CUDA模擬器來了!AMD、英特爾擺脫英偉達束縛之利器
2024-01-04 12:08:28 EETOP現在,CPU 既有矢量數學單元,也有矩陣數學單元,而 GPU 計算引擎的短缺又無法滿足生成式人工智能熱潮帶來的巨大需求,因此,毫無疑問,人們不僅需要CUDA 并行編程環境(Nvidia 將其作為 GPU 計算平臺的核心)的替代品,還需要在任何可以進行矢量或矩陣數學運算的設備上運行 CUDA 代碼。AMD的 HIP(其 ROCm 堆棧的一部分)和英特爾的SYCL(其 oneAPI 的核心)等替代性并行(在特性和功能方面)編程環境可以幫助CUDA 程序員將其知識應用到新設備上,這非常好。但是,在代碼的某些部分還存在很多問題,而且還沒有一個通用的模擬器可以將CUDA 轉換到任何 GPU 或 CPU。
我們在 GPU 和 CPU矢量/矩陣計算方面需要的是類似 QuickTransit 模擬器的東西,它是由曼徹斯特大學一個聰明的技術團隊創造的,經過四年的開發,于 2004 年由一家名為Transitive 的公司作為商業產品推出。
你們中的許多人都在不知不覺中使用過 QuickTransit。超級計算機制造商 SGI 在從MIPS 轉向 Itanium 架構的過程中率先采用了這種模擬器,蘋果公司也緊隨其后,在其客戶端計算機從 PowerPC 轉向英特爾酷睿處理器的過程中,將自己的 "Rosetta "仿真環境建立在 QuickTransit 的基礎上。IBM于 2008 年收購了 Transitive 公司,但由于放開它太危險了,所以基本上沒有投入使用。(Big Blue公司確實利用該技術在其 Power iron 上為Linux 提供了 X86 運行環境,但在 2012 年停止了對該技術的支持)。
雖然我們沒有針對 GPU 的QuickTransit,但我們確實有一個由佐治亞理工的研究人員和首爾國立大學的研究人員共同開發的名為CuPBoP "Cuda for Parallelized and Broad-range Processors"(針對并行化和寬范圍處理器的 Cuda)的東西,它可以將 CUDA 內核自動移植到LLVM 編譯器堆棧上運行,并在 GPU 或 CPU 上執行。(有趣的是,LLVM 的創建者之一Chris Lattner 是模塊化人工智能公司(Modular AI)的首席執行官,該公司正在創建一種名為 Mojo 的新編程語言,在更高層次上為跨多種設備的人工智能應用提供一種可移植性)。這個 CuPBoP 框架在概念上有點像QuickTransit,但又完全不同。
CuPBoP 框架是在 2022 年 6 月發表的一篇論文中介紹的,該框架的源代碼可在 GitHub 上找到。CuPBoP 本周引起了我們的注意,佐治亞理工學院的研究人員發布了一種名為 CuPBoP-AMD 的框架變體,該變體經過調整可在 AMD GPU 上工作,并提供了ROCm 中 AMD HIP 環境的替代方案,可將 Nvidia CUDA 代碼移植到AMD GPU。很多人都在想,現在AMD 正在推出其“Antares”MI300X 和MI300A 計算引擎,它們可以與Nvidia Hopper H100 和 H200 設備正面交鋒了。
