被騰訊看中的人工智能芯片--DTU 1.0 亮相Hot Chips
2021-08-31 12:46:30 EETOP中國的頂級超級計(jì)算機(jī)--包括神威太湖之光或強(qiáng)大的天河 2A--都采用了本土技術(shù),從芯片到互連。而中國的社交媒體巨頭,包括阿里巴巴和百度,已經(jīng)在生產(chǎn)使用自研芯片的的設(shè)備,用于大規(guī)模的人工智能訓(xùn)練和推理。
作為BAT 之一的騰訊目前還沒有推出自己的芯片。但值得注意的是,騰訊對總部位于上海的燧原科技進(jìn)行了大量投資。
該公司很快將發(fā)布其第一代AI訓(xùn)練設(shè)備--DTU 1.0,該設(shè)備自2018年以來一直在開發(fā)中。在過去三年里,燧原科技已經(jīng)籌集了近5億美元的資金,由騰訊領(lǐng)頭。
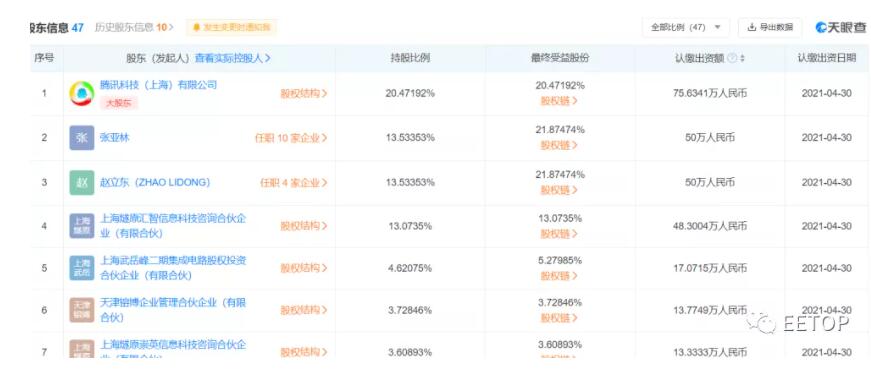
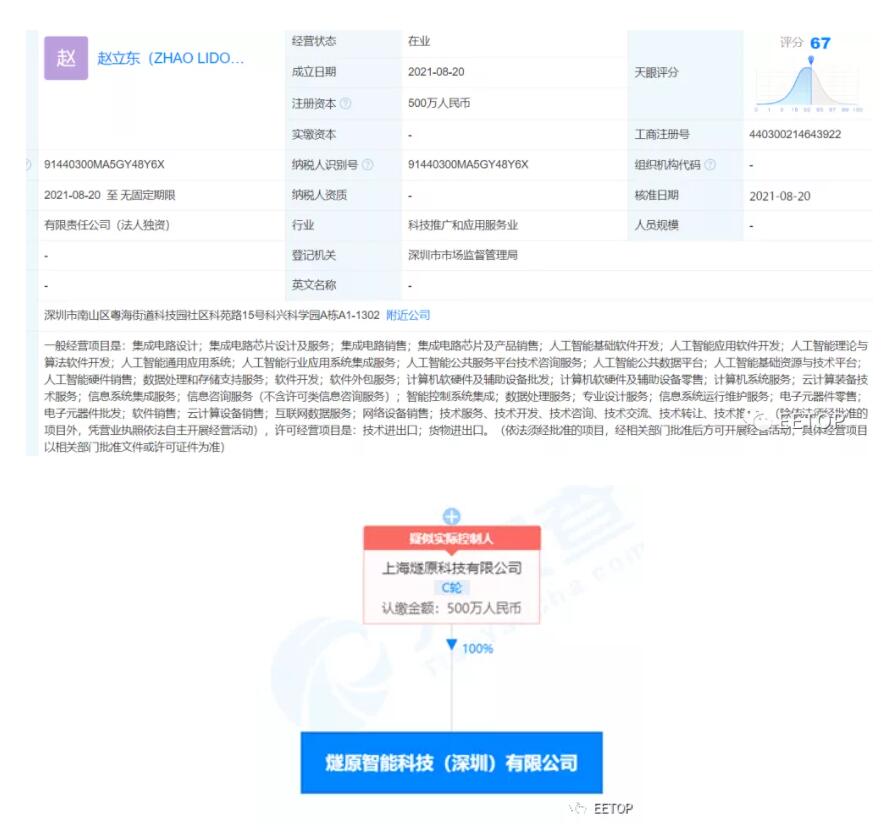
最新信息是從天眼查app獲悉,8月20日燧原智能科技(深圳)有限公司成立,業(yè)務(wù)范圍包括集成電路芯片設(shè)計(jì)等服務(wù)。由上海燧原科技有限公司全資持股。
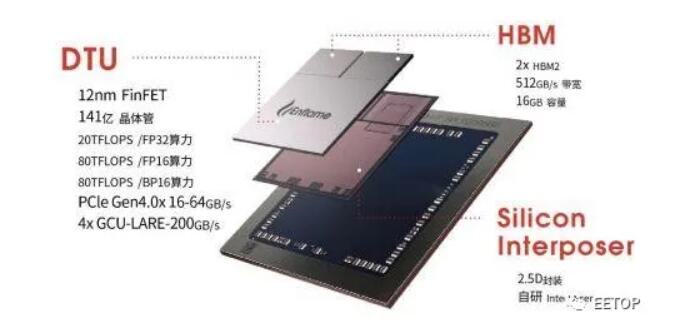
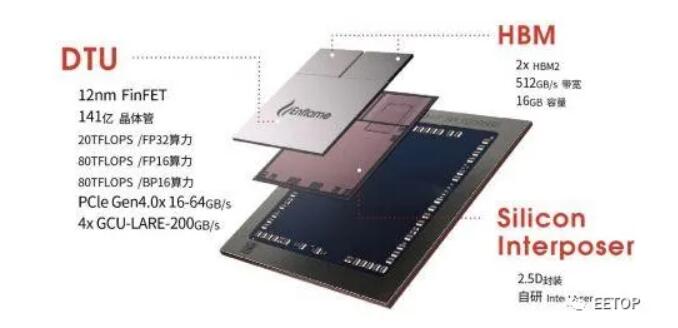
燧原科技第一代通用人工智能訓(xùn)練芯片“邃思1.0”封裝示意圖
我們真正想關(guān)心的問題是,對于大規(guī)模訓(xùn)練來說,這個芯片能做什么,而GPU卻做不到。答案可能很簡單,對于燧原科技最熱情的支持者騰訊來說,這可能是一項(xiàng)中國本土技術(shù)。騰訊需要效仿其百度、阿里等國內(nèi)同行,打造出(或通過收購)自己的國產(chǎn)人工智能硬件。
