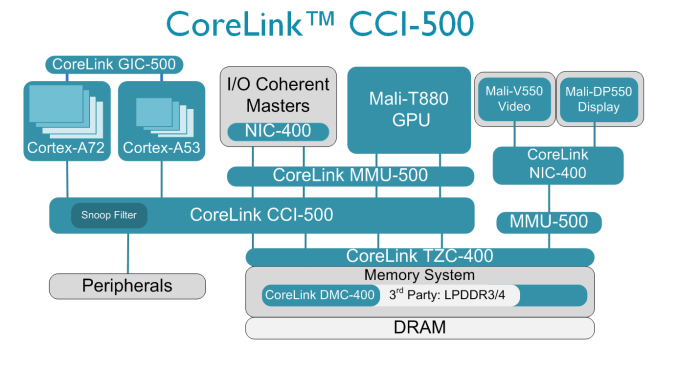
構建超大規模異構計算平臺,需攻克5大核心技術
2023-06-12 14:28:06 奇異摩爾2023年6月2日,以“聚焦應用,集智創芯”為主題的集微通用芯片行業應用峰會在廈門舉行。會上,奇異摩爾聯合創始人兼產品及解決方案副總裁祝俊東發表了《大模型驅動的全新算力形態,基于Chiplet的超大規模異構計算平臺》的主題演講,本篇文章回顧擷取自以上活動。

奇異摩爾聯合創始人兼產品及解決方案副總裁祝俊東
大模型的爆發,帶來了巨量的算力需求,也給芯片帶來了極大的挑戰。因能有效提升算力和互聯密度,異構計算和Chiplet兩大技術成為備受關注的方向。那么,要如何利用Chiplet構建一個超大規模的異構計算平臺?
PART 1大模型驅動高性能計算進化加速

挑戰1:硬件和系統規模持續提升
隨著算力需求的不斷提升,摩爾定律逐漸無法滿足芯片面積和芯片級聯提升的需求,進而引發了硬件和系統的規模過載。業界迫切需要構建更大規模的整合計算系統,以應對持續增長的算力需求。
挑戰2:算力應用場景多元化
隨著芯片工藝技術的不斷演進,算力場景應用也在不斷增長,倘若針對不同應用場景升級迭代芯片,企業將面臨巨大的資金挑戰。同時,為了滿足高性能計算對的效率需求,通用處理器(CPU)地位逐漸被GPU取代。異構計算和Chiplet技術,可以把CPU和GPU拼搭成一整個芯片,從而更好的實現通用性與性能的平衡。
挑戰3:互聯效率瓶頸
隨著計算機系統的規模擴大,存儲、計算規模也越發龐大,互聯效率成為芯片設計的重大的瓶頸。行業急需基于分布式、以存儲為中心的計算架構,以突破現有芯片互聯效率。
芯片巨頭比拼超大規模異構計算平臺
如今,全球主要芯片巨頭如AMD、Intel、Nvidia都在構建超大規模異構計算平臺。以Nvidia為例,其最新一代Hopper H100針對大型模型提供9倍AI訓練速度。

DGX H100 (Image credit: Nvidia)
祝俊東指出,Nvidia能實現如此高幅度的性能提升,關鍵在于系統級的互聯。從BlueField-3到Spectrum-4,Nvidia把構建了一個從底層到頂層的全鏈路互聯網絡架構體系,使互聯性能提升了數十倍。在此基礎上,Nvidia把GPGPU、異構計算、超高速互聯網絡組合在一起,創建了一個ETOPS級的超大規模計算集群:DGX GH200。

DGX GH200 (Image credit: Nvidia)
AMD、英特爾等頭部企業也在進行超大規模異構計算平臺的研發。2022年,英特爾發布了3D GPGPU Intel Ponte Vecchio,通過Intel的Xlink網絡把47個不同的芯粒組合在一起,構建了一個高性能的集群。

Intel Ponte Vecchio (Image credit: Intel)
AMD作為Chiplet路線的開拓者,一直將異構、Chiplet、互聯網絡作為其主要研發路線。AMD將6顆GPU和3顆CPU拼在一顆芯片上形成了其3D APU MI300,并將Infinity Fabric互聯架構升級至第三代,以實現全方位的多處理器性能和可擴展性的優化。

AMD MI300 (Image credit: Intel)
自動駕駛領域,芯片巨頭也紛紛布局大算力計算平臺。Nvidia在年初發布了Nvidia Thor超級芯片計劃,作為一顆多域合一的芯片,它集合了多種功能,擁有最高達2000T算力。