https://dl.acm.org/doi/pdf/10.1145/3624062.3624185
當 AMD 和英特爾談論移植或仿真 CUDA 應用程序時,佐治亞理工的團隊是這樣看待在丹佛 SC23 超級計算大會上發表的后一篇論文的:
"英特爾有一個名為 SYCLomatic 的數據并行C++ (DPC++) 庫,用于將 CUDA 轉換為 SYCL,該庫在ROCM 4.5.1 中支持 AMD GPU 的運行時,但在撰寫本文時,該庫還處于測試模式,沒有完整的功能支持。AMD 利用HIPIFY 將 CUDA 轉換為 HIP。不過,HIPIFY并不考慮紋理內存中的設備側模板參數和多個 CUDA 頭文件".cuh"。因此,HIPIFY需要開發人員手動操作。在大型 CUDA 程序庫中,開發人員的手動操作可能非常麻煩,而這正是 CuPBoP 框架要解決的問題。CuPBoP是一個允許在非英偉達設備上執行 CUDA 的框架"。
CuPBoP 的部分訣竅在于使用 LLVM 框架及其Clang 編譯器,它可以將 Nvidia CUDA 和 AMD HIP 程序編譯成標準的中間表示(IR)格式,然后再將其編譯成 AMD GPU 的二進制可執行文件。CuPBoP 編譯流水線如下所示:
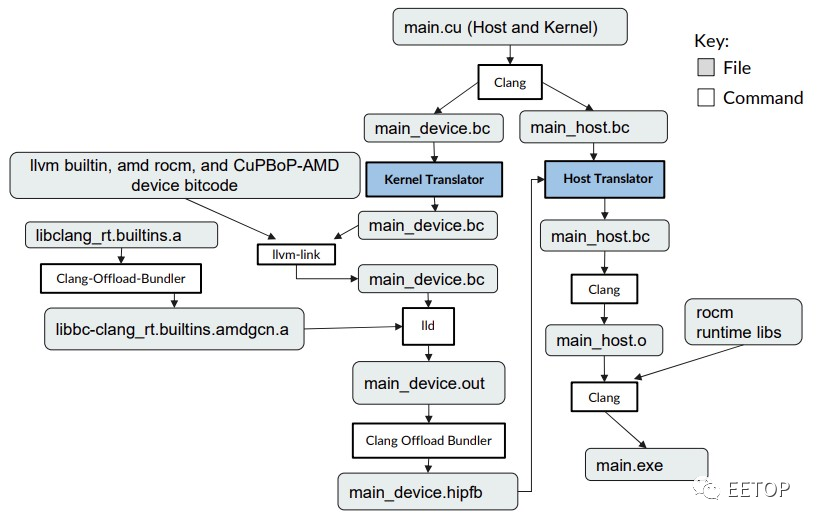
CuPBoP 框架創建兩個 IR 文件,一個用于內核代碼,一個用于主機代碼,并且正是在這個 IR 級別完成對AMD GPU 的轉換,而不是在更高級別上完成轉換宏和單獨的頭文件AMD的HIP工具有些麻煩。
目前,CuBPoP 框架僅支持Rodinia Benchmark中使用的 CUDA 功能,Rodinia Benchmark 是弗吉尼亞大學創建的一套測試,用于測試 2009 年首次亮相的當前和新興技術,當時 GPU 剛剛開始使用他們進入數據中心的方式。Rodinia 應用程序和內核涵蓋數據挖掘、生物信息學、物理模擬、模式識別、圖像處理和圖形處理算法——高級架構的創建是為了更好地解決這些問題。
以下是 CuPBoP 框架的CuPBoP-AMD 變體如何與 ROCm 堆棧中的 AMD HIPIFY 工具進行對比:
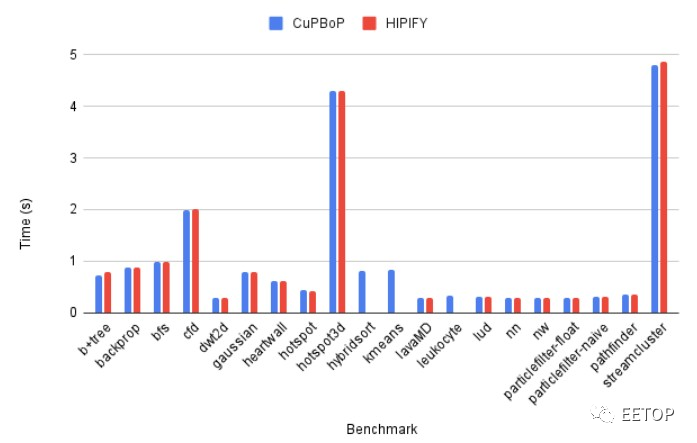
就已轉換為在 AMD GPU 上運行的CUDA 代碼的執行而言,CuPBoP-AMD 的性能看起來與 HIP 沒有區別。當然,我們很想看看被翻譯后的 CUDA 代碼與在Nvidia A100、H100 和 H200 GPU 上本地運行的情況有何不同。研究人員表示,CuPBoP-AMD 仍在進行中,需要啟用更多 Rodinia 基準功能。這始終是模擬器和翻譯器的問題:他們總是在追趕。但是,話又說回來,它們讓新平臺實際上能夠更快地迎頭趕上。
本文由EETOP編譯自nextplatform
關鍵詞: CUDA CUDA模擬器 QuickTransit CuPBoP