一片晶圓僅做一顆芯片!史上最大芯片誕生!1.2萬(wàn)億個(gè)晶體管
2019-08-20 13:09:03 編譯:易建芯 原文出處:venturebeat這顆巨型芯片,面積42225 平方毫米,擁有1.2 萬(wàn)億個(gè)晶體管,400000 個(gè)核心,片上內(nèi)存18G字節(jié),內(nèi)存帶寬19PByte/s,fabric帶寬100Pbit/s。是目前芯片面積最大的英偉達(dá)GPU的56.7倍!
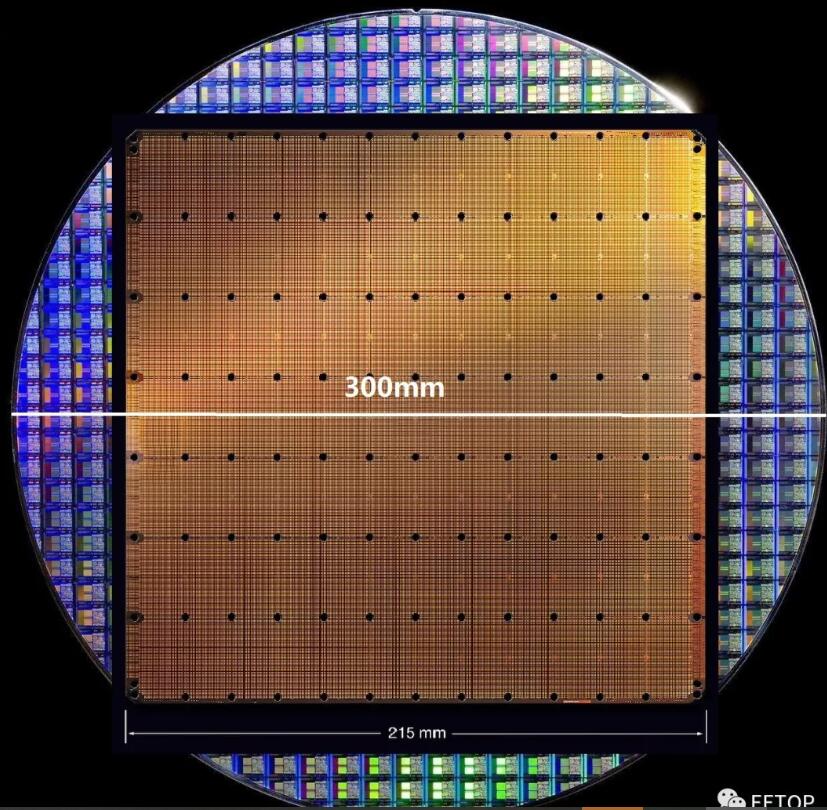
一塊12英寸晶圓僅做一顆芯片

這就是有史以來(lái)最大的芯片——Cerebras Wafer Scale Engine!是由人工智能初創(chuàng)公司Cerebras Systems公司推出,擁有1.2萬(wàn)億個(gè)晶體管。1971年英特爾首款4004處理器擁有2,300個(gè)晶體管,最近的Advanced Micro Devices處理器擁有320億個(gè)晶體管。
如何制造?