本周,我們終于在Hot Chips上看到了燧原科技基于12納米FinFET工藝的訓(xùn)練SOC。下面這個圖顯示了 32 個"人工智能計(jì)算核心 ",它們被分成四個集群。同時,還有另外四十個主機(jī)處理模塊沿著燧原科技自己的四個互連信道推送數(shù)據(jù)。每個設(shè)備有兩個 HBM2 模塊,帶寬為 512GB/秒。
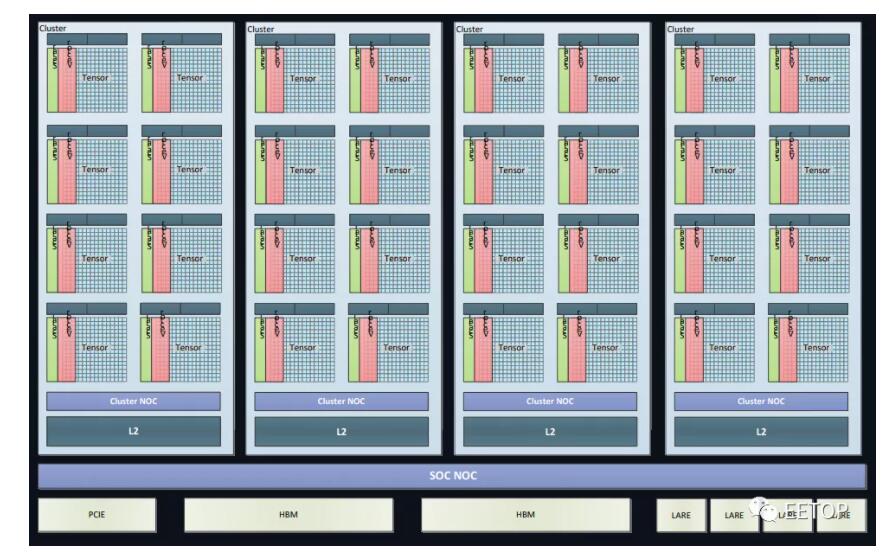
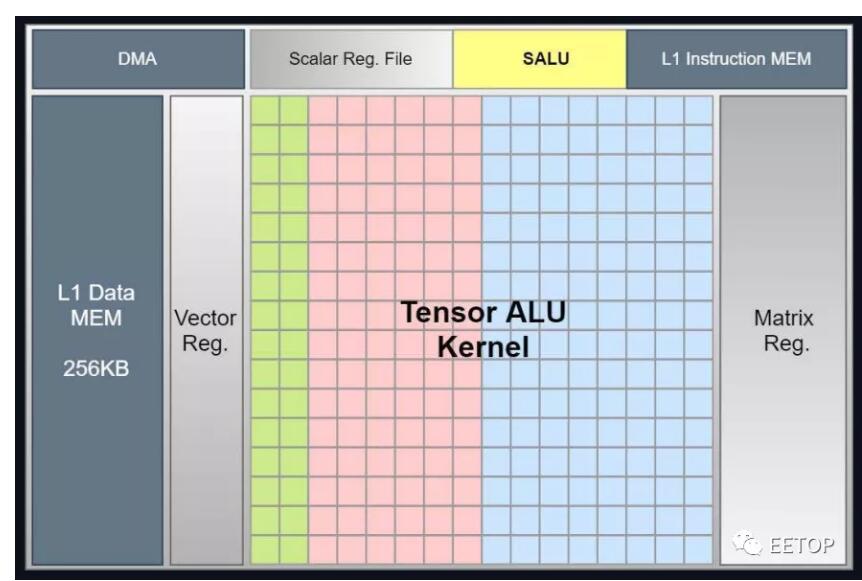
可以看出,燧原科技SoC的人工智能部分與我們以前從英偉達(dá)看到的TensorCore概念有很多共同之處,現(xiàn)在正被添加到其他幾個CPU的設(shè)計(jì)中。燧原科技表示,它們的器件可以在 FP32 下達(dá)到 20teraflops。該器件還支持 FP16 和 Bfloat(均達(dá)到 80 teraflops 的峰值),并且可以支持具有 Int-32、18 和 8 位數(shù)據(jù)類型的混合精度工作負(fù)載。其中每一個都基于一個 256 張量的計(jì)算內(nèi)核。
下面是張量單元的詳細(xì)介紹:
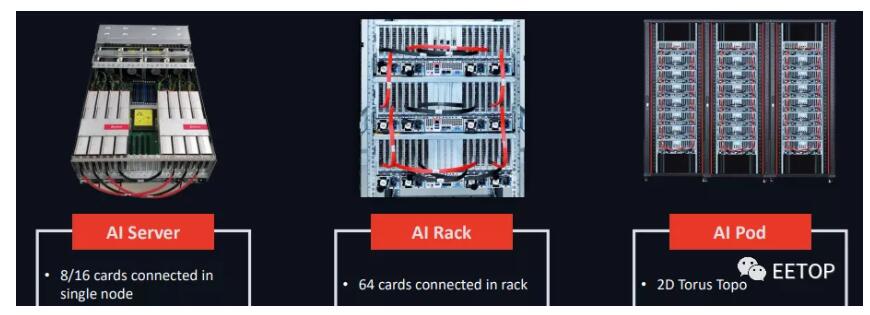
