谷歌TPU以時(shí)間換吞吐量;AlphaGo探索強(qiáng)化學(xué)習(xí)新起點(diǎn)
2017-11-24 09:30:18 n谷歌TPU:以時(shí)間換吞吐量,軟硬兼施,沖入云端
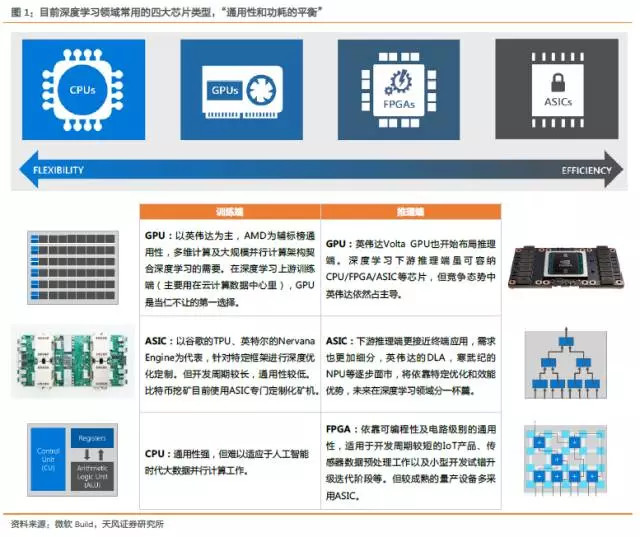
人工智能立夏將至的大趨勢(shì)下,芯片市場(chǎng)蛋糕越做越大,足以讓擁有不同功能和定位的芯片和平共存,百花齊放。后摩爾定律時(shí)代,我們強(qiáng)調(diào)AI芯片市場(chǎng)不是零和博弈。我們認(rèn)為在3-5年內(nèi)深度學(xué)習(xí)對(duì)GPU的需求是當(dāng)仁不讓的市場(chǎng)主流。行業(yè)由上至下傳導(dǎo)形成明顯的價(jià)值擴(kuò)張,英偉達(dá)和AMD最為受益。在深度學(xué)習(xí)上游訓(xùn)練端(主要用在云計(jì)算數(shù)據(jù)中心里),GPU是當(dāng)仁不讓的第一選擇,但以ASIC為底芯片的包括谷歌的TPU、寒武紀(jì)的MLU等,也如雨后春筍。而下游推理端更接近終端應(yīng)用,需求更加細(xì)分,我們認(rèn)為除了GPU為主流芯片之外,包括CPU/FPGA/ASIC等也會(huì)在這個(gè)領(lǐng)域發(fā)揮各自的優(yōu)勢(shì)特點(diǎn)。
但我們需要強(qiáng)調(diào),包括TPU在內(nèi)的ASIC仍然面臨通用性較弱,以及開發(fā)成本高企等局限。TPU雖然理論上支持所有深度學(xué)習(xí)開發(fā)框架,但目前只針對(duì)TensorFlow進(jìn)行了深度優(yōu)化。另外ASIC芯片開發(fā)周期長(zhǎng)和成本非常高,在開發(fā)調(diào)試過程中復(fù)雜的設(shè)計(jì)花費(fèi)有時(shí)甚至?xí)^億美元,因此需要谷歌這樣的計(jì)算需求部署量才能將成本分?jǐn)偟酱罅渴褂弥小M瑫r(shí)ASIC開發(fā)周期長(zhǎng),也可能會(huì)出現(xiàn)硬件開發(fā)無法匹配軟件更新?lián)Q代而失效的情況。
TPU是針對(duì)自身產(chǎn)品的人工智能負(fù)載打造的張量處理單元TPU。第一代主要應(yīng)用于在下游推理端TPU。本質(zhì)上沿用了脈動(dòng)陣列機(jī)架構(gòu)(systolic array computers),讓推理階段以時(shí)間換吞吐量。第二代TPU除了在推理端應(yīng)用,還可以進(jìn)行深度學(xué)習(xí)上游訓(xùn)練環(huán)節(jié)。將TPU部署在云計(jì)算中以云服務(wù)形式進(jìn)行銷售共享,在為數(shù)據(jù)中心加速市場(chǎng)帶來全新的需求體驗(yàn)的同時(shí),可進(jìn)一步激活中小企業(yè)的云計(jì)算需求市場(chǎng),另辟AWS、Azure之外蹊徑。
AlphaGo的“終點(diǎn)”,強(qiáng)化學(xué)習(xí)的起點(diǎn)
我們?cè)诮衲?月的報(bào)告《2017 MIT人工智能5大趨勢(shì)預(yù)測(cè):寒梅傲香春寒料峭,人工智能立夏將至》中提到第一大趨勢(shì)預(yù)測(cè):正向強(qiáng)化學(xué)習(xí)(Positive Reinforcement)正成為深度學(xué)習(xí)(Deep Learning)后研究應(yīng)用的最新熱點(diǎn)。
強(qiáng)化學(xué)習(xí)(Reinforcement Learning)的目的是嘗試解決對(duì)人類標(biāo)注樣本的依賴,并打破特定板塊和領(lǐng)域里的學(xué)習(xí)局限,向無監(jiān)督、通用型人工智能拓展。強(qiáng)化學(xué)習(xí)的靈感來自于動(dòng)物的學(xué)習(xí)方式。動(dòng)物能夠?qū)W會(huì)某些特定行為所導(dǎo)致的正面或負(fù)面結(jié)果(a positive or negative outcome)。按照這種方法,計(jì)算機(jī)可以通過試錯(cuò)法(trial and error)來與訓(xùn)練環(huán)境互動(dòng),包括sensory perception和rewards,來決定這一結(jié)果的行為相關(guān)聯(lián)。這使得計(jì)算機(jī)可以不通過具體指示或范例(explicit examples)去學(xué)習(xí)。
當(dāng)前人工智能主流應(yīng)用還是基于深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò),從針對(duì)特定任務(wù)的標(biāo)記數(shù)據(jù)中學(xué)習(xí),訓(xùn)練過程需要消耗大量人類標(biāo)注樣本。而在很多現(xiàn)實(shí)場(chǎng)景下,特定垂直領(lǐng)域的數(shù)據(jù)并不足以支持系統(tǒng)建構(gòu),我們認(rèn)為強(qiáng)化學(xué)習(xí)有機(jī)會(huì)成為下一個(gè)機(jī)器學(xué)習(xí)商業(yè)成功的驅(qū)動(dòng)力。
谷歌重申買入:人工智能巨頭新征途:云+YouTube+硬件
我們?cè)缭谀瓿跻呀?jīng)開始強(qiáng)調(diào),AI巨頭谷歌的新征途——云+YouTube+硬件。YouTube和云計(jì)算的巨大增長(zhǎng)動(dòng)力將是谷歌持續(xù)轉(zhuǎn)型的助推器: YouTube百般武藝沖勁十足,Q3廣告業(yè)務(wù)凈營(yíng)收增速回升至21%,移動(dòng)端積極轉(zhuǎn)型執(zhí)行力堅(jiān)決。長(zhǎng)期眼光看AI和Other Bets創(chuàng)新業(yè)務(wù)厚積薄發(fā):谷歌是人工智能的龍頭標(biāo)的,我們長(zhǎng)期看好語音識(shí)別和無人駕駛的發(fā)力。公司20日收盤價(jià)1035美元,根據(jù)彭博一致預(yù)期2018年EPS 40.15美元,給予30x PE,目標(biāo)價(jià)1200美元,重申“買入”評(píng)級(jí)。
