當今的處理器架構能否更高效?
2025-07-18 08:00:10 EETOP多年來,處理器的設計重心一直放在性能上,而這種性能幾乎無需對其他任何因素負責。性能如今依然重要,但它必須開始對功耗負責。
如果性能的小幅提升伴隨著功耗的不成比例增長,設計人員可能需要放棄這類改進,轉而選擇能效更高的方案。盡管當前架構在性能和功耗優化方面穩步推進,但進一步提升正變得越來越困難。
“所有人都在重新設計微架構,研究如何改進以控制功耗,” 鏗騰電子(Cadence)Tensilica 音頻 / 語音 DSP 產品營銷總監普拉卡什?馬德瓦帕西(Prakash Madhvapathy)表示。
許多旨在提高計算吞吐量的處理器特性(如亂序執行)會增加復雜電路,進而導致功耗和電路面積上升。如今,由于功耗成本問題,這類改進很可能不會被接受。那么,在當前的處理器架構中,還有哪些機會呢?
許多提升能效的努力都涉及對現有架構的優化設計,這方面仍有一些提升空間。“在實現層面,有很多節能技術,” Ansys(已被Synopsys收購)產品營銷總監馬克?斯溫嫩(Marc Swinnen)說。
一種非常基礎的方法是利用制程改進,用更少的功耗完成更多工作。“摩爾定律并未消亡,” 斯溫嫩表示,“我們仍在推出更先進的小尺寸制程技術,而這一直是降低功耗的首要方式。它或許很快會走到盡頭,但目前還沒到那一步。”
這也會影響制程節點的選擇。“選擇特定制程節點時,也需要考慮能效,” 馬德瓦帕西說,“22nm 本質上是 28nm 的改進版,能效特性要好得多。” 他指出,12nm 是另一個常用于高能效設計的熱門節點。
3D 集成電路(3D-ICs)提供了一種介于單芯片和 PCB 級組裝之間的新功耗平衡點。“3D-IC 的功耗會高于單芯片,但相比通過傳統 PCB 布線連接的多芯片方案,3D-IC 的功耗更低、速度更快,” 斯溫嫩指出。
共封裝光學(CPO)技術將光學元件與硅片更緊密地結合,這也能降低功耗,但它的普及之路漫長。“CPO 早已存在,但由于技術復雜性帶來的經濟成本難以合理化,最終的權衡往往并不劃算,” 斯溫嫩解釋道,“不過這種情況似乎正在改變。一方面是技術有所進步,另一方面是高速數字通信的需求變得極為迫切,人們愿意為此支付更高成本。”
有些實現技術聽起來很有趣,但也存在自身挑戰。異步設計就是其中之一。“從積極方面看,每個寄存器都能以最快速度與下一個寄存器通信,” 斯溫嫩解釋道,“沒有中央時鐘,整個時鐘架構都可以省去。也不存在‘ slack ’(即一條數據路徑等待另一條數據路徑的情況)。盡管異步設計已有數十年歷史,但(除特定場景外)始終未能普及,因為其性能不可預測。時序如何完全是個未知數,而且由于制程差異,每顆芯片的表現可能都略有不同。”
最終它是否真的能節省功耗也不明確。“自定時握手意味著觸發器必須設計得復雜得多,” 斯溫嫩說,“綜合來看,所有觸發器的功耗反而更高。而且有個問題始終存在:‘付出這么多復雜性和犧牲可預測性后,真的能節省多少功耗?’結果是,它并未成為一種主流設計方法。”
虛假功耗(或毛刺功耗)也可以通過數據門控和時鐘門控來抑制。“這會增加面積,但對降低虛假功耗的效果相當顯著,” 馬德瓦帕西說。