這家初創(chuàng)公司提供了一款名為云隧CloudBlazer的 PCIe Gen4 加速卡,根據(jù)配置的不同,功耗在 225W 到 300W 之間,其中功耗最大的是基于開放計(jì)算項(xiàng)目的 OAM(開放加速模型)設(shè)計(jì)的CloudBlazer T21。除了僅限 PCIe 的設(shè)備外,燧原科技還對系統(tǒng)進(jìn)行了封裝打包,從單個節(jié)點(diǎn)到機(jī)架,再到具有 2D 環(huán)面互連的“pod”。
燧原科技分享了各種配置的擴(kuò)展結(jié)果,顯示單卡在擴(kuò)展到 160 張卡時達(dá)到 81.6%,在打包到一個節(jié)點(diǎn)時達(dá)到 87.8%。這與我們在 GPU 可擴(kuò)展性方面所看到的大致相當(dāng),盡管它不是一個條件對等的比較。
EETOP獲悉,這家初創(chuàng)公司的創(chuàng)始人有著深厚的技術(shù)背景。該公司的首席執(zhí)行官兼聯(lián)合創(chuàng)始人趙立東在舊金山灣區(qū)工作了 20 年,一直從事 GPU 的研發(fā)和產(chǎn)品工作,不過他并不在英偉達(dá)工作。在幫助 AMD 在中國建立研發(fā)中心之前,他有七年的時間在 AMD 為其 CPU/APU 部門研發(fā)產(chǎn)品。在此之前,他負(fù)責(zé)開發(fā)網(wǎng)絡(luò)安全設(shè)備,還曾在 S3 Inc. 從事 GPU 開發(fā)工作。另一位聯(lián)合創(chuàng)始人、同時也是燧原科技的首席運(yùn)營官張亞林曾是趙立東在 AMD 工作時的同事,他在AMD擔(dān)任過高級芯片經(jīng)理和全球器件研發(fā)技術(shù)經(jīng)理,同時也從事 AMD 早期 GPU 的工作。

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章