大多數(shù)芯片實(shí)際上是在12英寸硅晶元片上創(chuàng)建的芯片集合,每塊硅晶圓片可以集成成百上千顆芯片。但Cerebras Systems芯片是在單個(gè)晶圓上互連的單芯片。這些互連設(shè)計(jì)使其全部保持高速運(yùn)行,因此萬(wàn)億個(gè)晶體管全部一起工作。
通過(guò)這種方式,Cerebras Wafer Scale Engine是有史以來(lái)最大的處理器,它專門設(shè)計(jì)用于處理人工智能應(yīng)用。該公司本周正在加利福尼亞州帕洛阿爾托的斯坦福大學(xué)舉行的Hot Chips會(huì)議上討論這項(xiàng)設(shè)計(jì)。
三星實(shí)際上已經(jīng)制造了一個(gè)閃存芯片,即eUFS,擁有2萬(wàn)億個(gè)晶體管。但Cerebras芯片專為加工而設(shè)計(jì),擁有400,000個(gè)核心,42,225平方毫米。它比最大的Nvidia圖形處理單元大 56.7倍,該單元的尺寸為815平方毫米和211億個(gè)晶體管。
WSE還包含3,000倍的高速片上存儲(chǔ)器,并且具有10,000倍的存儲(chǔ)器帶寬。
該芯片來(lái)自Andrew Feldman領(lǐng)導(dǎo)的團(tuán)隊(duì),后者曾創(chuàng)建微型服務(wù)器公司SeaMicro,并以3.34億美元的價(jià)格出售給Advanced Micro Devices。Cerebras Systems的聯(lián)合創(chuàng)始人兼首席硬件架構(gòu)師Sean Lie將概述熱芯片上的Cerebras Wafer Scale Engine。加利福尼亞州Los Altos公司擁有194名員工。

芯片尺寸在AI中非常重要,因?yàn)榇?a href="http://www.xebio.com.cn/semi" target="_blank" class="keylink">芯片可以更快地處理信息,在更短的時(shí)間內(nèi)產(chǎn)生答案。減少洞察時(shí)間或“培訓(xùn)時(shí)間”,使研究人員能夠測(cè)試更多想法,使用更多數(shù)據(jù)并解決新問(wèn)題。谷歌,F(xiàn)acebook,OpenAI,騰訊,百度和許多其他人認(rèn)為,今天人工智能的基本限制是培訓(xùn)模型需要很長(zhǎng)時(shí)間。因此,縮短培訓(xùn)時(shí)間消除了整個(gè)行業(yè)進(jìn)步的主要瓶頸。
當(dāng)然,芯片制造商通常不會(huì)制造這么大的芯片。在單個(gè)晶片的制造過(guò)程中通常會(huì)出現(xiàn)一些雜質(zhì)。如果一種雜質(zhì)會(huì)導(dǎo)致一塊芯片發(fā)生故障,實(shí)際制造出的芯片產(chǎn)量有一定良率,不可能100%都能用。但Cerebras設(shè)計(jì)的芯片留有冗余,一種雜質(zhì)不會(huì)導(dǎo)致整個(gè)芯片都不能用。
性能優(yōu)勢(shì)及用途
一個(gè)芯片提供超級(jí)計(jì)算機(jī)級(jí)的計(jì)算能力
“Cerebras WSE”專為人工智能設(shè)計(jì)而設(shè)計(jì),其中包含了不少基礎(chǔ)創(chuàng)新,解決了限制芯片尺寸的長(zhǎng)達(dá)數(shù)十年的技術(shù)挑戰(zhàn) - 如芯片良率,功率傳送、封裝等,推動(dòng)了最先進(jìn)技術(shù)的發(fā)展。和包裝,每個(gè)架構(gòu)決策都是為了優(yōu)化AI工作的性能。結(jié)果是,Cerebras WSE根據(jù)工作量提供了數(shù)百或數(shù)千倍的現(xiàn)有解決方案的性能,只需很小的功耗和空間。”Cerebras Systems首席執(zhí)行官的Fieldman說(shuō)。
通過(guò)加速神經(jīng)網(wǎng)絡(luò)訓(xùn)練的所有元素來(lái)實(shí)現(xiàn)這些性能提升。神經(jīng)網(wǎng)絡(luò)是一種多級(jí)計(jì)算反饋回路。輸入在循環(huán)中移動(dòng)速度越快,循環(huán)學(xué)習(xí)的速度越快,即訓(xùn)練時(shí)間越短。可以通過(guò)加速循環(huán)內(nèi)的計(jì)算和通信來(lái)加速輸入的循環(huán)速度。
