力基礎上實現了增強,將Imagination GPU支持的、具備硬件加速且零開銷的虛擬機數量從8個翻倍至16個,并提供了先進的QoS支持。E-Series GPU的多核版本可以利用額外的核來提升性能或增強靈活性。這些GPU能夠同時處理多種圖形工作負載、多種AI工作負載,或圖形與AI工作負載的組合。
智能汽車是一個非常具有潛力且龐大的應用場景。從低端到高端車型,幾乎都存在不同的AI處理應用。未來的智能駕駛車輛,更是妙趣橫生,會有越來越多的多模態數據輸入,功能對于算力的需求將逐步上升,甚至朝著上千TOPS以上的方向去發展。E系列GPU面向汽車用戶,提供了一系列關鍵功能,如可以實現座艙圖形、儀表渲染與AI推理(駕駛員監測、語音交互)的統一等。
Kristof分享說:“E系列GPU 可以被用于許多不同的場景和用途,不僅僅可以用在人工智能處理應用,還可以用于計算處理的應用場景,包括圖形濾鏡等經典的圖像處理等。此外,在一些經典算法的應用中,E系列 GPU 核當中全新的、經過改善的運算單元也可以充分發揮作用。
回看過去的 10 到 15 年,AI模型大多都是在云端被訓練出來,之后這些AI模型很大可能是被部署到本地或者邊緣設備。但是,在邊緣使用AI面臨著很大的挑戰,如連接性、可靠性,延遲等問題,另外還有安全和隱私的問題,尤其是處理一些敏感的數據,如生物信息數據、安全數據以及財務相關的數據。由此,越來越多的生成式AI和大語言的模型的開始逐步被部署支持AI的邊緣設備上。
在邊緣設備上面部署 AI ,功耗和成本是兩大關鍵問題。在數據中心,計算可以依賴巨量的電力供應并使用非常昂貴的處理器,但是在邊緣設備上,就必須做到對功耗和成本極度敏感。Imagination中國董事長兼亞太區總裁白農表示:“E系列是Imagination在圖形和計算領域多年來累積的又一個里程碑,它不僅在性能、功耗和面積方面實現了全面的優化,更在架構設計上實現了從傳統渲染將通用計算的深度拓展,具備高度的靈活性和可擴展性。”
關鍵詞: Imagination 推出 邊緣