這需要通過分析來確定主要的功耗來源。“它不僅能測量毛刺功耗,還能找出產生毛刺的原因,” 斯溫嫩指出。
歸根結底,在實現層面能產生的影響是有限的。“RTL(寄存器傳輸級)層面的優化空間是有上限的,這很諷刺,因為大多數節能機會都集中在 RTL 層面,” 斯溫嫩說,“最大的收益其實來自架構層面。”
人工智能(AI)計算將設計團隊推向了 “內存墻” 的挑戰,因此,鑒于行業對 AI 訓練和推理的關注,大量精力都投入到了如何讓數萬億參數在需要時出現在需要的位置 —— 同時避免功耗過高。但處理器本身也會消耗能量,而且其他工作負載在執行功耗和數據移動功耗之間的平衡會有所不同。
盡管時鐘頻率仍在逐步攀升,但這種提升對性能的推動作用已遠不如從前。如今,性能改進的核心目標是盡可能讓處理器的更多部分保持忙碌狀態。有三個架構特性可以體現這種改進帶來的復雜變化:推測執行(又稱分支預測)、亂序執行和有限并行性。
推測執行的目的是避免這樣一種情況:當遇到分支指令時,必須等待分支結果才能決定后續執行路徑。等到此時再行動會延遲結果輸出,因為系統需要根據分支結果從 DRAM 中讀取相應指令。相反,推測執行會預先沿著一條分支(通常是最可能的那條)執行。通常,分支決策完成后會驗證該推測是否正確,但有時也會出錯。這時就必須撤銷推測計算的結果,重新執行另一條分支(包括可能從 DRAM 中讀取指令)。
分支預測通常與亂序執行配合使用,后者允許指令的執行順序與程序中的排列順序不同。其核心思想是:當一條指令因等待數據而停滯時,另一條后續指令可能已經準備就緒。需要注意的是,后者不能依賴于前者,但串行編程范式的一個主要限制是,即使指令之間沒有依賴關系,也必須按順序列出。因此,亂序執行是一個復雜的系統,它能提前啟動多條指令,同時確保遵循原始程序的語義。
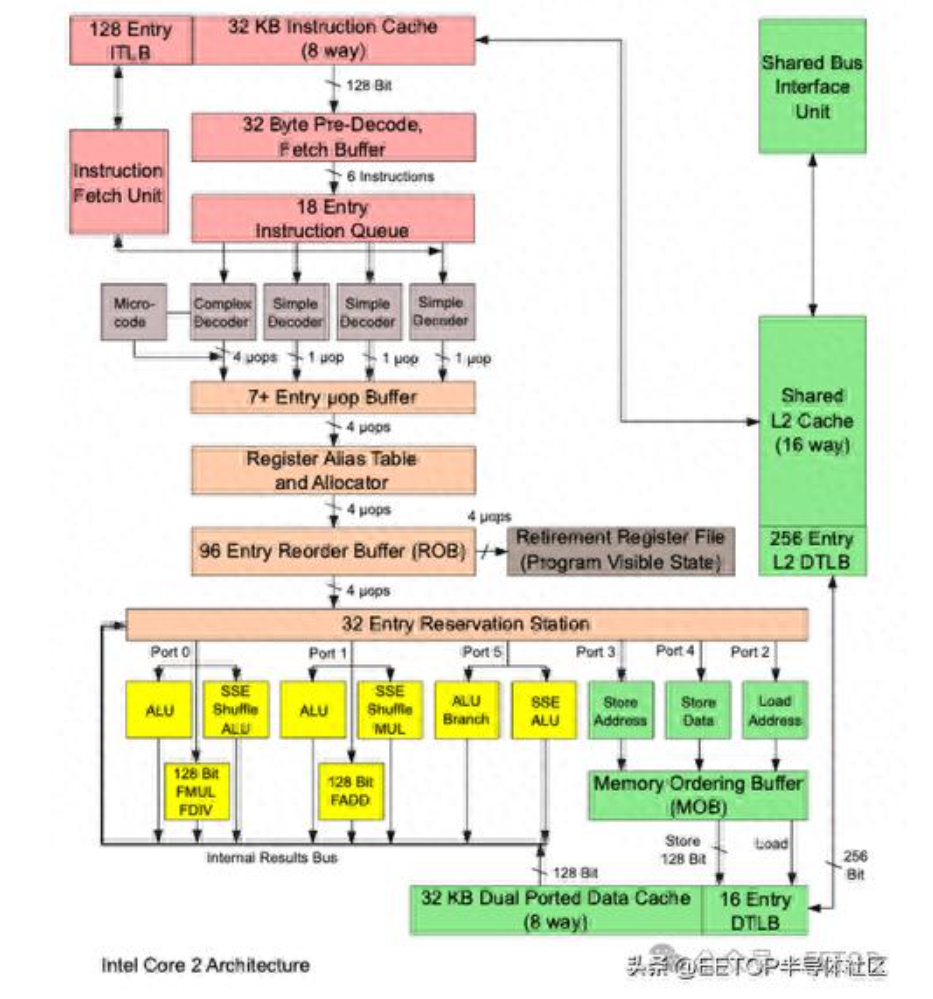
圖 1:英特爾處理器微架構示例。該單元包含亂序處理功能。由于需要向后兼容代碼,指令在執行前會先轉換為微碼。該模型有 11 個功能單元,其中 8 個用于執行,3 個用于數據加載 / 存儲。來源:I, Appaloosa, CC BY-SA 3.0。
這些都不是簡單的系統,其成本可能與其收益不成比例,具體取決于設計方式。“例如,分支預測器會記錄之前執行過的分支,” 西門子 EDA(Siemens EDA)高級合成部門項目總監拉斯?克萊因(Russ Klein)說,“和緩存類似,這個記錄列表通常會使用分支目標的低 N 位作為哈希鍵,來索引已執行的分支列表。N 可以是 4、16 或更大,列表中的條目數量可以是 1、2 或 32。你可以存儲完整的分支目標地址,也可以只存儲低 12 位或 16 位。對已執行分支的記錄越詳細、容量越大,性能就越好,但顯然會占用更多空間(和功耗)。”
由此帶來的收益也會相應變化。“一個小型簡單的分支預測器可能會使處理器速度提升 15%,而一個大型復雜的預測器可能提升 30%。但后者的面積可能是前者的 10 倍(甚至更多),” 克萊因解釋道,“從面積上看可能無關緊要,但對功耗來說,這就成了大問題。”