風(fēng)險(xiǎn)提示:芯片開發(fā)周期過長(zhǎng),市場(chǎng)需求不達(dá)預(yù)期等。
1. 谷歌TPU:以時(shí)間換吞吐量,軟硬兼施,沖入云端
AI芯片市場(chǎng)蛋糕越做越大,足以讓擁有不同功能和定位的芯片和平共存,百家爭(zhēng)鳴非零和博弈。“通用性和功耗的平衡”——在深度學(xué)習(xí)上游訓(xùn)練端(主要用在云計(jì)算數(shù)據(jù)中心里),GPU是當(dāng)仁不讓的第一選擇,ASIC包括谷歌TPU、寒武紀(jì)MLU等也如雨后春筍。而下游推理端更接近終端應(yīng)用,需求更加細(xì)分,GPU主流芯片之外,包括CPU/FPGA/ASIC也會(huì)在這個(gè)領(lǐng)域發(fā)揮各自的優(yōu)勢(shì)特點(diǎn)。
但我們需要強(qiáng)調(diào),包括TPU在內(nèi)的ASIC仍然面臨通用性較弱,以及開發(fā)成本高企等局限。TPU雖然理論上支持所有深度學(xué)習(xí)開發(fā)框架,但目前只針對(duì)TensorFlow進(jìn)行了深度優(yōu)化。另外ASIC芯片開發(fā)周期長(zhǎng)和成本非常高,在開發(fā)調(diào)試過程中復(fù)雜的設(shè)計(jì)花費(fèi)有時(shí)甚至?xí)^億美元,因此需要谷歌這樣的計(jì)算需求部署量才能將成本分?jǐn)偟酱罅渴褂弥小M瑫r(shí)ASIC開發(fā)周期長(zhǎng),也可能會(huì)出現(xiàn)硬件開發(fā)無法匹配軟件更新?lián)Q代而失效的情況。
ASIC(Application Specific Integrated Circuit,專用集成電路):細(xì)分市場(chǎng)需求確定后,以TPU為代表的ASIC定制化芯片(或者說針對(duì)特定算法深度優(yōu)化和加速的DSA,Domain-Specific-Architecture),在確定性執(zhí)行模型(deterministic execution model)的應(yīng)用需求中發(fā)揮作用。我們認(rèn)為深度學(xué)習(xí)ASIC包括英特爾的Nervana Engine、WaveComputing的數(shù)據(jù)流處理單元、英偉達(dá)的DLA、寒武紀(jì)的NPU等逐步面市,將依靠特定優(yōu)化和效能優(yōu)勢(shì),未來在深度學(xué)習(xí)領(lǐng)域分一杯羹。
神經(jīng)網(wǎng)絡(luò)的兩個(gè)主要階段是訓(xùn)練(Training和Learning)和推理(Inference和Prediction)。當(dāng)前幾乎所有的訓(xùn)練階段都是基于浮點(diǎn)運(yùn)算的,需要進(jìn)行大規(guī)模并行張量或多維向量計(jì)算,GPU依靠?jī)?yōu)秀的通用型和并行計(jì)算優(yōu)勢(shì)成為廣為使用的芯片。
在推理階段,由于更接近終端應(yīng)用需求,更關(guān)注響應(yīng)時(shí)間而不是吞吐率。由于CPU和GPU結(jié)構(gòu)設(shè)計(jì)更注重平均吞吐量(throughout)的time-varying優(yōu)化方式,而非確保延遲性能。谷歌設(shè)計(jì)了一款為人工智能運(yùn)算定制的硬件設(shè)備,張量處理單元(Tensor Processing Unit, TPU)芯片,并在2016年5月的I/O大會(huì)上正式展示。
第一代TPU的確定性執(zhí)行模型(deterministic execution model)針對(duì)特定推理應(yīng)用工作,更好的匹配了谷歌神經(jīng)網(wǎng)絡(luò)在推理應(yīng)用99%的響應(yīng)時(shí)間需求。第一代TPU是在一顆ASIC芯片上建立的專門為機(jī)器學(xué)習(xí)和TensorFlow量身打造的集成芯片。該芯片從2015年開始就已經(jīng)在谷歌云平臺(tái)數(shù)據(jù)中心使用,谷歌表示TPU能讓機(jī)器學(xué)習(xí)每瓦特性能提高一個(gè)數(shù)量級(jí),相當(dāng)于摩爾定律中芯片效能往前推進(jìn)了七年或者三代。
谷歌表示,這款芯片目前不會(huì)開放給其他公司使用,而是專門為TensorFlow所準(zhǔn)備。TPU的主要特點(diǎn)是:
1、從硬件層面適配TensorFlow深度學(xué)習(xí)系統(tǒng),是一款定制的ASIC芯片,谷歌將TPU插放入其數(shù)據(jù)中心機(jī)柜的硬盤驅(qū)動(dòng)器插槽里來使用;
2、數(shù)據(jù)的本地化,減少了從存儲(chǔ)器中讀取指令與數(shù)據(jù)耗費(fèi)的大量時(shí)間;
3、芯片針對(duì)機(jī)器學(xué)習(xí)專門優(yōu)化,尤其對(duì)低運(yùn)算精度的容忍度較高,這就使得每次運(yùn)算所動(dòng)用的晶體管數(shù)量更少,在同時(shí)間內(nèi)通過芯片完成的運(yùn)算操作也會(huì)更多。研究人員就可以使用更為強(qiáng)大的機(jī)器學(xué)習(xí)模型來完成快速計(jì)算。
自2016年以來,TPU運(yùn)用在人工智能搜索算法RankBrain、搜索結(jié)果相關(guān)性的提高、街景Street View地圖導(dǎo)航準(zhǔn)確度提高等方面。在I/O大會(huì)上,皮查伊順帶提到了16年3月份行的舉世矚目人機(jī)大戰(zhàn)里,在最終以4:1擊敗圍棋世界冠軍李世石的AlphaGo身上,谷歌也使用了TPU芯片。
谷歌把:
1、2015年擊敗初代擊敗樊麾的版本命名為AlphaGo Fan,這個(gè)版本的AlphaGo運(yùn)行于谷歌云,分布式機(jī)器使用了1202個(gè)CPU和176個(gè)GPU。
2、去年擊敗李世石的版本AlphaGo Lee則同樣運(yùn)行于云端,但處理芯片已經(jīng)簡(jiǎn)化為48個(gè)第一代TPU。
