隱藏在AI中的系統級研發效率密碼:Machine Learning for Verification
2023-05-20 06:36:40 楊思超,芯華章研究院研究員為什么“AI+EDA”如此讓人向往?
當下大規模的芯片已經可以包含超過 100 億個晶體管,而芯片研發的生產效率(Gates/Day)卻沒有辦法保持同步的提升,兩者之間存在一定距離。有研究表明,驗證在某些項目中的耗時占比甚至超過70%,驗證的效率因此成為了關鍵中的關鍵。
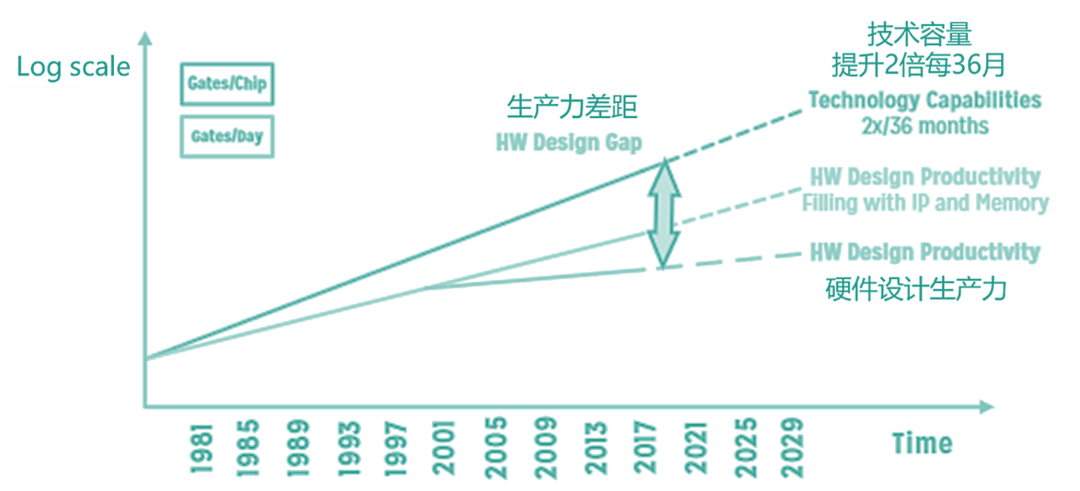
芯片規模和生產力的矛盾
另一個問題是成本。由于芯片的研發成本非常之高,單次研發失敗的概率理應被降到最低,驗證的重要性自然不言而喻。因此現有EDA工具需要不斷創新,來提升設計和驗證效率。其中一個重要的創新技術點,就是引入數據驅動的方法來改進現有的算法和流程。
通常我們談論的人工智能(AI)技術,主要分為機器學習(ML)和深度學習(DL)兩種路徑。其中,機器學習技術是現有和EDA結合更緊密的方向。為什么是ML?簡單來說,ML技術就是利用基于統計或計算機理論的模型在歷史數據中發掘某種模式,然后在當前數據中識別是否存在該模式的技術。理論上,只要一個系統里存在無法被明確或精確定義的函數關系,又存在大量的觀測或實驗數據,就可以使用ML技術來學習。
而EDA領域里正好存在很多這樣的系統。特別是傳統的啟發式策略面對日益復雜的系統時,計算效率逐漸趨于瓶頸,大量數據無法得到有效利用,通過引入ML技術,歷史數據得到利用形成經驗知識,再結合現有的技術可以進一步加速問題的求解,就可以輔助研發人員做出更優更高效的決策。
AI如何融入EDA?
看起來,我們似乎已經找到了這條通往答案的隱秘路徑,但現實卻更為復雜。
出于技術的天然契合性,目前因為EDA后端的設計和制造涉及到的數據類型,天然地可以被表示為幾何圖形,因此非常適合把原本應用在圖像上的ML和DL技術做橫向的遷移。但是,前端設計以及驗證里的問題,通常都是布爾函數表達下的組合搜索問題,這一類問題是目前公認ML或者DL很難求解或者精度上還沒有能超越傳統方法的問題。
簡單來說,驗證的目的是——在有限時間內,盡可能完整地覆蓋到所有的系統狀態,同時,盡可能多的找出功能或性能上的錯誤(bug),并進行修復以確保系統的正確性。
我們可以依據其實現的方式,大致分為兩類——動態仿真和形式驗證。目前在仿真驗證里,關于融入AI的研究主要圍繞如何通過ML提升測試效率或調試效率;在形式驗證里則是圍繞提升底層SAT求解器效率或上層模型檢查效率的ML研究工作。
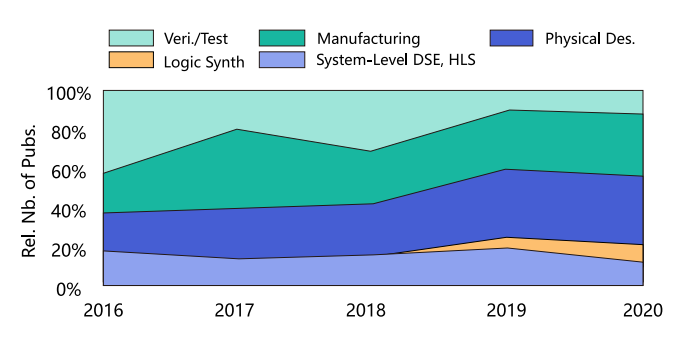
ML主題的文章里各細分領域的占比:
后端上的研究增加明顯
最大的挑戰來自?
EDA行業的標準流程經歷了幾十年的發展,相對完善,當前ML技術通常是作為一個傳統功能模塊的替代,而一個end2end的ML方案很難被接受,建模空間自然會受到限制。
一方面,ML模型的引入可能會導致數據安全和模型所屬權的問題。比如說客戶A的設計和供應商的IP可能會在不知情的情況下被ML模型學習到,再在模型提供服務的時候被客戶B使用。
另一方面,IC領域的發展迅速,每一代技術節點對應的設計與制程都不一樣,如何提高當前訓練的ML模型的有效期是必須面對的挑戰。
最后,數據有限、精度不高、解釋性不好等問題,依然在限制AI技術的應用。比如現在的AI技術很難給到用戶其預測結果的合理解釋,使得用戶對于其預測結果的信任度不高,特別是在IC研發這樣安全性要求非常高的領域,這一問題可能會被進一步放大。
系統級需求,驅動ML應用的三大方向
技術發展的挑戰,最終還是需要通過技術發展來解決。
未來ML的技術需要朝著 reusability + evolvability + Interpretability 的三大方向繼續發展,才能解決以上這些應用的痛點。同時,為了更好的支撐ML技術在驗證里的應用,我們應該倡導系統級別的協同設計,進而發展出對ML更為友好的基礎設施,例如:生成更可見、包含更多關系的數據,構建更適合于ML數據存放、使用和更新的數據倉庫,提供ML模型更多和EDA系統交互及請求的權限等。
作為撬動芯片及系統創新的關鍵杠桿,EDA近些年在智能化、自動化的方向上一路狂奔,但屬于這個領域的 “ChatGPT”或者 “AlphaGo”級別的突破,目前還沒有出現。
唯一可以確定的是,AI與EDA的創新融合,絕不是簡單形式上的增加,也不是擺在桌子上的自助餐,依然沒有可以完全依循的標準答案,而是存在于各個隱秘的角落,亟待產業與學界的深入探索。