僅用語音,AI 就能“腦補”你的臉!
2019-04-11 09:21:42 嵌入式資訊精選
談到這項研究的貢獻,主要有三點:
論文收集了大V用戶(Youtubers)上傳到 Youtube 的演講視頻,這些視頻通常具有高質量的說話環境、表達方式、人臉特征等。Youtubers 數據集主要由兩部分組成:一個是自動生成的數據集和一個手動處理后的高質量的子集。
主要的預處理工作:
方法介紹
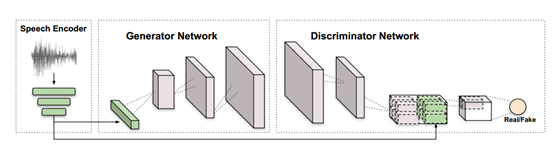
研究主要由三個模塊構成:一個是語音編碼器,一個是圖片生成網絡,一個是圖片判別網絡。
語音編碼器(Speech Encoder):已有的方法大多數是手工提取音頻特征,并不是針對生成網絡的任務進行優化的,而 SEGAN 提出了一種在波形上用于語音處理的方法。因此作者在已有的工作 SEGAN 上進行修改。修改為具有 6 層一維網絡,并且每層的 kernel 大小是 15x15,步長為 4,然后每層卷積網絡后面使用 LeakyReLU 激活函數,網絡的輸入通道是 1。輸入 16kHZ 下1 秒的語音片段,上述的卷積網絡可以得到一個 4x1024 的張量,然后采用三個全連接網絡將特征數量從 4x1024 降到 128。作為生成器網絡的輸入。
圖片生成器(Image Generator Network):輸入是語音編碼器的 128 向量。采用二維轉置卷積、插值、dropout 等方式將輸入轉為 64x64x3 或者 128x128x3 的張量。在 G 的損失函數中添加了一個輔助損失用于保持說話人的標簽(Identity)。
圖片判別器(Image Discriminator Network):判別器由幾層步長為 2,kernel 大小是 4x4 的卷積網絡組成,并使用譜歸一化和 LeakyReLU 激活函數。當張量為 4x4 時,作者拼接了語音的輸入,并采用最后一層網絡來計算 D 網絡的分數。
實驗過程
訓練:將手動處理后的數據集作為訓練集,采用數據增強等手動。值得注意的是,在處理時將每張圖像復制了 5 次,并將其與 4 秒音頻里面隨機采樣的 5 個不同的1秒音頻塊進行匹配。因此總共有 24K 左右的圖像-音頻對用于模型訓練。其它超參數采用參考的文獻設置。
評估:下圖給出了可視化的結果,雖然生成的圖像都比較模糊,但基本可以觀察到人的面部特征,并且有不同的面部表情。

作者進一步微調了一個預訓練的 VGG-FACE Descriptor 網絡,用于量化測試結果,在作者提供的數據集上,可以達到 76.81% 的語音識別準確率和 50.08% 的生成圖像準確率。
為了評估模型生成圖像的真實程度,作者定義了一個 68 個人臉關鍵點的精度檢測分數。如下圖所示,測試結果精度可以達到 90.25%。表明在大多數情況下生成的圖像保留了基本的面部特征。