Linley Group首席分析師Linley Gwennap在一份聲明中說(shuō):“Cerebras憑借其晶圓級(jí)技術(shù)實(shí)現(xiàn)了巨大的飛躍,在單片硅片上實(shí)現(xiàn)了比任何人想象的更多的處理性能。為了實(shí)現(xiàn)這一壯舉,該公司已經(jīng)解決了一系列惡性工程挑戰(zhàn),這些挑戰(zhàn)幾十年來(lái)阻礙了該行業(yè),包括實(shí)施高速芯片到芯片通信,解決制造缺陷,封裝如此大的芯片,以及提供高成本 - 密度電源和冷卻。通過(guò)將各種學(xué)科的頂級(jí)工程師聚集在一起,Cerebras在短短幾年內(nèi)創(chuàng)造了新技術(shù)并交付了一個(gè)產(chǎn)品,這是一項(xiàng)令人印象深刻的成就。”
Cerebras WSE芯片面積比目前最大的GPU大56.7倍, 并提供更多核心進(jìn)行計(jì)算,有更多核心靠近內(nèi)存,因此內(nèi)核可以高效運(yùn)行。由于這些大量的內(nèi)核和內(nèi)存位于單個(gè)芯片上,因此所有通信都在芯片上進(jìn)行,通信帶寬高、延遲低,因此核心組可以以最高效率進(jìn)行協(xié)作。
Cerebras WSE中的46,225平方毫米的芯片面積上包含40萬(wàn)個(gè)AI優(yōu)化核心,無(wú)緩存、無(wú)開銷的計(jì)算內(nèi)核,以及18G字節(jié)的本地化分布式超高速SRAM內(nèi)存。內(nèi)存帶寬為每秒9PB(9000TB)。這些核心通過(guò)細(xì)粒度、全硬件、片上網(wǎng)絡(luò)連接在一起,可提供每秒100Pb(100*1000Tb)的總帶寬。更多核心、更多本地內(nèi)存和低延遲高帶寬結(jié)構(gòu),共同構(gòu)成了面向AI加速任務(wù)的最佳架構(gòu)。
“雖然AI在一般意義上被使用,但沒(méi)有兩個(gè)數(shù)據(jù)集或兩個(gè)AI任務(wù)是相同的。新的AI工作負(fù)載不斷涌現(xiàn),數(shù)據(jù)集也在不斷變大,”Tirias Research首席分析師兼創(chuàng)始人Jim McGregor在一份聲明中表示。
“隨著AI的發(fā)展,芯片和平臺(tái)解決方案也在不斷發(fā)展。Cerebras WSE是半導(dǎo)體和平臺(tái)設(shè)計(jì)方面的一項(xiàng)驚人的工程成就,它在單個(gè)晶圓級(jí)的解決方案中提供了超級(jí)計(jì)算機(jī)級(jí)的計(jì)算能力、高性能內(nèi)存和帶寬。”
Cerebras 表示,如果沒(méi)有多年來(lái)與臺(tái)積電(TSMC)的密切合作,他們不可能取得這個(gè)創(chuàng)紀(jì)錄的成就。臺(tái)積電是全球最大的半導(dǎo)體代工廠,在先進(jìn)工藝技術(shù)方面處于領(lǐng)先地位。WSE芯片由臺(tái)積電采用先進(jìn)的16nm制程技術(shù)制造。
WSE包含400,000個(gè)AI優(yōu)化的計(jì)算核心。被稱為稀疏線性代數(shù)核心的SLAC,計(jì)算核心靈活,可編程,并針對(duì)支持所有神經(jīng)網(wǎng)絡(luò)計(jì)算的稀疏線性代數(shù)進(jìn)行了優(yōu)化。SLAC的可編程性確保內(nèi)核可以在不斷變化的機(jī)器學(xué)習(xí)領(lǐng)域中運(yùn)行所有神經(jīng)網(wǎng)絡(luò)算法。
由于稀疏線性代數(shù)核心針對(duì)神經(jīng)網(wǎng)絡(luò)計(jì)算基元進(jìn)行了優(yōu)化,因此它們可實(shí)現(xiàn)業(yè)界最佳利用率 - 通常是圖形處理單元的三倍或四倍。此外,WSE核心包括Cerebras發(fā)明的稀疏性收集技術(shù),以加速稀疏工作負(fù)載(包含零的工作負(fù)載)的計(jì)算性能,如深度學(xué)習(xí)。
WSE包含40萬(wàn)個(gè)AI優(yōu)化的計(jì)算內(nèi)核(compute cores)。這種計(jì)算內(nèi)核被稱為稀疏線性代數(shù)核(Sparse Linear Algebra Cores, SLAC),具有靈活性、可編程性,并針對(duì)支持所有神經(jīng)網(wǎng)絡(luò)計(jì)算的稀疏線性代數(shù)進(jìn)行了優(yōu)化。SLAC的可編程性保證了內(nèi)核能夠在不斷變化的機(jī)器學(xué)習(xí)領(lǐng)域運(yùn)行所有的神經(jīng)網(wǎng)絡(luò)算法。