3、今年擊敗柯潔的Master以及最新版本Zero則通過單機(jī)運(yùn)行,只在一個(gè)物理服務(wù)器上部署了4個(gè)第一代TPU。(AlphaGo的背后算法詳解,可參見我們此前的深度報(bào)告《谷歌人工智能:從HAL的太空漫游到AlphaGo,AI的春天來了》)
1.1. 谷歌以TPU為破局者,軟硬兼施,加速云端AI帝國(guó)
AI芯片領(lǐng)域數(shù)據(jù)中心市場(chǎng)空間巨大,我們看到市場(chǎng)主流GPU之外,谷歌破局者之態(tài)依靠TPU2.0的浮點(diǎn)運(yùn)算升級(jí)自下而上進(jìn)入云計(jì)算服務(wù)。谷歌當(dāng)下不直接銷售硬件,但將TPU部署在云計(jì)算中以云服務(wù)形式進(jìn)行銷售共享,在為數(shù)據(jù)中心加速市場(chǎng)帶來全新的需求體驗(yàn)的同時(shí),可進(jìn)一步激活中小企業(yè)的云計(jì)算需求市場(chǎng),另辟AWS、Azure之外蹊徑。我們長(zhǎng)期看好谷歌基于公司AIFirst戰(zhàn)略規(guī)劃打造AI開發(fā)軟硬件一體化開發(fā)帝國(guó)。
不過TPU雖然理論上支持所有深度學(xué)習(xí)開發(fā)框架,但目前只針對(duì)TensorFlow進(jìn)行了深度優(yōu)化。而英偉達(dá)GPU支持包括TensorFlow、Caffe等在內(nèi)所有主流AI框架。因此谷歌還在云計(jì)算平臺(tái)上提供基于英偉達(dá)TeslaV100 GPU加速的云服務(wù)。在開發(fā)生態(tài)方面,TensorFlow團(tuán)隊(duì)公布了TensorFlow Research Cloud云開發(fā)平臺(tái),向研究人員提供一個(gè)具有1000個(gè)云TPU的服務(wù)器集群,用來服務(wù)各種計(jì)算密集的研究項(xiàng)目。
1.2. 第一代TPU:脈動(dòng)陣列“獲新生”,以時(shí)間換吞吐量
第一代TPU面向的推理階段,由于更接近終端應(yīng)用需求,更關(guān)注響應(yīng)時(shí)間而不是吞吐率。相對(duì)于CPU和GPU結(jié)構(gòu)設(shè)計(jì)更注重平均吞吐量(throughout)的time-varying優(yōu)化方式,而非確保延遲性能。第一代TPU的確定性執(zhí)行模型(deterministic execution model)針對(duì)特定推理應(yīng)用工作,更好的匹配了谷歌神經(jīng)網(wǎng)絡(luò)在推理應(yīng)用上99%的響應(yīng)時(shí)間需求。由于TPU沒有任何存儲(chǔ)程序,僅執(zhí)行從主機(jī)發(fā)送的指令,這些功能的精簡(jiǎn)讓TPU有效減小芯片面積并降低功耗。
谷歌在今年4月的體系結(jié)構(gòu)頂會(huì)ISCA 2017上面,發(fā)布了一篇介紹TPU相關(guān)技術(shù)以及與其它硬件比較的論文,并被評(píng)為最佳論文。我們通過論文得以看到第一代TPU的設(shè)計(jì)思路以及性能比較。
第一代TPU從2015年開始就被使用在谷歌云計(jì)算數(shù)據(jù)中心的機(jī)器學(xué)習(xí)應(yīng)用中,面向的是推理階段。首先看性能比較(鑒于2016年以前大部分機(jī)器學(xué)習(xí)公司主要使用CPU進(jìn)行推理,谷歌在論文中TPU的比較對(duì)象產(chǎn)品為英特爾服務(wù)器級(jí)HaswellCPU和英偉達(dá)TeslaK80 GPU),谷歌表示:
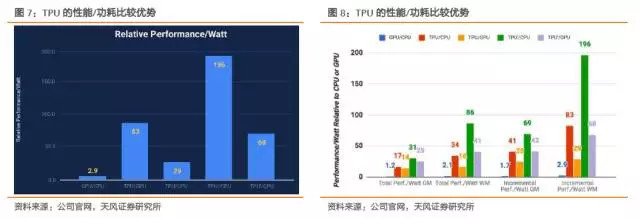
1、 針對(duì)自身產(chǎn)品的人工智能負(fù)載,推理階段,TPU處理速度比CPU和GPU快15-30倍;
2、 TPU的功耗效率(TOPS/Watt,萬億次運(yùn)算/瓦特)也較傳統(tǒng)芯片提升了30-80倍;
3、 基于TPU和TensorFlow框架的神經(jīng)網(wǎng)絡(luò)應(yīng)用代碼僅需100-1500行。
基于在成本-能耗-性能(cost-energy-performance)上的提升目標(biāo),TPU的設(shè)計(jì)核心是一個(gè)65,536(256x256)個(gè)8位MAC組成的矩陣乘法單元(MAC matrix multiply unit),可提供峰值達(dá)到92 TOPS的運(yùn)算性能和一個(gè)高達(dá)28 MiB的軟件管理片上內(nèi)存。TPU的主要設(shè)計(jì)者NormanJouppi表示,谷歌硬件工程團(tuán)隊(duì)最開始考慮過FPGA的方案,實(shí)現(xiàn)廉價(jià)、高效和高性能的推理解決方案。但是FPGA的可編程性帶來的是與ASIC相比在性能和每瓦特性能的巨大差異。
從上圖我們看到,TPU的核心計(jì)算部分是右上方的黃色矩陣乘法單元(Matrix Multiply unit),輸入部分是藍(lán)色的加權(quán)FIFO和一致緩沖區(qū)(Unified Buffer,輸出部分是藍(lán)色的累加器(Accumulators)。在芯片布局圖中我們看到,藍(lán)色的緩存的面積占37%,黃色的計(jì)算部分占30%,紅色的控制區(qū)域只占2%,一般CPU、GPU的控制部分會(huì)更大而且難以設(shè)計(jì)。
我們深挖谷歌TPU論文,在參考文獻(xiàn)中提及了谷歌申請(qǐng)的專利,核心的專利Neural Network Processor作為總構(gòu)架在2015年就已提交,并在2016年公開(后續(xù)專利在2017年4月公開,專利號(hào):US2017/0103313,即下圖12所示),同時(shí)還包括了幾個(gè)后續(xù)專利:如何在該構(gòu)架上進(jìn)行卷積運(yùn)算、矢量處理單元的實(shí)現(xiàn)、權(quán)重的處理、數(shù)據(jù)旋轉(zhuǎn)方法以及Batch處理等。
