全面挑戰(zhàn)x86!Arm公布迄今性能最強服務器內核及首款Armv9平臺
2021-04-28 13:02:14 EETOP昨天是Arm處理器首次通電的36周年。今天,該公司公布了其Neoverse V1和N2平臺的深入細節(jié),該平臺將為其未來的數據中心處理器設計提供動力,其核心數高達192個,TDP為350W。
Arm表示這兩款新的、更專注的Noverse平臺具有令人印象深刻的性能和效率提升。Neoverse V1平臺是第一個支持可擴展矢量擴展(SVE)的Arm內核,為HPC和ML工作負載帶來高達50%的性能提升。而Neoverse N2平臺是第一個支持新公布的Arm v9擴展的IP,如SVE2和內存標簽,在不同的工作負載中提供高達40%的性能提升。
此外,Arm公司還分享了有關其Neoverse相干網狀網絡(NeoverseCoherent Mesh Network) (CMN-700)的更多詳細信息,該網絡將把最新的V1和N2設計與其他平臺設計(例如如DDR、HBM和各種加速器技術)的智能高帶寬低延遲接口結合起來。同時使用行業(yè)標準協議,如CCIX和CXL以及Arm IP。這種新的網狀設計可作為基于單片和多片設計的下一代Arm處理器的骨干。
如果Arm的性能預測得到證實,Neoverse V1和N2平臺可以為該公司在橫跨數據中心到邊緣的多種應用中提供更快的采用速度,從而給采用x86的英特爾和AMD帶來更大壓力。特別是考慮到單裸片(die)和多裸片設計都有全功能的連接選項。
接下來讓我們從Arm Neoverse路線圖和目標開始,然后深入了解新IP的技術細節(jié)。
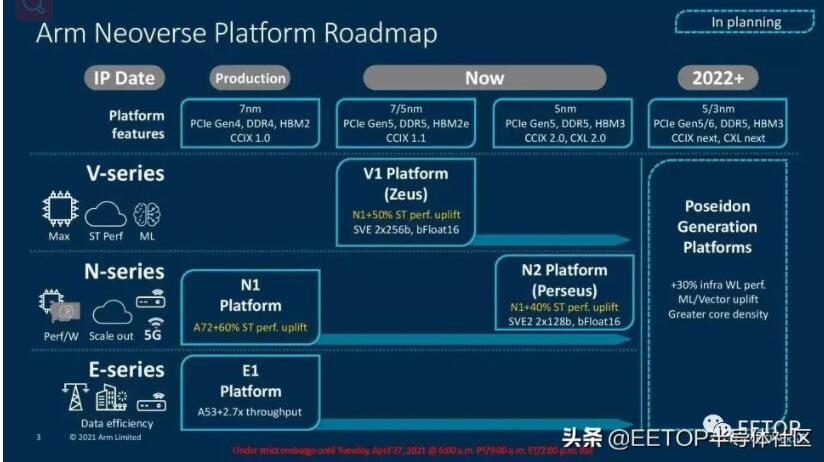
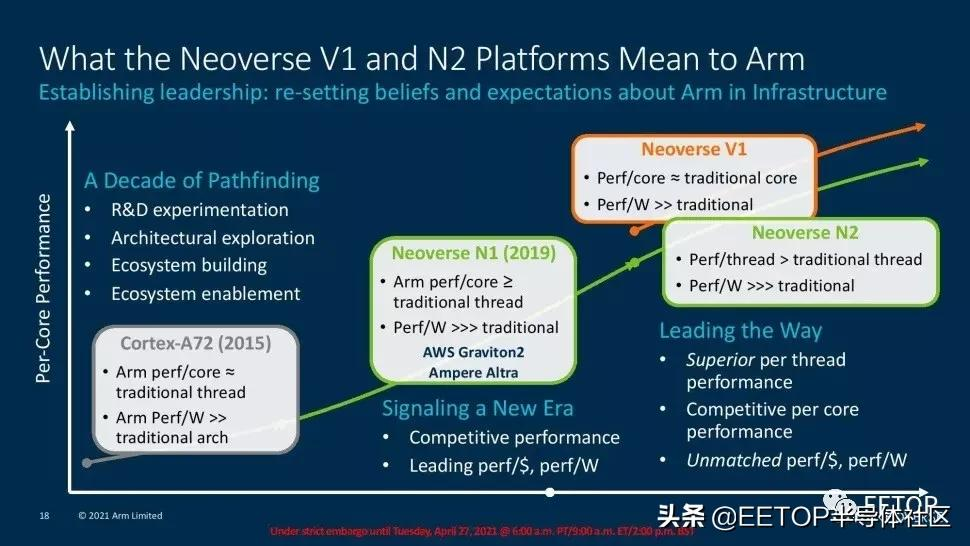
Arm的路線圖與它去年分享的版本相比沒有變化,但確實有助于規(guī)劃未來幾年我們將看到的穩(wěn)定的改進步伐。
2015年,Arm的服務器雄心隨著A-72的出現而起飛,它的性能和每瓦性能相當于標準競爭服務器架構下的傳統線程。
Arm表示,當前一代的Neoverse N1內核相當于或超過了“傳統”(即x86) SMT線程。該內核為AWS Graviton 2芯片和安培的Altra提供動力。此外,Arm還表示,考慮到N1的能效,一個N1內核可以取代三個x86線程,但耗電量相同,整體性價比提高了40%。Arm將該設計的大部分成功歸功于相干網狀網絡600 (CMN-600),該技術可以隨著核心數量的增加而線性地擴展性能。
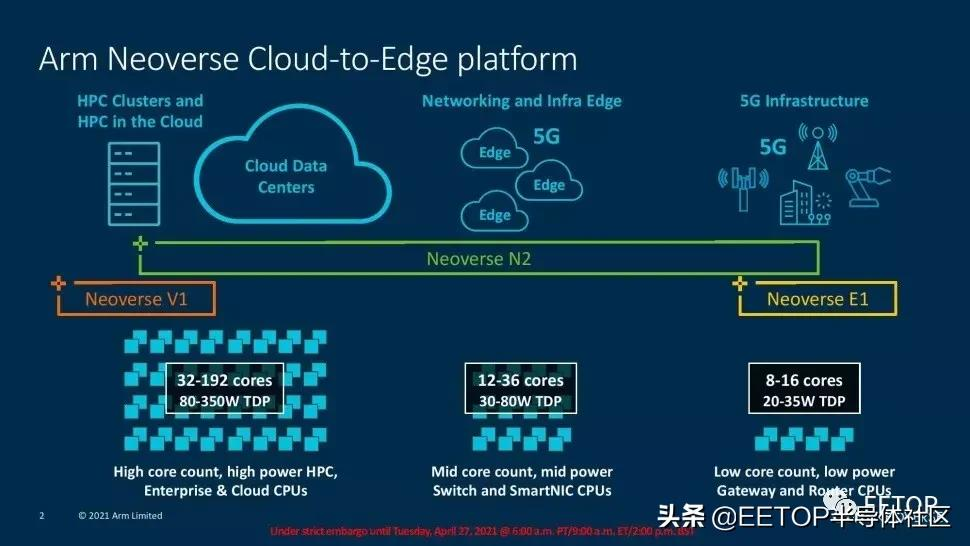
