IBM 近日提出的全新
芯片設(shè)計可以通過在數(shù)據(jù)存儲的位置執(zhí)行計算來加速全連接神經(jīng)網(wǎng)絡(luò)的訓(xùn)練。研究人員稱,這種「
芯片」可以達到
GPU 280 倍的能源效率,并在同樣面積上實現(xiàn) 100 倍的算力。該研究的論文已經(jīng)發(fā)表在上周出版的 Nature 期刊上。
用
GPU 運行神經(jīng)網(wǎng)絡(luò)的方法近年來已經(jīng)為
人工智能領(lǐng)域帶來了驚人的發(fā)展,然而兩者的組合其實并不完美。IBM 研究人員希望專門為神經(jīng)網(wǎng)絡(luò)設(shè)計一種新
芯片,使前者運行能夠更快、更有效。
直到本世紀初,研究人員才發(fā)現(xiàn)為電子游戲設(shè)計的圖形處理單元 (
GPU ) 可以被用作硬件加速器,以運行更大的神經(jīng)網(wǎng)絡(luò)。
因為這些
芯片可以執(zhí)行大量并行運算,而無需像傳統(tǒng)的
CPU 那樣按順序執(zhí)行。這對于同時計算數(shù)百個神經(jīng)元的權(quán)重來說特別有用,而今的
深度學(xué)習(xí)網(wǎng)絡(luò)則正是由大量神經(jīng)元構(gòu)成的。
雖然
GPU 的引入已經(jīng)讓
人工智能領(lǐng)域?qū)崿F(xiàn)了飛速發(fā)展,但這些
芯片仍要將處理和存儲分開,這意味著在兩者之間傳遞數(shù)據(jù)需要耗費大量的時間和精力。這促使人們開始研究新的存儲技術(shù),這種新技術(shù)可以在同一位置存儲和處理這些權(quán)重數(shù)據(jù),從而提高速度和能效。
這種新型存儲設(shè)備通過調(diào)整其電阻水平來以模擬形式存儲數(shù)據(jù),即以連續(xù)規(guī)模存儲數(shù)據(jù),而不是以數(shù)字存儲器的二進制 1 和 0。而且因為信息存儲在存儲單元的電導(dǎo)中,所以可以通過簡單地讓電壓通過所有存儲單元并讓系統(tǒng)通過物理方法來執(zhí)行計算。
但這些設(shè)備中固有的物理缺陷會導(dǎo)致行為的不一致,這意味著目前使用這種方式來訓(xùn)練神經(jīng)網(wǎng)絡(luò)實現(xiàn)的分類精確度明顯低于使用
GPU 進行計算。
負責(zé)該項目的 IBM Research 博士后研究員 Stefano Ambrogio 在此前接受 Singularity Hub 采訪時說:「我們可以在一個比
GPU 更快的系統(tǒng)上進行訓(xùn)練,但如果訓(xùn)練操作不夠精確,那就沒用。目前為止,還沒有證據(jù)表明使用這些新型設(shè)備和使用
GPU 一樣精確。」
但隨著研究的進展,新技術(shù)展現(xiàn)了實力。在上周發(fā)表在《自然》雜志上的一篇論文中(Equivalent-accuracy accelerated neural-network training using analogue memory),Ambrogio 和他的同事們描述了如何利用全新的模擬存儲器和更傳統(tǒng)的電子元件組合來制造一個
芯片,該
芯片在運行速度更快、能耗更少的情況下與
GPU 的精確度相匹配。
這些新的存儲技術(shù)難以訓(xùn)練深層神經(jīng)網(wǎng)絡(luò)的原因是,這個過程需要對每個神經(jīng)元的權(quán)重進行上下數(shù)千次的刺激,直到網(wǎng)絡(luò)完全對齊。Ambrogio 說,改變這些設(shè)備的電阻需要重新配置它們的原子結(jié)構(gòu),而這個過程每次都不相同。刺激的力度也并不總是完全相同,這導(dǎo)致神經(jīng)元權(quán)重不精確的調(diào)節(jié)。
