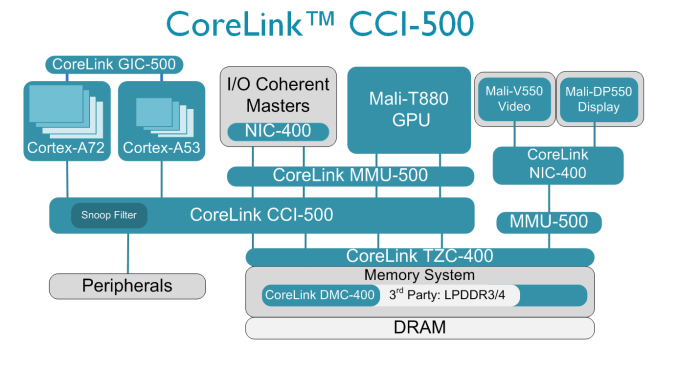
重塑Scoreboard機(jī)制,讓 CPU 性能躍升!
2025-07-02 13:34:09 EETOP 作者:Thang Minh Tran 博士本文作者:Thang Minh Tran 博士,Simplex Micro 公司首席執(zhí)行官兼首席技術(shù)官
核心要點(diǎn)
當(dāng)今的人工智能加速器面臨著深度流水線和復(fù)雜數(shù)據(jù)依賴等挑戰(zhàn)。
這種架構(gòu)可實(shí)現(xiàn)精確的指令調(diào)度,且沒(méi)有推測(cè)執(zhí)行的開(kāi)銷。
通過(guò)最大化指令發(fā)布時(shí)機(jī)并最大限度地減少無(wú)效功耗周期,確保了能源效率。
當(dāng)今的人工智能加速器,無(wú)論是為大型數(shù)據(jù)中心還是低功耗邊緣設(shè)備所構(gòu)建,都面臨著一系列共同的挑戰(zhàn):深度流水線、復(fù)雜的數(shù)據(jù)依賴以及推測(cè)執(zhí)行的高昂成本。這些問(wèn)題在高頻微處理器設(shè)計(jì)中早已為人熟知,工程師們必須不斷在性能和正確性之間尋求平衡。流水線越深,指令級(jí)并行的機(jī)會(huì)就越大,但流水線冒險(xiǎn)的風(fēng)險(xiǎn)也越高,特別是寫(xiě)后讀(RAW)依賴。
20 世紀(jì) 70 年代出現(xiàn)并在 90 年代超標(biāo)量繁榮時(shí)期得到改進(jìn)的傳統(tǒng)Scoreboard(記分板)架構(gòu),僅提供了部分解決方案。雖然能發(fā)揮作用,但它們難以隨著現(xiàn)代流水線日益增長(zhǎng)的復(fù)雜性而擴(kuò)展。每增加一個(gè)階段或執(zhí)行通道,操作數(shù)比較的數(shù)量就會(huì)呈指數(shù)級(jí)增長(zhǎng),這會(huì)引入延遲,使得維持高時(shí)鐘頻率變得更加困難。
Scoreboard的核心功能是確定一條指令是否可以安全發(fā)布,這需要將正在執(zhí)行的指令的目標(biāo)操作數(shù)與等待發(fā)布的指令的源操作數(shù)進(jìn)行比較。在深度或?qū)挾容^大的流水線中,這種邏輯很快就變成了一個(gè)組合邏輯難題。需著手解決的問(wèn)題是:我們能否在不依賴復(fù)雜的關(guān)聯(lián)查找或推測(cè)機(jī)制的情況下,準(zhǔn)確地對(duì)操作數(shù)時(shí)序進(jìn)行建模?
