AMD大躍進(jìn):未來4年,能效提高30倍!
2021-09-30 12:21:31 EETOP編譯自tomshardware
AMD 今天宣布了一個(gè)極其雄心勃勃的目標(biāo):到 2025 年將其 EPYC CPU 和 Instinct GPU 加速器的能效提高 30 倍。AMD 自己也知道這是一個(gè)多么崇高的目標(biāo):該目標(biāo)比典型的全行業(yè)效率提高 150%。
AMD 的新舉措緊隨其 2014 年至 2020 年的 20x25 計(jì)劃之后,在此期間該公司的筆記本電腦芯片的能效提高了 25 倍(特別是,這包括處理器空閑和負(fù)載時(shí)的效率)。
AMD 的新計(jì)劃專門針對(duì) AI 和 HPC 工作負(fù)載,該公司的目標(biāo)可能暗示其未來的硬件設(shè)計(jì)計(jì)劃。例如,AMD 計(jì)劃在努力實(shí)現(xiàn)新的功耗目標(biāo)時(shí)提高性能,但它并不只是想在性能問題上投入更多的裸片面積(即更大的芯片)。相反,他們的想法是同步提高性能和每瓦性能,以實(shí)現(xiàn)性能和效率的提升。
與任何目標(biāo)一樣,AMD 必須有一種方法來衡量其實(shí)現(xiàn)目標(biāo)的進(jìn)度。鑒于該公司專注于 AI 和 HPC 工作負(fù)載的性能,AMD 選擇了 FP16 或 BF16 FLOPS(具有 4k 矩陣大小的 Linpack DGEMM 內(nèi)核 FLOPS),這意味著它使用通常用于 AI 訓(xùn)練工作負(fù)載的數(shù)據(jù)類型。
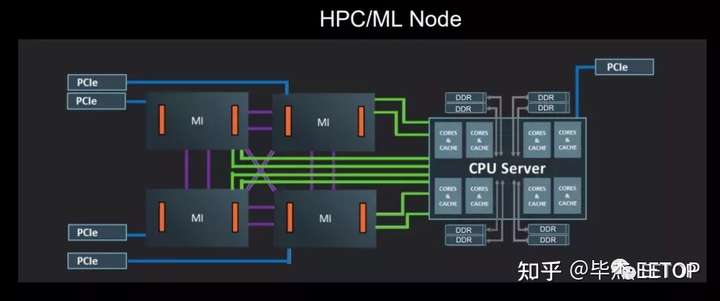
AMD 使用具有四個(gè) MI60 GPU 和一個(gè) EPYC CPU(未指定型號(hào))的現(xiàn)有系統(tǒng)(計(jì)算節(jié)點(diǎn))的總體性能設(shè)定了基準(zhǔn)性能測(cè)量。這已被定義為基準(zhǔn)“2020 系統(tǒng)”。AMD 將使用具有相同數(shù)量 GPU 和 CPU 的新一代服務(wù)器節(jié)點(diǎn)來衡量里程碑。重要的是要了解 AMD 只需為 BF16 和 FP16 數(shù)據(jù)類型添加固定功能(硬件級(jí))加速,就可以朝著其目標(biāo)邁出一大步,從而獲得相對(duì)“容易”的性能和效率提升。例如,MI60 支持 FP16,但不支持 BF16。


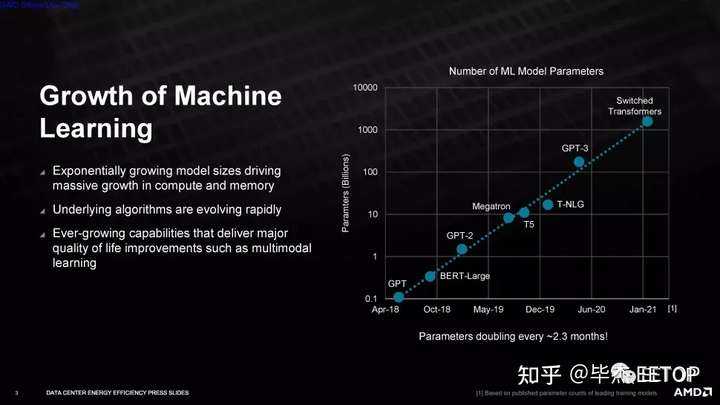
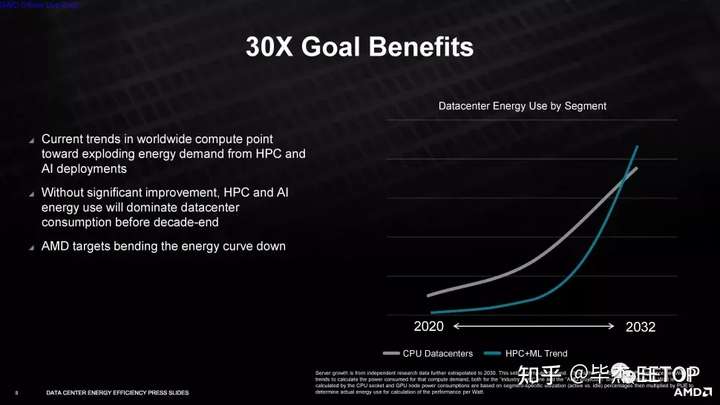
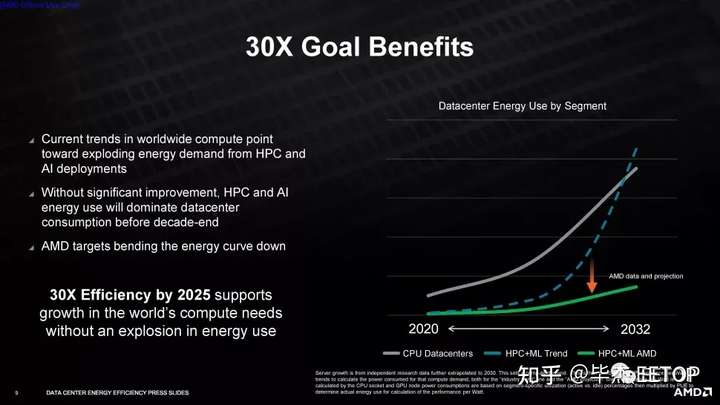