專利摘要概述:一種可以在多網(wǎng)絡(luò)層神經(jīng)網(wǎng)絡(luò)中執(zhí)行神經(jīng)網(wǎng)絡(luò)計(jì)算的電路,包括一個(gè)矩陣運(yùn)算單元(matrix computation unit):對(duì)多個(gè)神經(jīng)網(wǎng)絡(luò)層中的每一層,可以被配置為接收多個(gè)weights輸入和多個(gè)activation輸入,并對(duì)應(yīng)生成多個(gè)累積值;以及矢量運(yùn)算單元(vector computation unit),其通信耦合到所述矩陣運(yùn)算單元。
TPU的設(shè)計(jì)思路比GPU更接近一個(gè)浮點(diǎn)運(yùn)算單元,是一個(gè)直接連接到服務(wù)器主板的簡(jiǎn)單矩陣乘法協(xié)處理器。TPU上的DRAM是作為一個(gè)獨(dú)立的并行單元,TPU類似CPU、GPU一樣是可編程的,并不針對(duì)某一特定神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)的,而能在包括CNN、LSTM和大規(guī)模全連接網(wǎng)絡(luò)(large, fully connected models)上都執(zhí)行CISC指令。只是在編程性上TPU使用矩陣作為primitive對(duì)象,而不是向量或標(biāo)量。TPU通過兩個(gè)PCI-E3.0 x8邊緣連接器連接協(xié)處理器,總共有16GB/s的雙向帶寬。
我們看到,TPU的matrix單元就是一個(gè)典型的脈動(dòng)陣列架構(gòu)(systolic array computers)。weight由上向下流動(dòng),activation數(shù)據(jù)從左向右流動(dòng)。控制單元實(shí)際上就是把指令翻譯成控制信號(hào),控制weight和activation如何傳入脈動(dòng)陣列以及如何在脈動(dòng)陣列中進(jìn)行處理和流動(dòng)。由于指令比較簡(jiǎn)單,相應(yīng)的控制也是比較簡(jiǎn)單的。
從性能上,脈動(dòng)陣列架構(gòu)在大多數(shù)CNN卷積操作上效率很好,但在部分其他類型的神經(jīng)網(wǎng)絡(luò)操作上,效率不是太高。另外脈動(dòng)陣列架構(gòu)在上世紀(jì)80年代就已經(jīng)被提出,Simpleand regular design是脈動(dòng)陣列的一個(gè)重要原則,通過簡(jiǎn)單而規(guī)則的硬件架構(gòu),提高芯片的設(shè)計(jì)和實(shí)現(xiàn)的能力,從而盡量發(fā)揮軟件的能力,并平衡運(yùn)算和I/O的速度。脈動(dòng)陣列解決了傳統(tǒng)計(jì)算系統(tǒng):數(shù)據(jù)存取速度往往大大低于數(shù)據(jù)處理速度的問題,通過讓一系列在網(wǎng)格中規(guī)律布置的處理單元(ProcessingElements, PE),進(jìn)行多次重用輸入數(shù)據(jù)來在消耗較小的帶寬的情況下實(shí)現(xiàn)較高的運(yùn)算吞吐率。但是脈動(dòng)陣列需要帶寬的成比例的增加來維持所需的加速倍數(shù),所以可擴(kuò)展性問題仍待解決。
對(duì)比GPU的硬件架構(gòu),英偉達(dá)的游戲顯卡GeForce GTX 1070 Ti使用的是Pascal架構(gòu)16納米制程,主頻1,607MHz,擁有2,432個(gè)CUDA核心和152個(gè)紋理單元,2MB L2 cache,功耗180 W,8GB GDDR5內(nèi)存。英偉達(dá)GPU的核心計(jì)算單元CUDA核心專為同時(shí)處理多重任務(wù)而設(shè)計(jì),數(shù)千個(gè)CUDA核心組成了GPU的大規(guī)模并行計(jì)算架構(gòu)。而在計(jì)算過程中,主要計(jì)算流程為:
1)從主機(jī)內(nèi)存將需要處理的數(shù)據(jù)read到GPU的內(nèi)存;
2)CPU發(fā)送數(shù)據(jù)處理執(zhí)行給GPU;
3)GPU執(zhí)行并行數(shù)據(jù)處理;
4)將結(jié)果從GPU內(nèi)存write到主機(jī)內(nèi)存。通過編譯優(yōu)化把計(jì)算并行化分配到GPU的多個(gè)core里面,大大提高了針對(duì)一般性通用需求的大規(guī)模并發(fā)編程模型的計(jì)算并行度。
1.3. 第二代TPU:可進(jìn)行深度學(xué)習(xí)上游訓(xùn)練計(jì)算
第二代TPU,又名Cloud TPU,能夠同時(shí)應(yīng)用于高性能計(jì)算和浮點(diǎn)計(jì)算,峰值性能達(dá)到180 TFLOPS/s。與第一代TPU只能應(yīng)用于推理不同,第二代TPU還可以進(jìn)行深度學(xué)習(xí)上游訓(xùn)練環(huán)節(jié)。隨著第二代TPU部署在Google Compute Engine云計(jì)算引擎平臺(tái)上,谷歌將TPU真正帶入云端。
谷歌在今年5月17日舉辦了2017年度I/O開發(fā)者大會(huì)。一場(chǎng)并未有太多亮點(diǎn)的大會(huì)上,谷歌CEO皮查伊繼續(xù)強(qiáng)調(diào)公司AI First的傳略規(guī)劃。最為振奮人心的當(dāng)屬第二代TPU——Cloud TPU的發(fā)布。
谷歌同時(shí)發(fā)布了TPU Pod,由64臺(tái)第二代TPU組成,算力達(dá)11.5 petaflops。谷歌表示1/8個(gè)TPU Pod在對(duì)一個(gè)大型機(jī)器翻譯模型訓(xùn)練的只需要6個(gè)小時(shí),訓(xùn)練速度是市面上32塊性能最好的GPU的4倍。
谷歌此前強(qiáng)調(diào),第一代TPU是一款推理芯片,并不用作神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練階段,訓(xùn)練學(xué)習(xí)階段的工作仍需交由GPU完成。早在去年I/O大會(huì)上公布TPU之前,谷歌就已經(jīng)將TPU應(yīng)用在各領(lǐng)域任務(wù)中,包括:圖像搜索、街景、谷歌云視覺API、谷歌翻譯、搜索結(jié)果優(yōu)化以及AlphaGo的圍棋系統(tǒng)中。