在筆者開(kāi)發(fā)雙行Scoreboard時(shí),目標(biāo)是在無(wú)線基帶芯片中支持確定性時(shí)序,因?yàn)樵谶@種芯片中,實(shí)時(shí)性保證至關(guān)重要,而且能源預(yù)算緊張。但隨著時(shí)間的推移,這種架構(gòu)被證明具有廣泛的適用性。當(dāng)今的工作負(fù)載,特別是人工智能推理引擎,通常要管理數(shù)千個(gè)同時(shí)進(jìn)行的操作。在這些領(lǐng)域,傳統(tǒng)的推測(cè)方法,如亂序執(zhí)行,可能會(huì)帶來(lái)能源成本和驗(yàn)證復(fù)雜性的問(wèn)題,這在實(shí)時(shí)或邊緣部署中是不可接受的。
筆者的方法則另辟蹊徑,以可預(yù)測(cè)性和效率為基礎(chǔ)。開(kāi)發(fā)了一種雙行Scoreboard架構(gòu),它通過(guò)周期精確的時(shí)序和基于移位寄存器的跟蹤,重新構(gòu)想了傳統(tǒng)模型,在消除推測(cè)的同時(shí),能夠適應(yīng)現(xiàn)代人工智能工作負(fù)載。它將時(shí)序邏輯分為每個(gè)架構(gòu)寄存器的兩個(gè)同步但獨(dú)立的移位寄存器結(jié)構(gòu),確保了精確的指令調(diào)度,且沒(méi)有推測(cè)開(kāi)銷。
Scoreboard機(jī)制—— 移位寄存器方法
可以把雙行Scoreboard想象成一個(gè)傳送帶系統(tǒng)。每個(gè)寄存器都有兩條軌道。上行軌道監(jiān)控?cái)?shù)據(jù)在流水線中的位置;下行軌道監(jiān)控?cái)?shù)據(jù)何時(shí)準(zhǔn)備就緒。每個(gè)時(shí)鐘周期,這些傳送帶上的標(biāo)記都會(huì)移動(dòng)一步,推進(jìn)每條指令的時(shí)間線。
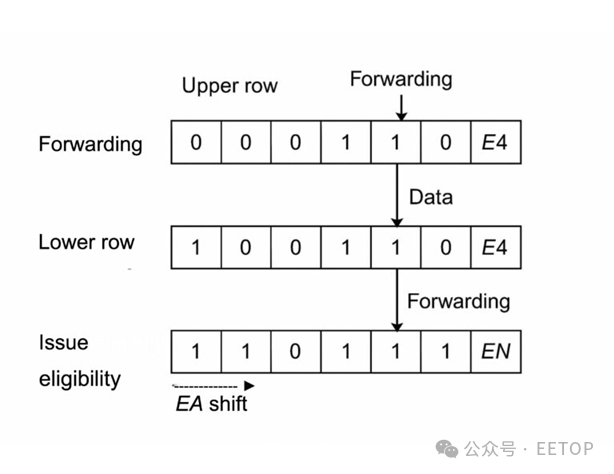
轉(zhuǎn)發(fā)跟蹤器—— 上行軌道:這一行作為移位寄存器運(yùn)行,在流水線階段之間移動(dòng)一個(gè)單例“1”,精確跟蹤將生成結(jié)果的指令的位置。這使得無(wú)需直接訪問(wèn)寄存器文件就能進(jìn)行轉(zhuǎn)發(fā)。
發(fā)布資格跟蹤器—— 下行軌道:第二行獨(dú)立地跟蹤結(jié)果何時(shí)可用,使用一串從最早可用階段開(kāi)始的“1”。如果依賴的指令在數(shù)據(jù)準(zhǔn)備好之前需要它,發(fā)布就會(huì)停滯。否則,就立即進(jìn)行。
通過(guò)將操作數(shù)就緒狀態(tài)與執(zhí)行時(shí)序進(jìn)行比較,Scoreboard使用以下公式做出簡(jiǎn)單直接的發(fā)布決策:
D = (EA – E) – EN + 1
其中:
E 是生產(chǎn)者指令的當(dāng)前階段
EA 是結(jié)果首次可用的階段
EN 是消費(fèi)者首次需要結(jié)果的階段
如果 D≤0,依賴的指令可以安全發(fā)布。如果 D>0,則必須等待。
例如,假設(shè)結(jié)果在 EA = E3 時(shí)可用,生產(chǎn)者當(dāng)前處于 E2 階段,消費(fèi)者在 EN = E2 時(shí)需要它。那么:D = (3 – 2) – 2 + 1 = 0→該指令可以立即發(fā)布。這種簡(jiǎn)單的算術(shù)運(yùn)算確保了確定性的執(zhí)行時(shí)序,使該架構(gòu)具有可擴(kuò)展性和高效性。
集成與實(shí)現(xiàn)
每個(gè)架構(gòu)寄存器都有自己的Scoreboard “頁(yè)面”,其中包含上行和下行軌道。因此,Scoreboard是一種稀疏的、分布式結(jié)構(gòu),概念上是一個(gè) 3D 數(shù)組,按寄存器名稱(深度)、流水線階段(列)和邏輯類型(上行與下行軌道)進(jìn)行索引。由于兩行都與流水線時(shí)鐘同步移位,因此不需要多周期仲裁或停滯傳播。
寄存器文件本身也得到了簡(jiǎn)化,因?yàn)樵S多操作數(shù)從未到達(dá)那里。如果結(jié)果在產(chǎn)生后很快就被消耗,數(shù)據(jù)轉(zhuǎn)發(fā)允許結(jié)果完全跳過(guò)寄存器文件。這在功耗和面積方面都有好處,特別是在寄存器文件寫(xiě)入端口成本高昂的小工藝節(jié)點(diǎn)中。
為何在今天仍有重要意義
