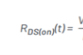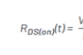IDF:大數據處理技術英特爾發力
2012-04-14 22:56:55 本站原創IDF 2012英特爾信息技術峰會于4月11日、12日在北京國家會議中心隆重舉行,本屆IDF將以“未來在我‘芯’”為主題,作為全球IT技術的領導者,英特爾再次針對未來的技術趨勢及發展做了講解,包括云計算、下一代數據中心、以及大數據方面的內容。
我們正面臨著“大數據工業革命”,大量的數據源(包括網絡日志、點擊流、電話記錄、醫療記錄、傳感器和監控攝像頭)蜂擁而至,世界上充斥著各種形式的巨量數據。大數據種類豐富,充滿挑戰,它們不僅包含傳統的結構化(或關聯型)數據,而且也包含各類非結構化數據。這些數據不僅尺寸龐大,而且增長速度更快于摩爾定律(每兩年即加倍)。本技術解析將探索大數據對企業、技術計算和云的影響,排序業界必須定為目標的基礎性技術,并充分了解可從從這些巨量數據中得出的觀點。

大數據的浪潮有多迅猛?IDC在2006年估計全世界產生的數據量是0.18ZB(1ZB=100萬PB),而今年這個數字已經提升了一個數量級,達到1.8ZB,差不多對應全世界每個人一塊100多GB的硬盤。這種增長還在加速,預計2015年將達到近8ZB。

現今大數據呈現出“4V + 1C”的特點。既Variety:一般包括結構化、半結構化和非結構化等多類數據,而且它們處理和分析方式有區別;Volume:通過各種設備產生了大量的數據,PB級別是常態;Velocity:要求快速處理,存在時效性;Vitality:分析和處理模型必須快速變化,因為需求在變;Complexity:處理和分析的難度非常大。
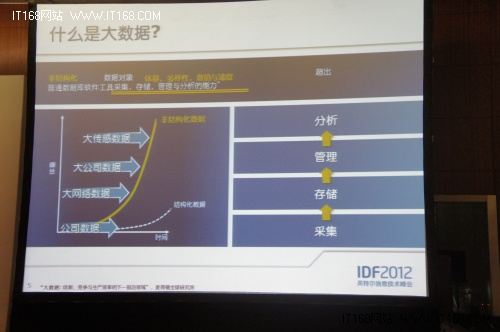
現在的大數據中主要的是非結構化的數據,這些數據不能被很好的管理。現有的技術對于這些數據的管理和利用能力有限,以至于大量的數據浪費。
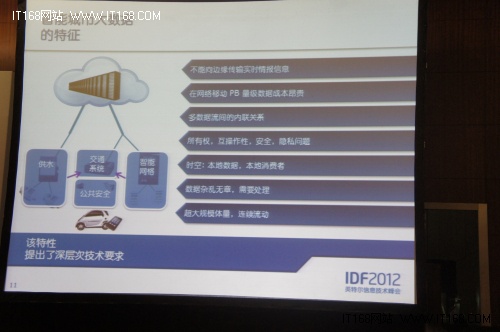
大數據在物聯網中有著重要的位置。在技術發展中智能城市將會產生大量的需要實時傳輸的信息,面臨著數據的雜亂性,本地性,和超大規模性。
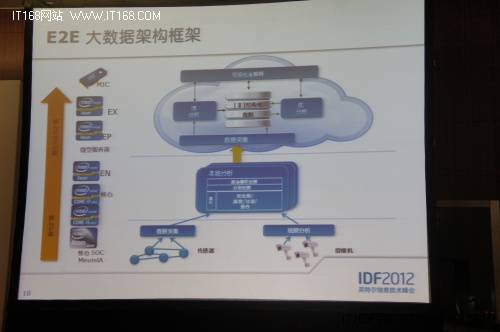
基于大數據的盛行,英特爾利用不同級別的處理器架構不同的數據應用架構,以及相關的解決方案。幫助用戶從端到端找到完整的解決辦法。