而這次第二代TPU的升級(jí),自下而上的進(jìn)入深度學(xué)習(xí)上游,應(yīng)用在圖像和語音識(shí)別,機(jī)器翻譯和機(jī)器人等領(lǐng)域,加速對(duì)單個(gè)大型機(jī)器學(xué)習(xí)模型的訓(xùn)練。第二代TPU在左右兩側(cè)各有四個(gè)對(duì)外接口,左側(cè)還有兩個(gè)額外接口,未來可能允許TPU芯片直接連接存儲(chǔ)器,或者是高速網(wǎng)絡(luò),實(shí)現(xiàn)更加復(fù)雜的運(yùn)算以及更多的擴(kuò)展功能。在半精度浮點(diǎn)數(shù)(FP16)情況下,第二代TPU的單芯片可以達(dá)到45Teraflops(每秒萬億次的浮點(diǎn)運(yùn)算),4芯片的設(shè)計(jì)能達(dá)到180 Teraflops。(對(duì)比第一代TPU算力:8位整數(shù)運(yùn)算達(dá)92TOPS,16位整數(shù)運(yùn)算達(dá)23TOPS)
對(duì)TPU Pod的結(jié)構(gòu)進(jìn)行簡(jiǎn)要分析,四機(jī)架的鏡像結(jié)構(gòu)包含64個(gè)CPU板和64個(gè)第二代TPU板,The Next Platform推測(cè)CPU板是標(biāo)配英特爾Xeon雙插槽主板,因此整個(gè)Pod機(jī)柜包括128個(gè)CPU芯片和256個(gè)TPU芯片。
The Next Platform認(rèn)為,谷歌使用兩條OPA線纜將每塊CPU板一一對(duì)應(yīng)連接至TPU板,使得TPU與CPU的使用比例為2:1,這種TPU加速器與處理器之間高度耦合的結(jié)構(gòu),與典型的深度學(xué)習(xí)加速結(jié)構(gòu)中GPU加速器4:1或6:1的比例不太一樣,更強(qiáng)調(diào)了TPU作為協(xié)處理器的設(shè)計(jì)理念——CPU處理器還是需要完成大量的計(jì)算工作,只是把矩陣計(jì)算的的任務(wù)卸載到TPU中完成。
1.4. 谷歌重申買入:人工智能巨頭新征途:云+YouTube+硬件
我們?cè)缭谀瓿跻呀?jīng)開始強(qiáng)調(diào),人工智能巨頭新征途——云+YouTube+硬件。YouTube & 云計(jì)算的巨大增長(zhǎng)動(dòng)力將是谷歌持續(xù)轉(zhuǎn)型的助推器,長(zhǎng)期看好AI和OtherBets創(chuàng)新業(yè)務(wù)厚積薄發(fā)。
3Q17營(yíng)收277.7億美元,同比漲24%,高于華爾街預(yù)期219億美元,主要鑒于移動(dòng)端廣告搜索業(yè)務(wù)和YouTube的增長(zhǎng)。EPS9.57美元,高于預(yù)期8.31美元。廣告業(yè)務(wù)營(yíng)收240.7億美元,同比漲21%,其他業(yè)務(wù)包括云計(jì)算和硬件銷售達(dá)34.1億美元,同比大漲40%(尚未囊括10月發(fā)布的Pixel2等新產(chǎn)品銷售收入)。新興業(yè)務(wù)OtherBets營(yíng)收同比漲53%至3.02億美元,但虧損環(huán)比略漲至8.12億美元。
核心廣告指標(biāo)Cost per click實(shí)現(xiàn)環(huán)比轉(zhuǎn)正,移動(dòng)端轉(zhuǎn)型之勢(shì)給予市場(chǎng)極大信心。谷歌股價(jià)3季度跑輸大盤,外部壓力包括歐盟審查、美國(guó)選舉操控等輿論監(jiān)管壓力。我們認(rèn)為雖然在情緒面上承壓,但對(duì)公司業(yè)績(jī)基本面影響有限。根據(jù)彭博一致預(yù)期2018年EPS40.15美元,給予30xPE,目標(biāo)價(jià)1200美元,重申“買入”評(píng)級(jí)。
YouTube百般武藝沖勁十足,移動(dòng)端積極轉(zhuǎn)型執(zhí)行力堅(jiān)決
YouTube成長(zhǎng)繼續(xù)保持蓬勃?jiǎng)恿Γ琍ichai表示用戶通過電視觀看YouTube的總時(shí)長(zhǎng)達(dá)到1億小時(shí)/日,同比劇增70%。YouTubeTV網(wǎng)絡(luò)電視服務(wù)超過30個(gè)城市,包括40個(gè)電視臺(tái)節(jié)目的打包訂閱費(fèi)35美元/月,僅為有線電視訂閱均價(jià)的一半。根據(jù)eMarketer預(yù)測(cè),2017年美國(guó)視頻廣告市場(chǎng)增速?gòu)?qiáng)勁,整體規(guī)模預(yù)計(jì)增長(zhǎng)23.7%至132.3億美元,YouTube作為龍頭將貢獻(xiàn)21.7%約28.7億美元。
廣告營(yíng)收向移動(dòng)設(shè)備轉(zhuǎn)移步伐扎實(shí),廣告業(yè)務(wù)凈營(yíng)收增速回升至21%,廣告業(yè)務(wù)指標(biāo)Cost per click同比降-18%,對(duì)比Q2的-23%和Q1的-19%,但16年以來環(huán)比首現(xiàn)轉(zhuǎn)正。Paidclicks同比漲47%,對(duì)比Q2的52%和Q1的44%,自由網(wǎng)站尤其是YouTube極大拉動(dòng)用戶點(diǎn)擊意愿。我們強(qiáng)調(diào),在移動(dòng)端獲取搜索流量的成本會(huì)高于PC端,谷歌需要向包括iPhone在內(nèi)的合作伙伴支付更多的流量獲取成本和收入分成,谷歌已證明在移動(dòng)廣告上擁有不遜于Facebook的市場(chǎng)執(zhí)行力。
谷歌是人工智能的龍頭標(biāo)的
我們長(zhǎng)期看好人工智能,發(fā)力語音識(shí)別和無人駕駛:我們認(rèn)為語音識(shí)別技術(shù)已經(jīng)足夠進(jìn)入普及。DeepMind成為谷歌AI的標(biāo)簽門面,看好進(jìn)一步實(shí)現(xiàn)前瞻AI技術(shù)與現(xiàn)有業(yè)務(wù)的有效整合。