Nvidia Drive Thor (Image credit: Nvidia )
最近,在Nvidia與MediaTek的車用芯片共同開發計劃中,MediaTek將通過Chiplet設計方式將Nvidia的GPU集成在下一代Snapdragon產品中,通過雙SoC與雙NPU的組合打造更強的大算力芯片,并通過不同產品組適配高中低端應用和不同場景。

(Image credit: MediaTek)
PART 2構建大規模異構計算平臺需要五大關鍵技術
要構建超大規模異構計算平臺,需要五大軟硬件關鍵技術。
第一:適用于超大規模異構的計算架構,以實現軟、硬件的結合,以及單個計算單元性能的最大化;
第二:統一的編程模型以及協議的庫堆棧,以提高軟件的應用性;
第三:從CPU到GPU、NPU等不同類型的計算單元的芯粒支持;
第四:超大規模的傳輸網絡及互聯網絡,把不同的計算單元、存儲、連接等單元高效地連接在一起;
第五:先進封裝技術,讓不同的芯粒用接近甚至超過SoC的互聯密度連接,像一顆芯片一樣工作。
其中,后三大技術都與Chiplet緊密相關。這也是Chiplet成其為構建大規模異構計算平臺的關鍵因素的根本原因。
系統級視角看Chiplet:
從系統級的視角來看,Chiplet是一種新的系統級架構與dielet組合的方式。基于SoC 架構進行拆分重組,將主要功能單元 (IP) 轉變成獨立芯粒 (Dielet),并通過先進封裝和 Die-to-Die接口,將其連接到 Chiplet 互聯網絡 (OCI) 中,組成系統級宏芯片 (MSoC)。這也是全鏈路的chiplet的重組以及拆分的過程。
Chiplet的核心挑戰:高效互聯在芯片拆分后,需要高效的互聯。而Chiplet互聯涉及多個層次:Physical:先進封裝是Chiplet的物理支撐,包含substrate、2.5D、3D等不同形式,客戶需根據產品選擇適合的先進封裝形式;Electrical:為高效連接信號,需要Die-to-Die interface和高帶寬、低延時、低功耗及統一的協議;Interconnection:在die-to-die互聯基礎上,大量節點需要通過一套統一的連接網絡以及對應的算法進行連接;Network:把不同的芯粒通過更復雜的網絡結構高速互聯起來,實現不同節點間的全連通。
互聯對于Chiplet至關重要,也是Chiplet所面臨的核心挑戰所在。奇異摩爾作為國內第一批專注于2.5D和3D Chiplet研發的企業,就此提出了一整套完整的解決方案,以解決超大規模互聯問題。
PART 3:奇異摩爾:推出基于Chiplet的大規模異構計算平臺
奇異摩爾是一家基于Chiplet架構,為客戶提供核心通用互聯芯粒及系統級解決方案的服務商,以數據存儲和傳輸為核心,通過自研的Kiwi Fabric互聯體系高效連接不同類型的功能單元,目標是成為超大規模分布式異構計算平臺的基石。
奇異摩爾互聯核心:Die2Die接口和互聯芯粒
奇異摩爾的產品線分為兩大部分,其一是2.5D、3D芯粒系列,其二是Die-to-Die IP系列。奇異摩爾基于UCIe標準,提供覆蓋各種不同類型、綜合能力強、具高帶寬、低延時、低功耗的Die2Die IP,支持2.x/2.5/3D 等多種封裝形態。
2.5D IO Die:IO Die作為奇異摩爾的核心自研產品,是一個高速數據存儲及調度核心,集成了Die-to-Die接口和其他多種高速接口,能把各個節點通過Kiwi Fabric網絡互連起來,再通過一套自定義算法來實現數據流、信息流的分發調度。
3D Base Die:在IO Die的基礎上,奇異摩爾研發了全球首款的通用的3D Base Die。通過芯粒3D堆疊,能進一步提升芯片算力密度。同時,通過集成die-to-die 3D接口,Cache等模塊以實現更高效的垂直互聯,最大程度的減少存儲本身帶來的延遲和功耗。
奇異摩爾為客戶提供基于IO Die和Base Die的完整解決方案,基于核心互聯芯粒,客戶只需設計少量功能單元,即可搭建產品系列平臺,能極大地降低研發及量產的成本。奇異摩爾的解決方案覆蓋數據中心、自動駕駛、邊緣AI、5G、6G移動通信等需要大算力芯片的領域。客戶可以最高提升芯片的系統性能至1.5倍,并實現研發成本(80%)和量產時間(60%)的下降。
演講最后,祝俊東表示,奇異摩爾作為一家創新的Chiplet產品及解決方案公司,其愿景是“為了更簡單的計算”貢獻力量,并呼吁各位客戶及合作伙伴共同發力,構建未來智能計算的新范式。