Arm已經為我們今天將要討論的Neoverse V1和N2平臺修改了其核心架構和網格。現在它們支持192核和350W TDPs。Arm公司表示,N2核心將在與其他芯片相比的SMT線程中取得無可匹敵的領先地位,并提供更高的性能/瓦特。
此外,該公司表示,Neoverse V1內核將提供與競爭內核相同的性能,這標志著該公司首次實現了在配備SMT的內核上運行的兩個線程的均等性。這兩款芯片都采用了Arm新的CMN-700網狀結構,可以實現單裸片或多片解決方案,為客戶提供了大量選擇,特別是在與加速器一起部署時。正如人們所期望的,Arm的Neoverse N2和V1針對超大規(guī)模和云計算、HPC、5G和基礎設施邊緣市場。客戶包括騰訊、使用Ampere的oracle Cloud、阿里巴巴、使用Graviton 2的AWS(在77個AWS地區(qū)中的70個地區(qū)可用)。Arm還計劃用Neoverse V1芯片部署兩個百億億級超級計算機。SiPearl "Rhea "和ETRI的K-AB21。
總的來說,ARM聲稱其Neoverse N2和V1平臺將提供同類最佳的計算、每瓦性能和可擴展性,這將超過競爭對手x86服務器設計。
Arm現有的Neoverse N1平臺可以從云端擴展到邊緣,涵蓋了從高端服務器到低功耗邊緣設備。下一代Neoverse N2平臺在一系列的使用中保留了這種可擴展性。相比之下,Arm專門設計了Neoverse V1"Zeus "平臺,以引入一個新的性能層,因為它希望更全面地滲透到HPC和機器學習(ML)應用中。
V1平臺具有更廣泛,更深入的體系結構,支持可擴展向量擴展(SVE),一種SIMD指令。。V1的SVE實現跨兩個通道以256b向量寬度(2x256b)運行,并且該芯片還支持bFloat16數據類型以提供增強的SIMD并行性。
在相同的(ISO)工藝下,Arm聲稱IPC比上一代N1提高了1.5倍,電源效率提高了70%到100%(因工作負載而異)。在L1和L2高速緩存大小相同的情況下,V1內核比N1內核大70%。
更大的內核是有道理的,因為V系列針對功耗和面積兩個方面的成本進行了優(yōu)化,以實現最佳性能,而N2平臺則采用了針對每瓦功率和單位面積性能進行了優(yōu)化的設計。
每核性能是V1的主要目標,因為它有助于最大限度地減少GPU和加速器的性能損失,這些加速器往往最終要等待線程綁定的工作負載,更不用說最大限度地減少軟件許可成本。
Arm還對設計進行了調整,以提供卓越的內存帶寬,從而影響了性能可擴展性,而下一代接口(如PCIe 5.0和CXL)則提供了I / O靈活性(在網狀部分中有更多介紹)。
最后,Arm將技術主權列為重點。這意味著Arm客戶可以擁有自己的供應鏈。
Neoverse V1代表了Arm迄今為止性能最高的內核,其中大部分來自于 "更寬 "的設計理念。前端有一個8寬的取指器,5-8寬的decode/rename單元,和一個15寬的流水線。