C端谷歌軟硬兼施,Pixel手機(jī)+Home音箱+AssistantAI助理打造AI生態(tài)圈,探索人機(jī)交互便捷方式和廣告業(yè)務(wù)協(xié)同效應(yīng)。9月以11億美元收購(gòu)HTC打造Pixel手機(jī)的團(tuán)隊(duì)。無人駕駛業(yè)務(wù)Waymo初試共享經(jīng)濟(jì),領(lǐng)投Lyft把握用戶入口將成為未來布局關(guān)鍵。
2. 初代AlphaGo原理簡(jiǎn)介
我們?cè)诮衲?月的《谷歌人工智能深度解剖》報(bào)告中詳細(xì)介紹過AlphaGo的程序原理。簡(jiǎn)單來說,AlphaGo的算法基于兩個(gè)不同的部分:蒙特卡洛樹搜索和指導(dǎo)樹搜索的卷積神經(jīng)網(wǎng)絡(luò)。與以前的蒙特卡洛程序不同,AlphaGo使用了深度神經(jīng)網(wǎng)絡(luò)來指導(dǎo)它的樹搜索。卷積神經(jīng)網(wǎng)絡(luò)分為“策略網(wǎng)絡(luò)”(這個(gè)網(wǎng)絡(luò)又分為“監(jiān)督學(xué)習(xí)”和“強(qiáng)化學(xué)習(xí)”兩種模式)和“價(jià)值網(wǎng)絡(luò)”。這兩個(gè)神經(jīng)網(wǎng)絡(luò)以當(dāng)前圍棋盤面為初始值,以圖片的形式輸入系統(tǒng)中。
這里面的“策略網(wǎng)絡(luò)”用來預(yù)測(cè)下一步落子并縮小搜索范圍至最有可能獲勝的落子選擇。“價(jià)值網(wǎng)絡(luò)”則用來減少搜索樹的深度——對(duì)每一步棋局模擬預(yù)測(cè)至結(jié)束來判斷是否獲勝。與此前的蒙特卡洛模擬程序不同的是,AlphaGo使用了深度神經(jīng)網(wǎng)絡(luò)來指導(dǎo)搜索。在每一次模擬棋局中,策略網(wǎng)絡(luò)提供落子選擇,而價(jià)值網(wǎng)絡(luò)則實(shí)時(shí)判斷當(dāng)前局勢(shì),綜合后選擇最有可能獲勝的落子。
下圖是我們經(jīng)過仔細(xì)研究DeepMind團(tuán)隊(duì)在學(xué)術(shù)雜志《自然》上發(fā)表的論文原文,精心制作的AlphaGo系統(tǒng)原理圖解。
3. AlphaGo Zero的進(jìn)化:強(qiáng)化學(xué)習(xí),萬物歸零
谷歌DeepMind最近在Nature上發(fā)布AlphaGo最新論文,介紹了目前最強(qiáng)版本AlphaGo Zero,在沒有先驗(yàn)知識(shí)的前提下,僅通過強(qiáng)化學(xué)習(xí)(Reinforcement Learning)自我訓(xùn)練,將先前的兩個(gè)神經(jīng)網(wǎng)絡(luò):價(jià)值網(wǎng)絡(luò)和策略網(wǎng)絡(luò)整合為一個(gè)框架,僅通過3天的訓(xùn)練就以100:0的成績(jī)擊敗了曾經(jīng)戰(zhàn)勝李世石的AlphaGo版本。
我們認(rèn)為AlphaGo Zero的進(jìn)化是在圍棋這個(gè)非常細(xì)分的特定問題上做的算法極致優(yōu)化:
1、 AlphaGoZero只使用棋盤上的黑白棋子作為輸入,訓(xùn)練完全從隨機(jī)落子開始,而此前的AlphaGo版本均使用了少量人工標(biāo)注的特征。
2、 Zero背后的神經(jīng)網(wǎng)絡(luò)精簡(jiǎn)為一個(gè),此前AlphaGo使用的兩個(gè)神經(jīng)網(wǎng)絡(luò):價(jià)值網(wǎng)絡(luò)(Value Network)和策略網(wǎng)絡(luò)(Policy Network)被整合為一個(gè)框架。在這個(gè)神經(jīng)網(wǎng)絡(luò)中,Zero應(yīng)用了更簡(jiǎn)單的Monte-Carlo樹搜索,實(shí)現(xiàn)更高效的訓(xùn)練和評(píng)估。
3、 Zero沒有使用“走棋策略”(Rollouts),這是其他圍棋程序以及AlphaGo最初版本中使用的快速走棋策略(Fast Rollout Policy):進(jìn)行快速判斷較優(yōu)落子選擇,適當(dāng)權(quán)衡走棋質(zhì)量精準(zhǔn)度與速度。相反Zero引入了全新的強(qiáng)化學(xué)習(xí)算法來在訓(xùn)練回路(training loop)中做前向搜索(lookahead search)。極大地提高了棋力以及學(xué)習(xí)穩(wěn)定性。
算法的改善提升了AlphaGo系統(tǒng)的性能以及通用性,并極大地降低了系統(tǒng)能耗。谷歌把2015年初代擊敗樊麾的版本命名為AlphaGoFan,這個(gè)版本的AlphaGo運(yùn)行于谷歌云,分布式機(jī)器使用了1202個(gè)CPU和176個(gè)GPU。去年擊敗李世石的版本AlphaGoLee則同樣運(yùn)行于云端,但處理芯片已經(jīng)簡(jiǎn)化為48個(gè)第一代TPU。今年戰(zhàn)勝柯潔的AlphaGoMaster,運(yùn)算量只有上一代AlphaGoLee的十分之一,在單機(jī)上運(yùn)行,只在一個(gè)物理服務(wù)器上部署了4個(gè)第一代TPU。
4. 強(qiáng)化學(xué)習(xí):減少對(duì)數(shù)據(jù)樣本的依賴,里程碑后的新起點(diǎn)
AlphaGo與李世石的世紀(jì)大戰(zhàn),是人工智能領(lǐng)域,尤其是深度強(qiáng)化學(xué)習(xí)技術(shù)的一個(gè)里程碑。
當(dāng)前人工智能主流應(yīng)用還是基于深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò),從針對(duì)特定任務(wù)的標(biāo)記數(shù)據(jù)中學(xué)習(xí),訓(xùn)練過程需要消耗大量人類標(biāo)注樣本。在很多現(xiàn)實(shí)場(chǎng)景下,特定垂直領(lǐng)域的數(shù)據(jù)并不足以支持系統(tǒng)建構(gòu),因此嘗試解決對(duì)人類標(biāo)注樣本的依賴,包括強(qiáng)化學(xué)習(xí)、遷移學(xué)習(xí)(Transfer Learning)、多任務(wù)學(xué)習(xí)(Multi-task Learning)、零樣本學(xué)習(xí)(zero-shot learning)有機(jī)會(huì)成為下一個(gè)機(jī)器學(xué)習(xí)商業(yè)成功的驅(qū)動(dòng)力。