鏗騰電子通過重構部分編解碼器來提升性能,得到的代碼分支更少。“我們看到性能提升了約 5% 到 15%,” 馬德瓦帕西說,“編解碼器中的分支數量不到 5%,而且在我們使用 ZOL(零開銷循環)的內部執行循環中,幾乎沒有分支。”
更普遍地說,該公司發現普通程序中的分支更多。“實際代碼中約 20% 的指令是分支指令,” 馬德瓦帕西說,“每一個分支都是推測執行的機會。由于每周期執行的平均指令數顯著增加,性能提升可達 30% 或更高 —— 即使這些預測中只有一半是正確的。(分支預測和亂序執行的)綜合開銷可能在 20% 到 30% 之間。”
克萊因回憶起 Tilera 創始人阿南特?阿加瓦爾(Anant Agarwal)曾提到的 “淘汰法則”(Kill Rule)。“該法則指出,如果你要在 CPU 中加入一個特性,它會增加面積,而如果面積的增加量超過了性能的提升量,就不應該加入這個特性,” 他說。
并行性顯然是提升性能的另一種方式,但當前處理器中的并行能力有限。如今的主流處理器主要通過兩種方式提供并行性:集成多個核心,以及在單個核心內集成多個功能單元。
功能單元類似于過去的簡單算術邏輯單元(ALU),是實際執行指令的部件。一個功能單元通常能執行除簡單數學運算外的多種指令,可能包括乘法器、除法器、地址生成器,甚至分支處理單元。通過提供多個這樣的單元,當一個單元忙碌時,另一個可能空閑,可用于執行另一條指令(可能是亂序的)。
不同處理器的功能單元數量不同,代碼分析有助于確定這些單元中指令支持的組合和分布。這有助于在可能的情況下實現指令執行的并行化,但處理器的開銷(如指令讀取)仍是串行的。
真正的計算并行化是提升性能的最佳機會之一,而且如果處理器設計不那么復雜,可能會更節能。但這種解決方案并不新鮮。十多年前就有商用的眾核處理器,但未能獲得廣泛認可。
很少有算法能完全并行化。那些能完全并行化的通常被稱為“易并行”(embarrassingly parallel)算法。其他算法則是并行代碼和串行代碼段的混合體。阿姆達爾定律(Amdahl’s Law)指出,串行部分是性能提升的最終限制因素。有些程序可以高度并行化,有些則不能。但即使一個算法看似無法并行,也可能存在其他并行機會。
分形就是一個例子。“f (x) 依賴于 f (x-1),” 克萊因解釋道,“每個像素都通過一長串串行計算得到。但如果是處理圖像,比如 1024×1024 的圖像,就有很多并行機會(可以同時計算多個像素)。”
如今的數據中心服務器處理器最多可集成約 100 個核心。但與之前的眾核處理器不同,這些核心不是用于運行單個程序,而是允許為不同用戶的多個程序提供云計算服務。
即使算法可以并行化,關鍵問題在于處理器必須通過并行方式編程。這通常意味著要顯式管理代碼的并行性,例如使用 pThreads。這比普通編程復雜得多,需要了解數據依賴關系,以確保符合順序語義。盡管有一些工具可以提供幫助,但沒有一種工具進入主流軟件開發領域。
此外,手動管理并行性可能需要為不同處理器編寫不同的程序。如果所需線程數超過特定處理器的硬件支持能力,程序可能能運行,但無法達到最佳性能。轉向軟件并行性可能會因上下文切換開銷而降低性能。