如圖所示,該芯片支持HBM、DDR5和自定義加速器。它也可以擴展到多裸片和多插槽設計。靈活的I / O選項包括PCIe 5接口以及CCIX和CXL互連。我們將在本文的稍后部分介紹Arm的網狀互連設計。
此外,Arm聲稱,相對于N1平臺,SVE可使浮點性能提高2倍,向量化工作負載提高1.8倍,機器學習提高4倍。
V1最大的變化之一是可以使用7nm或5nm工藝,而前代N1平臺僅限于7nm。Arm還對前端、內核和后端進行了許多微體系結構改進,以提供相對于上一代Arm芯片的大幅提速,增加了對SVE的支持并進行了調整以增強可擴展性。
這是該體系結構的最大更改的功能列表:
前端:
中核:
后端:
該圖顯示了總體流水線深度(從左到右)和帶寬(從上到下),突出了設計的令人印象深刻的并行性。

Arm還建立了新的電源管理和低延遲工具,以超越動態(tài)電壓頻率縮放(DVFS)的典型功能。這些工具包括最大功率緩解機制(MPMM),它提供了一個可調整的電源管理系統,允許客戶在盡可能高的頻率下運行高核心數的處理器,以及調度節(jié)流(DT),它在某些具有高IPC的工作負載中降低功率,例如矢量化工作(就像我們看到的那樣,英特爾在AVX工作負載期間降低了頻率)。
歸根結底,這一切都與功率、性能和面積(PPA)有關,而Arm在這里分享了一些預測。通過相同的(ISO)流程,Arm宣稱IPC比上一代N1提升了1.5倍,電源效率提高了70%至100%(隨工作負載而變化)。如果L1和L2緩存大小相同,則V1內核比N1內核大70%。
Neoverse V1支持Armv8.4,但該芯片還借鑒了將來的v8.5和v8.6修訂版中的某些功能,如上所示。
Arm還添加了一些功能來管理系統可擴展性,尤其是與共享資源分區(qū)和減少爭用有關的功能,如您在上面的PPT中所見。

Arm的可伸縮向量擴展(SVE)是新體系結構的一大亮點。首先,Arm使用SVE將計算帶寬增加了一倍,達到2x256b,并以4x128b向后支持Neon。
但是,這里的關鍵是SVE與向量長度無關。大多數向量ISA在向量單位中都有固定數量的位,但是SVE允許硬件以位為單位設置向量長度。然而,在軟件中,向量沒有長度。這簡化了編程,增強了支持不同位寬的架構之間二進制代碼的可移植性--指令將根據需要自動擴展,以充分利用可用的向量帶寬(例如,128b或256b)。
Arm分享了關于SVE指令的幾個細粒度指令的信息,但這些細節(jié)大多超出了本文的范圍。Arm還分享了一些帶有SVE的模擬V1和N2基準,但請記住,這些是供應商提供的,而且只是性能模擬。
ARM Neoverse N2平臺“ Perseus”
在這里,我們可以看到N2 Perseus平臺的PPT,其主要目標是側重于橫向擴展實施。因此,該公司針對每功率性能(watt)和單位面積性能以及更健康的內核和可擴展性優(yōu)化了設計。與上一代N1平臺一樣,該設計可以從云擴展到邊緣。