強(qiáng)化學(xué)習(xí)(Reinforcement Learning),就是智能系統(tǒng)從環(huán)境到行為映射的學(xué)習(xí)。人工智能的終極目標(biāo)是模仿人類大腦的思考操作,而強(qiáng)化學(xué)習(xí)的靈感則來自于動(dòng)物的學(xué)習(xí)方式。動(dòng)物能夠?qū)W會(huì)某些特定行為所導(dǎo)致的正面或負(fù)面結(jié)果(positive or negative outcome)。按照這種方法,計(jì)算機(jī)可以通過試錯(cuò)法(trial and error)來與訓(xùn)練環(huán)境互動(dòng),包括sensory perception和rewards,來決定這一結(jié)果的行為相關(guān)聯(lián)。這使得計(jì)算機(jī)可以不通過具體指示或范例(explicit examples)去學(xué)習(xí)。
其實(shí)強(qiáng)化學(xué)習(xí)理論已經(jīng)存在了數(shù)十年,但通過與大型深度神經(jīng)網(wǎng)絡(luò)的結(jié)合,讓我們真正獲得了解決復(fù)雜問題(如下圍棋)所需的能力。通過不懈的訓(xùn)練與測(cè)試,以及對(duì)以前比賽的分析,AlphaGo能夠?yàn)樽约赫页隽巳绾我月殬I(yè)棋手下棋的道路。
我們?cè)诮衲?月的報(bào)告《2017 MIT人工智能5大趨勢(shì)預(yù)測(cè):寒梅傲香春寒料峭,人工智能立夏將至》中提到第一大趨勢(shì)預(yù)測(cè):正向強(qiáng)化學(xué)習(xí)(Positive Reinforcement)正在成為深度學(xué)習(xí)(Deep Learning)之后研究應(yīng)用的最新熱點(diǎn)。雖然隨著Master戰(zhàn)勝柯潔,DeepMind宣布了AlphaGo的退役,但我們認(rèn)為AlphaGo的“終點(diǎn)”,正開啟了強(qiáng)化學(xué)習(xí)的起點(diǎn)。
4.1. 游戲中的人機(jī)互動(dòng)
從Atari到Labyrinth,從連續(xù)控制到移動(dòng)操作到圍棋博弈,DeepMind的深度強(qiáng)化學(xué)習(xí)智能系統(tǒng)在許多領(lǐng)域都表現(xiàn)出優(yōu)異的成績(jī)。人工智能的一大難題就是局限于在特定的板塊和領(lǐng)域里學(xué)習(xí)。DeepMind這個(gè)板塊和領(lǐng)域中性的學(xué)習(xí)算法能夠幫助不同的研究團(tuán)隊(duì)處理大規(guī)模的復(fù)雜數(shù)據(jù),在氣候環(huán)境、物理、醫(yī)藥和基因?qū)W研究領(lǐng)域推動(dòng)新的發(fā)現(xiàn),甚至能夠反過來輔助科學(xué)家更好的了解人類大腦的學(xué)習(xí)機(jī)制。
可以預(yù)期的是,強(qiáng)化學(xué)習(xí)將能夠在現(xiàn)實(shí)世界情景中得到更多的實(shí)用證明。過去一年中我們看到一些模擬環(huán)境(simulated environments)的推出,包括DeepMind的DQN、OpenAI的Universe以及著名的沙盒游戲《Minecraft》。這個(gè)游戲在2014年被微軟收購(gòu),目前微軟劍橋研究院的研究人員正通過這款游戲進(jìn)行游戲內(nèi)人與AI的互動(dòng)協(xié)作研究。
研究人員開發(fā)了一個(gè)Malmo項(xiàng)目,通過這個(gè)平臺(tái)使用人工智能控制Minecraft游戲里面的角色完成任務(wù)。這個(gè)項(xiàng)目被視為有效的強(qiáng)化學(xué)習(xí)訓(xùn)練平臺(tái)。通過特定的任務(wù)獎(jiǎng)勵(lì),人工智能能夠完成研究人員布置的游戲任務(wù),例如控制角色從一個(gè)布滿障礙物的房間的一頭走到另一頭。同時(shí),人工控制的角色還會(huì)在旁邊提供建議,進(jìn)行人與AI協(xié)作的測(cè)試。
4.1.1. DeepMind之DeepQ-Network (DQN)
DeepMind在2015年2月于《自然》上發(fā)表了一篇《人類控制水平的深度強(qiáng)化學(xué)習(xí)》的論文,描述了其開發(fā)的深度神經(jīng)網(wǎng)絡(luò)DeepQ-Network (DQN)將深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Networks)與強(qiáng)化學(xué)習(xí)(Reinforcement Learning)相結(jié)合的深度強(qiáng)化學(xué)習(xí)系統(tǒng)(DeepReinforcement Learning System)。Q-Network是脫離模型(model-free)的強(qiáng)化學(xué)習(xí)方法,常被用來對(duì)有限馬爾科夫決策過程(Markov decision process)進(jìn)行最優(yōu)動(dòng)作選擇決策。
谷歌設(shè)計(jì)的這個(gè)神經(jīng)網(wǎng)絡(luò)能夠完成雅達(dá)利(Atari)游戲機(jī)2600上一共49個(gè)游戲,從滾屏射擊游戲RiverRaid,拳擊游戲Boxing到3D賽車游戲Enduro等。令他們驚喜的是,DQN在所有游戲過程都可以使用同一套神經(jīng)網(wǎng)絡(luò)模型和參數(shù)設(shè)置,研究人員僅僅向神經(jīng)網(wǎng)絡(luò)提供了屏幕像素、具體游戲動(dòng)作以及游戲分?jǐn)?shù),不包含任何關(guān)于游戲規(guī)則的先驗(yàn)知識(shí)。