由于稀疏線性代數(shù)內(nèi)核是為神經(jīng)網(wǎng)絡(luò)計(jì)算進(jìn)行優(yōu)化的,因此它們可實(shí)現(xiàn)業(yè)界最佳利用率——通常是GPU的3倍或4倍。此外,WSE核心還包括Cerebras發(fā)明的稀疏捕獲技術(shù),以加速在稀疏工作負(fù)載(包含0的工作負(fù)載)上的計(jì)算性能,比如深度學(xué)習(xí)。
零在深度學(xué)習(xí)計(jì)算中很普遍。通常,要相乘的向量和矩陣中的大多數(shù)元素都是0。然而,乘以0是浪費(fèi)硅,功率和時(shí)間的行為,因?yàn)闆](méi)有新的信息。
因?yàn)?a href="http://www.xebio.com.cn/cpu_soc" target="_blank" class="keylink">GPU和TPU是密集的執(zhí)行引擎——引擎的設(shè)計(jì)永遠(yuǎn)不會(huì)遇到0——所以它們即使在0時(shí)也會(huì)乘以每一個(gè)元素。當(dāng)50-98%的數(shù)據(jù)為零時(shí),如深度學(xué)習(xí)中經(jīng)常出現(xiàn)的情況一樣,大多數(shù)乘法都被浪費(fèi)了。由于Cerebras的稀疏線性代數(shù)核心永遠(yuǎn)不會(huì)乘以零,所有的零數(shù)據(jù)都被過(guò)濾掉,可以在硬件中跳過(guò),從而可以在其位置上完成有用的工作。
內(nèi)存是每一種計(jì)算機(jī)體系結(jié)構(gòu)的關(guān)鍵組成部分。靠近計(jì)算的內(nèi)存意味著更快的計(jì)算、更低的延遲和更好的數(shù)據(jù)移動(dòng)效率。高性能的深度學(xué)習(xí)需要大量的計(jì)算和頻繁的數(shù)據(jù)訪問(wèn)。這就要求計(jì)算核心和內(nèi)存之間要非常接近,而在GPU中卻不是這樣,GPU中絕大多數(shù)內(nèi)存都很慢,而且離計(jì)算核心很遠(yuǎn)。
Cerebras Wafer Scale Engine包含了比迄今為止任何芯片都要多的內(nèi)核和本地內(nèi)存,并且在一個(gè)時(shí)鐘周期內(nèi)擁有18GB的片上內(nèi)存。WSE上的核心本地內(nèi)存的集合提供了每秒9PB的內(nèi)存帶寬——比最好的GPU大3000倍的片上內(nèi)存和10000倍的內(nèi)存帶寬。
Swarm通信結(jié)構(gòu)是WSE上使用的處理器間通信結(jié)構(gòu),它以傳統(tǒng)通信技術(shù)功耗的一小部分實(shí)現(xiàn)了帶寬的突破和低延遲。Swarm提供了一個(gè)低延遲、高帶寬的2D網(wǎng)格,它將WSE上的所有400,000個(gè)核連接起來(lái),每秒的帶寬總計(jì)達(dá)100 petabits。

路由、可靠的消息傳遞和同步都在硬件中處理。消息會(huì)自動(dòng)激活每個(gè)到達(dá)消息的應(yīng)用程序處理程序。Swarm為每個(gè)神經(jīng)網(wǎng)絡(luò)提供了一個(gè)獨(dú)特的、優(yōu)化的通信路徑。軟件根據(jù)正在運(yùn)行的特定用戶定義的神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu),配置通過(guò)400,000個(gè)核心的最優(yōu)通信路徑,以連接處理器。
典型的消息通過(guò)一個(gè)具有納秒延遲的硬件鏈接。一個(gè)大腦WSE的總帶寬是每秒100 pb。不需要TCP/IP和MPI等通信軟件,因此可以避免性能損失。這種結(jié)構(gòu)的通信能量成本遠(yuǎn)低于1皮焦耳每比特,這比圖形處理單元低了近兩個(gè)數(shù)量級(jí)。結(jié)合了巨大的帶寬和極低的延遲,群通信結(jié)構(gòu)使大腦WSE比任何當(dāng)前可用的解決方案學(xué)習(xí)得更快。

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章


