最大的問題是,軟件開發人員對顯式并行編程不屑一顧。他們強烈希望任何新技術都能通過現有方法編程。“除了一個領域(我們看到它開始滲透)——GPU 和 TPU,軟件開發人員堅決反對 100 核處理器的概念,” 克萊因觀察到。
這就是眾核處理器在商業上失敗的原因。即便如此,并行化的主要目的還是提升性能。降低功耗需要采用適度的核心設計和積極的斷電策略,以避免空閑核心消耗能量。并行性還有助于恢復因核心能效優化而可能損失的整體性能。
“我的觀點是,大規模陣列的極簡 CPU 是可行的,但這需要改變編程方法,” 他說,“實現這一點的唯一希望是,AI 能夠創建一個并行化編譯器,而這是整個行業一直未能做到的。”
如今,處理在通用處理器上運行緩慢的算法的實用方法是使用加速器作為非阻塞卸載單元,這樣加速器可以高效處理其任務,而 CPU 則執行其他任務(或休眠)。
各類加速器已經存在了數十年。如今,鑒于 AI 訓練和推理所需的特定密集計算,大量注意力都集中在能加速這些任務的加速器上。但這類加速器并非新事物。
“異構計算結合了不同的處理核心,以提供優化的功耗和性能,”Expedera 營銷副總裁保羅?卡拉祖巴(Paul Karazuba)說,“這顯然包括神經網絡處理器(NPU)。NPU 接管了原本由能效較低的 CPU 和 GPU 處理的所有 AI 計算。然而,并非所有 NPU 都生而平等—— 無論是在設計方法、架構還是利用率方面。”
這是因為有些加速器可能高度專用(甚至定制化),而另一些則保持更通用的特性。“如果 AI 工作負載已知且穩定,定制 NPU 可以在功耗和成本效率上帶來顯著提升,” 卡拉祖巴繼續說,“如果需要靈活性以支持多種模型或未來的 AI 趨勢,通用 NPU 更具適應性,也更容易與現有軟件生態系統集成。”
定制加速器會使其更貼合特定工作負載,這種努力應該能提升能效。
“針對 NPU 而言,提高處理器子系統效率的一種方法是設計更面向應用的 NPU,而非采用更通用的方案,” 卡拉祖巴說,“定制 NPU 通常使用專門的 MAC(乘加)陣列和執行流水線,可能針對特定數據類型和模型結構進行優化。通用 NPU 則由可配置計算單元組成,支持多種數據類型,通常適用于更廣泛的層和算子。”
摒棄特定任務不需要的特性可以帶來顯著效果。“在實際應用中,Expedera 發現,部署定制 NPU 時,處理器效率(以 TOPS/W 衡量)通常能提升約 3 到 4 倍,利用率(定義為實際吞吐量與理論最大吞吐量之比)提升超過 2 倍。”
顯然,在提升處理器(及處理子系統)效率方面仍有一些機會。但在不遠的將來,我們可能會面臨“無計可施” 的風險。到那時會發生什么?
這正是新處理器架構可能發揮作用的地方。然而,鑒于當前架構背后存在龐大的生態系統,這種變革并非易事。幸運的是,已有一些新的架構理念,而且我們也有可能放棄部分通用性。
原文:
https://semiengineering.com/can-todays-processor-architectures-be-made-more-efficient
關鍵詞: 處理器