Neoverse N2比V1芯片有一個更新的內核,但該公司還沒有分享很多細節(jié)。然而,我們知道N2是第一個支持Armv9和SVE2的Arm平臺,也就是我們上面提到的第二代SVE指令。
Arm公司聲稱,與N1相比,單線程性能提高了40%,但在相同的功率和面積效率范圍內。關于N2的大多數細節(jié)都反映了我們上面在V1中涉及的細節(jié)。
Arm的SPEC CPU 2017單核測試顯示了從N1到N2的穩(wěn)步發(fā)展,然后使用V1平臺實現了更高的性能提升。該公司還提供了與Intel Xeon 8268和未指定的40核Ice Lake Xeon系統以及EPYC Rome 7742和EPYC Milan 7763進行的一系列比較。
相干網狀網絡(CMN-700)
Arm允許其合作伙伴調整核心數量,緩存大小,并使用不同類型的內存,例如DDR5和HBM,并選擇各種接口,例如PCIe 5.0,CXL和CCIX,這需要非常靈活的基礎設計方法。
再加上Neoverse可以從云和邊緣跨越到5G,并且互連還必須能夠跨越各種功率點的完整范圍并滿足計算要求。這就是相干網狀網絡700(CMN-700)發(fā)揮作用的地方。
Arm通過合規(guī)性和標準,Arm開源軟件以及ARM IP和體系結構專注于安全性,所有這些都在SystemReady框架下展開,該框架是Neoverse平臺體系結構的基礎。
Arm為客戶提供基于其自身內部工作的參考設計,這些設計在仿真基準和工作負載分析中得到了預審。Arm還為軟件開發(fā)提供了一個虛擬模型。
然后,客戶可以采用參考設計,在內核類型(如V系列、N系列或E系列)之間進行選擇,并改變內核數量、內核頻率目標、緩存層次、內存(DDR5、HBM、閃存、存儲類內存等)和I/O容納量以及其他因素。客戶還可以圍繞系統級緩存撥出參數,該緩存可在加速器之間共享。
還有對多芯片集成的支持。這懸掛在相干網狀網絡上,通過PCIe、CXL、CCIX等接口為I/O連接選項和多芯片通信提供流水線。
V系列CPU通過為加速器提供足夠的帶寬來應對異構工作負載的增長,支持分解設計,以及多芯片架構,幫助延緩摩爾定律的發(fā)展。
這些類型的設計有助于解決每個SoC的功率預算(以及因此而產生的熱量)不斷增加的問題,同時也允許擴展到單個SoC的網狀限制之外。
此外,I/O接口不能很好地擴展到更小的節(jié)點,所以許多芯片制造商(如AMD)正在將PHY保留在舊節(jié)點上。這需要強大的芯片到芯片的連接選項。

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導體創(chuàng)芯網 快訊
相關文章