筆者構(gòu)建這個(gè)架構(gòu)是為了解決一個(gè)極其具體的問(wèn)題:如何在無(wú)線調(diào)制解調(diào)器中保證實(shí)時(shí)執(zhí)行,在這種情況下,失敗是絕不容許的。我的設(shè)計(jì)首次應(yīng)用于 TI 的 OMAP 1710,它不僅為主要的 ARM+DSP 組合提供動(dòng)力,還塑造了支持 GSM、GPRS 和 UMTS 的專用調(diào)制解調(diào)器流水線。
在調(diào)制解調(diào)器路徑中,錯(cuò)過(guò)最后期限意味著數(shù)據(jù)包丟失,這不像丟失視頻幀那樣只是令人煩惱,而是至關(guān)重要的。因此,我專注于可預(yù)測(cè)的延遲、范圍嚴(yán)格的內(nèi)存和結(jié)構(gòu)化的任務(wù)流程。這種源于調(diào)制解調(diào)器的藍(lán)圖,如今在人工智能和邊緣芯片中煥發(fā)新生,在這些領(lǐng)域,功耗限制要求同樣嚴(yán)格、確定性的執(zhí)行。
對(duì)于邊緣人工智能設(shè)備等功耗受限的環(huán)境,推測(cè)執(zhí)行帶來(lái)了一個(gè)獨(dú)特的挑戰(zhàn):預(yù)測(cè)錯(cuò)誤的指令所造成的無(wú)效功耗周期會(huì)迅速耗盡能源預(yù)算。人工智能推理工作負(fù)載通常要處理數(shù)千個(gè)并行操作,而不必要的推測(cè)會(huì)迫使計(jì)算單元花費(fèi)電力執(zhí)行最終會(huì)被丟棄的指令。雙行Scoreboard的確定性調(diào)度消除了這個(gè)問(wèn)題,確保只在恰好合適的時(shí)間發(fā)布必要的指令,在不犧牲性能的情況下最大限度地提高能源效率。
寄存器文件本身也得到了簡(jiǎn)化,因?yàn)樵S多操作數(shù)從未到達(dá)那里。如果結(jié)果在產(chǎn)生后很快就被消耗,數(shù)據(jù)轉(zhuǎn)發(fā)允許結(jié)果完全跳過(guò)寄存器文件。在生產(chǎn)者和消費(fèi)者指令的目標(biāo)寄存器相同的情況下,生產(chǎn)者甚至可能根本不需要寫(xiě)回到寄存器文件,從而節(jié)省更多電力。這在功耗和面積方面都有好處,特別是在寄存器文件寫(xiě)入端口成本高昂的小工藝節(jié)點(diǎn)中。
這種轉(zhuǎn)變延伸到了 RISC-V 生態(tài)系統(tǒng),架構(gòu)師們正在探索時(shí)序透明的設(shè)計(jì),以避免推測(cè)執(zhí)行帶來(lái)的額外負(fù)擔(dān)。無(wú)論是應(yīng)用于人工智能推理、向量處理器還是特定領(lǐng)域的加速器,這種方法都能提供強(qiáng)大的冒險(xiǎn)處理能力,同時(shí)不犧牲清晰度、效率或正確性。
結(jié)論—— 架構(gòu)思維的轉(zhuǎn)變
幾十年來(lái),微處理器架構(gòu)師一直在平衡性能和正確性,應(yīng)對(duì)深度流水線和復(fù)雜指令依賴帶來(lái)的挑戰(zhàn)。傳統(tǒng)的亂序執(zhí)行機(jī)制依靠動(dòng)態(tài)調(diào)度和重排序緩沖區(qū),通過(guò)盡快執(zhí)行獨(dú)立指令(無(wú)論其原始順序如何)來(lái)最大限度地提高性能。雖然這種方法在利用指令級(jí)并行性方面很有效,但它帶來(lái)了能源開(kāi)銷、更高的復(fù)雜性和驗(yàn)證挑戰(zhàn),尤其是在深度流水線中。相比之下,雙行Scoreboard提供了精確的、周期精確的時(shí)序,不需要推測(cè)性重排序。它不是不可預(yù)測(cè)地重新排列指令,而是在發(fā)布前確保可用性,在保持吞吐量的同時(shí)減少控制開(kāi)銷。
事后看來(lái),Scoreboard不僅僅是一種控制機(jī)制,更是一種思考執(zhí)行時(shí)序的新方式。它不是預(yù)測(cè)未來(lái),而是確保系統(tǒng)精確地滿足未來(lái)—— 這一原則在今天仍然像它最初構(gòu)想時(shí)一樣具有現(xiàn)實(shí)意義。隨著現(xiàn)代計(jì)算向更具確定性和能效的架構(gòu)發(fā)展,將時(shí)間作為首要的架構(gòu)概念已不再只是理想,而是必不可少的。
關(guān)鍵詞: Scoreboard 記分板 Scoreboard機(jī)制

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章