AMD 表示,它將依靠硬件和軟件優(yōu)化來實(shí)現(xiàn)其目標(biāo),但對(duì)我們?cè)诖诉^程中可以預(yù)期的硬件加速類型不置可否——該公司不會(huì)確認(rèn)將添加固定功能的 BF16加速其 CPU 和 GPU。僅此添加就可以在目標(biāo)工作負(fù)載中產(chǎn)生令人印象深刻的性能提升。此外,軟件優(yōu)化通常會(huì)導(dǎo)致現(xiàn)有硬件的大規(guī)模改進(jìn),這意味著 AMD 有多種選擇來實(shí)現(xiàn)其目標(biāo)。與 AMD 之前提高筆記本電腦效率的目標(biāo)不同,該公司并未將空閑功耗測(cè)量納入其測(cè)試方法。相反,公司將使用這些工作負(fù)載的典型利用率(約 90%)乘以數(shù)據(jù)中心PUE(電源使用效率 - 數(shù)據(jù)中心效率的衡量標(biāo)準(zhǔn))。AMD 表示,這產(chǎn)生的值與每瓦功率指標(biāo)非常接近,但我們還沒有看到該公司用于計(jì)算的最終公式。
AMD 的能效目標(biāo)是在對(duì)加速計(jì)算節(jié)點(diǎn)的處理需求大幅增加之后提出的,這些節(jié)點(diǎn)執(zhí)行人工智能訓(xùn)練、氣候預(yù)測(cè)、基因組學(xué)和大規(guī)模超級(jí)計(jì)算機(jī)模擬等功能。如果 AMD 實(shí)現(xiàn)其目標(biāo),該公司表示,這些系統(tǒng)的整體能耗將在五年內(nèi)驚人地降低 97%。
AMD 執(zhí)行副總裁兼首席技術(shù)官 MarkPapermaster表示:“提高處理器能效是 AMD 的長(zhǎng)期設(shè)計(jì)優(yōu)先事項(xiàng),我們現(xiàn)在正在為使用我們的高性能 CPU 和加速器的現(xiàn)代計(jì)算節(jié)點(diǎn)設(shè)定一個(gè)新目標(biāo),用于人工智能訓(xùn)練和高性能計(jì)算部署。專注于這些非常重要的細(xì)分市場(chǎng),以及領(lǐng)先公司加強(qiáng)環(huán)境管理的價(jià)值主張,AMD在這些領(lǐng)域的30倍目標(biāo)比前五年的行業(yè)能效表現(xiàn)高出150%。”
AMD 已經(jīng)在其 CPU 和 GPU 設(shè)計(jì)上探索了大量的能效改進(jìn) - 以至于 AMD Zen CPU 實(shí)際上在性能/瓦特比方面擊敗了英特爾。該公司還對(duì)其RDNA 2 GPU 的功耗進(jìn)行了大幅改進(jìn),從Nvidia手中奪得了能源效率的桂冠。這些改進(jìn)的一部分可歸因于制造節(jié)點(diǎn)的跳躍,至少在 GPU 方面是這樣。然而,隨著更密集制造工藝的成本激增和研發(fā)時(shí)間的增加,AMD 顯然并不僅僅指望這些。
相反,諸如3D緩存堆疊(應(yīng)用于RDNA 2芯片的Infinity Cache大大降低了功耗)等技術(shù)和越來越多的效率優(yōu)先的工程方法將被要求。固定功能加速和軟件改進(jìn)也將發(fā)揮很大作用。為了達(dá)到這一目標(biāo),AMD將尋求哪些技術(shù),還有待觀察,但令人鼓舞的是,該公司顯然相信它能夠在未來四年內(nèi)實(shí)現(xiàn)這種類型的改進(jìn)。

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章