游戲結(jié)果顯示,DQN在一共49個(gè)游戲中的43個(gè)都戰(zhàn)勝了以往任何一個(gè)機(jī)器學(xué)習(xí)系統(tǒng),并且在超過半數(shù)的游戲中,達(dá)到了職業(yè)玩家水平75%的分?jǐn)?shù)水平。在個(gè)別游戲中,DQN甚至展現(xiàn)了強(qiáng)大的游戲策略并拿到了游戲設(shè)定的最高分?jǐn)?shù)。
雖然Atari游戲?yàn)?a href="http://www.xebio.com.cn/ai" target="_blank" class="keylink">深度學(xué)習(xí)系統(tǒng)提供了多樣性,但它們都還是二維動(dòng)畫層面的游戲。DeepMind最近開始把研究重心放在3D游戲中并開發(fā)了一套3D迷宮游戲Labyrinth進(jìn)行深度學(xué)習(xí)系統(tǒng)的訓(xùn)練。與之前類似,智能系統(tǒng)只獲得了在視場(chǎng)(field-of-view)中觀察到的即時(shí)像素輸入,需要找到迷宮地圖的正確寶藏路徑。
DQN作為第一個(gè)深度學(xué)習(xí)系統(tǒng),通過進(jìn)行端到端訓(xùn)練完成一系列有難度的任務(wù)。這樣的技術(shù)能夠有效運(yùn)用到谷歌的產(chǎn)品服務(wù)中,我們可以想象一下,以后用戶可以直接發(fā)出指令要求谷歌為他制定一個(gè)歐洲背包旅行計(jì)劃。
4.1.2. OpenAIUniverse:通用vs 具體
人工智能非牟利組織OpenAI去年推出了Universe。這是一個(gè)用于訓(xùn)練解決通用問題的AI基礎(chǔ)架構(gòu),能在幾乎所有的游戲、網(wǎng)站和其他應(yīng)用中衡量和訓(xùn)練AI通用智能水平的開源平臺(tái)。這是繼去年12月OpenAI發(fā)布可以用來開發(fā)強(qiáng)化學(xué)習(xí)算法的開發(fā)工具Gym之后,向通用型人工智能進(jìn)一步擴(kuò)展的新動(dòng)作。
OpneAI Universe的目標(biāo)是開發(fā)一個(gè)單一的AI智能體,使其能夠靈活運(yùn)用過去在Universe中的經(jīng)驗(yàn),快速在陌生和困難的環(huán)境中學(xué)習(xí)并獲得技能,這也是通往通用型人工智能的重要一步。目前,Universe包括了大約2600 種Atari 游戲,1000種flash 游戲和80 種瀏覽器環(huán)境,可供所有人用于訓(xùn)練人工智能系統(tǒng)。最近,Universe加入了游戲大作《GTA5》。用戶只需購(gòu)買正版游戲,即可使用Universe中的人工智能在游戲中的3D環(huán)境中縱橫馳騁。在Universe的新測(cè)試環(huán)境中,人工智能獲取視頻信息的幀數(shù)被限制在了8fps,環(huán)境信息和視角管理齊備。此次開源GTA5讓普林斯頓大學(xué)開發(fā)的自動(dòng)駕駛模擬測(cè)試平臺(tái)DeepDrive在GTA世界中進(jìn)行測(cè)試變得更加簡(jiǎn)便易行。
4.2. 更瘦、更綠的云計(jì)算數(shù)據(jù)中心
在2017年,我們預(yù)計(jì)看到強(qiáng)化學(xué)習(xí)更多的出現(xiàn)在自動(dòng)駕駛系統(tǒng)和工業(yè)機(jī)器人控制等方面。谷歌一直在致力于更瘦、更綠的云計(jì)算數(shù)據(jù)平臺(tái)。早在2014年,谷歌通過安裝智能溫度和照明控制以及采用先進(jìn)的冷卻技術(shù)而非機(jī)械冷卻器,最小化能量損失,使其數(shù)據(jù)中心的耗電量比全球數(shù)據(jù)中心平均水平的低50%。而且對(duì)比自己的數(shù)據(jù)中心,谷歌現(xiàn)在的數(shù)據(jù)處理性能是5年前的3.5倍,但能耗卻沒有提高。
如今,坐擁DeepMind的谷歌在很大程度上又走在世界前沿。DeepMind將強(qiáng)化學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)技術(shù)應(yīng)用到云計(jì)算數(shù)據(jù)中心的能源控制方面,通過獲取數(shù)據(jù)中心內(nèi)的傳感器收集的大量歷史數(shù)據(jù)(如溫度、功率、泵速、設(shè)定點(diǎn)等),首先在未來平均PUE(Power Usage Effectiveness,電力使用效率)值上訓(xùn)練神經(jīng)網(wǎng)絡(luò)系統(tǒng)。PUE是總建筑能源使用量與IT能源使用量的比率,是衡量數(shù)據(jù)中心能源效率的標(biāo)準(zhǔn)指標(biāo),而每一部?jī)x器可以受到幾十個(gè)變量的影響。通過不斷的模擬調(diào)整模型與參數(shù),使其接近最準(zhǔn)確預(yù)測(cè)的配置,提高設(shè)施的實(shí)際性能。團(tuán)隊(duì)訓(xùn)練兩個(gè)額外的深層神經(jīng)網(wǎng)絡(luò)集合,以預(yù)測(cè)未來一小時(shí)內(nèi)數(shù)據(jù)中心的溫度和壓力,模擬來自PUE模型的推薦行為。
通過18個(gè)月的模型研發(fā)與測(cè)試,DeepMind聯(lián)合谷歌云的研發(fā)團(tuán)隊(duì)成功為數(shù)據(jù)中心節(jié)省了40%的冷卻能耗以及15%的總能耗,其中一個(gè)試點(diǎn)已經(jīng)達(dá)到了PUE的最低點(diǎn),未來該技術(shù)的可能應(yīng)用于提高發(fā)電轉(zhuǎn)換效率、減少半導(dǎo)體生產(chǎn)的能量和用水量,或幫助提高生產(chǎn)設(shè)施的產(chǎn)量。機(jī)器學(xué)習(xí)為數(shù)據(jù)中心節(jié)省能源,減少了更多的碳排放。DeepMind和谷歌云計(jì)算團(tuán)隊(duì)計(jì)劃將這項(xiàng)成果開源出來,造福全世界的數(shù)據(jù)中心、工廠和大型建筑等,打造一個(gè)更綠色的世界。

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章