研究人員創(chuàng)造了「突觸單元」來解決這個問題,每個單元都對應(yīng)網(wǎng)絡(luò)中的單個神經(jīng)元,既有長期記憶,也有短期記憶。每個單元由一對相變存儲器 ( PCM ) 單元和三個晶體管和一個電容器的組合構(gòu)成,相變存儲器單元將重量數(shù)據(jù)存儲在其電阻中,電容器將重量數(shù)據(jù)存儲為電荷。
PCM 是一種「非易失性存儲器」,意味著即使沒有外部
電源,它也保留存儲的信息,而電容器是「易失性的」,因此只能保持其電荷幾毫秒。但電容器沒有 PCM 器件的可變性,因此可以快速準確地編程。
當(dāng)神經(jīng)網(wǎng)絡(luò)經(jīng)過圖片訓(xùn)練后可以進行分類任務(wù)時,只有電容器權(quán)重被更新了。在觀察了數(shù)千張圖片之后,權(quán)重會被傳輸?shù)?PCM 單元以長期存儲。
PCM 的可變性意味著權(quán)重數(shù)據(jù)的傳遞可能仍然會存在錯誤,但因為單元只是偶爾更新,因此在不增加太多復(fù)雜性的情況下系統(tǒng)可以再次檢查導(dǎo)率。「如果直接在 PCM 單元上進行訓(xùn)練,就不可行了。」Ambrogio 表示。
為了
測試新設(shè)備,研究人員在一系列流行的圖像識別基準中訓(xùn)練了他們的神經(jīng)網(wǎng)絡(luò),并實現(xiàn)了與谷歌的神經(jīng)網(wǎng)絡(luò)框架 TensorFlow 相媲美的精確度。但更重要的是,他們預(yù)測最終構(gòu)建出的
芯片可以達到
GPU 280 倍的能源效率,并在同樣平方毫米面積上實現(xiàn) 100 倍的算力。
值得注意的是,研究人員目前還沒有構(gòu)建出完整的
芯片。在使用 PCM 單元進行
測試時,其他硬件組件是由計算機模擬的。Ambrogio 表示研究人員希望在花費大量精力構(gòu)建完整
芯片之前檢查方案的可行性。
他們使用了真實的 PCM 設(shè)備——因為這方面的模擬不甚可靠,而其他組件的模擬技術(shù)已經(jīng)成熟。研究人員對基于這種設(shè)計構(gòu)建完整
芯片非常有信心。
「它目前只能在全連接神經(jīng)網(wǎng)絡(luò)上與
GPU 競爭,在這種網(wǎng)絡(luò)中,每個神經(jīng)元都連接到前一層的相應(yīng)神經(jīng)元上,」Ambrogio 表示。「在實踐中,很多神經(jīng)網(wǎng)絡(luò)并不是全連接的,或者只有部分層是全連接的。」
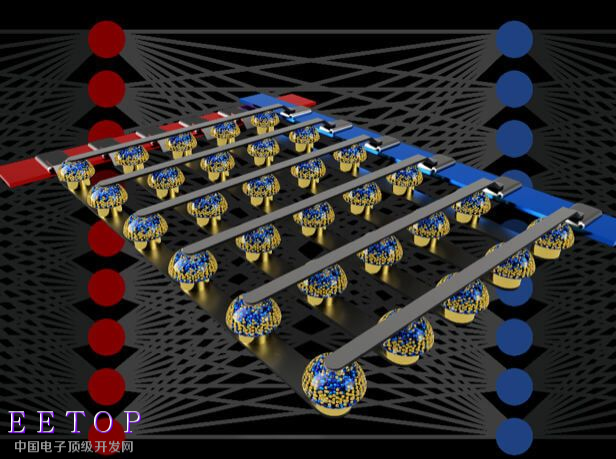
交叉開關(guān)非易失性存儲器陣列可以通過在數(shù)據(jù)位置執(zhí)行計算來加速全連接神經(jīng)網(wǎng)絡(luò)的訓(xùn)練。圖片來源:IBM Research
Ambrogio 認為最終的
芯片會被設(shè)計為與
GPU 協(xié)同工作的形式,以處理全連接層的計算,同時執(zhí)行其他任務(wù)。他還認為處理全連接層的有效方法可以被擴展到其它更廣泛的領(lǐng)域。
Ambrogio 表示主要有兩種方向的應(yīng)用:將
AI 引入個人設(shè)備,以及提高數(shù)據(jù)中心的運行效率。其中后者是科技巨頭關(guān)注的重點——這些公司的服務(wù)器運營成本一直居高不下。
在個人設(shè)備中直接實現(xiàn)
人工智能可以免去將數(shù)據(jù)傳向云端造成的隱私性顧慮,但 Ambrogio 認為其更具吸引力的優(yōu)勢在于創(chuàng)造個性化的
AI。
「在未來,神經(jīng)網(wǎng)絡(luò)應(yīng)用在你的手機和自動駕駛
汽車中也可以持續(xù)地學(xué)習(xí)經(jīng)驗,」他說道。「想象一下:你的電話可以和你交談,并且可以識別你的聲音并進行個性化;或者你的
汽車可以根據(jù)你的駕駛習(xí)慣進行個性化調(diào)整。」