一圖讀懂人工智能的是是非非
2017-05-03 20:22:10 知識分子導語:
說起人工智能,大家想到的都是各種科幻電影、漫畫中各種像人一樣有自我意識、能思考復雜問題的機器人。它們除了沒有血肉之軀,不容易感情用事,記憶力和計算能力特別出色之外,簡直跟我們人類沒有什么區別。
圖文 | 菠蘿科學獎
責編 | 葉水送
有的人認為,我們擁有了人工智能之后,就等于擁有大量不怕苦不怕累的廉價勞動力。它們不但能替人類做體力勞動,還能替人類做腦力勞動,很多時候比人類做的還要好。

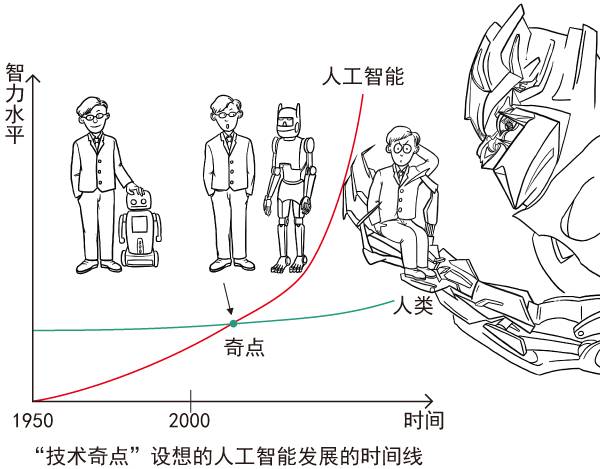
也有人認為,人工智能看起來很美好,但實際上非常危險,人類必須小心。1993年,著名科幻作家弗諾·文奇提出了“技術奇點”理論。他認為,一旦人工智能出現,它們就會不斷學習,不斷改進自己,變得越來越聰明,而且變聰明的速度會越來越快,引發“智能技術的爆炸”(即技術奇點)。最后,它們發展出了一種在各方面都碾壓人類的超級人工智能,從此,人類的時代將會終結。
科幻小說甚至常常設想人工智能擁有了反抗意識,試圖消滅人類。

有識之士不斷發出警告,呼吁我們限制人工智能的研究,警惕人工智能的潛在風險。

然而,這些討論都或多或少脫離了我們的現實。霍金等人雖然很聰明,但他們畢竟沒有親自從事人工智能的研究。也許,他們的設想就像150多年前的科幻作家一樣,以為通過一門巨型大炮就可以將人類送往月球。雖然我們最終登上了月球,但我們用的是火箭,而不是大炮。

也許,他們的設想就像人工核聚變一樣,長期處于“再過30年就能實現”的樂觀中。但實際上過了好幾個30年,卻仍然沒有實現。

無論如何,人工智能的應用已經滲透到了我們生活中的方方面面。未來無法阻擋,未來就在我們腳下。與其白日做夢,患得患失,我們不如客觀地了解一下,現在的人工智能到底是怎么回事。

人工智能的發展歷史
機器到底能不能思考?計算機科學家艾茲赫爾·戴克斯特拉認為,這個問題就相當于問“潛水艇能不能游泳”。如果游泳的定義是“利用四肢、鰭或尾巴在水中前進”,那么潛水艇肯定不會游泳,因為它既沒有胳膊也沒有腿。
但是,這種咬文嚼字的定義顯然是荒謬的。潛水艇顯然會“游泳”,只不過不是我們所設想的那種游泳。同樣的道理,機器也能“思考”,只不過不是我們所設想的那種思考。我們可以說,機器在通過計算機程序模擬人類的思考,使得自己在某些具體的任務中,像人類一樣能看、能聽、能想、能說、能動。
1950年,阿蘭·圖靈發表了一篇論文,叫做《計算機器與智能》。他提出,與其去研究機器到底能不能思考,還不如去讓機器參加一個智能的行為測試,也就是圖靈測試。
在圖靈測試中,一個計算機程序通過在屏幕上打字跟一個人進行5分鐘的在線聊天。這個人需要判斷,跟他聊天的是一個計算機程序還是一個大活人。如果一個計算機程序有30%的幾率讓別人誤以為自己是一個大活人,那么它就通過了圖靈測試。我們就可以說這個程序學會了“思考”。
圖靈預計,在2000年時,計算機可以存儲1GB的信息。人類在這樣的計算機上就能編寫一個能夠通過圖靈測試的程序。實際上,圖靈的設想并沒有實現,現在還沒有任何一個計算機程序能夠騙過聰明的人類裁判。并且,很少有人工智能科學家關心圖靈測試。他們主要關心的是如何讓自己的人工智能程序像人類一樣,能夠“聰明地”完成某個具體的實際任務,比如駕駛汽車。

為了讓機器能夠通過某種計算機程序學會“思考”,人類科學家嘗試了各種各樣的方法,付出了幾代人的努力,熬過了兩次低谷,經歷了三次高潮。

人工智能的三大驅動要素
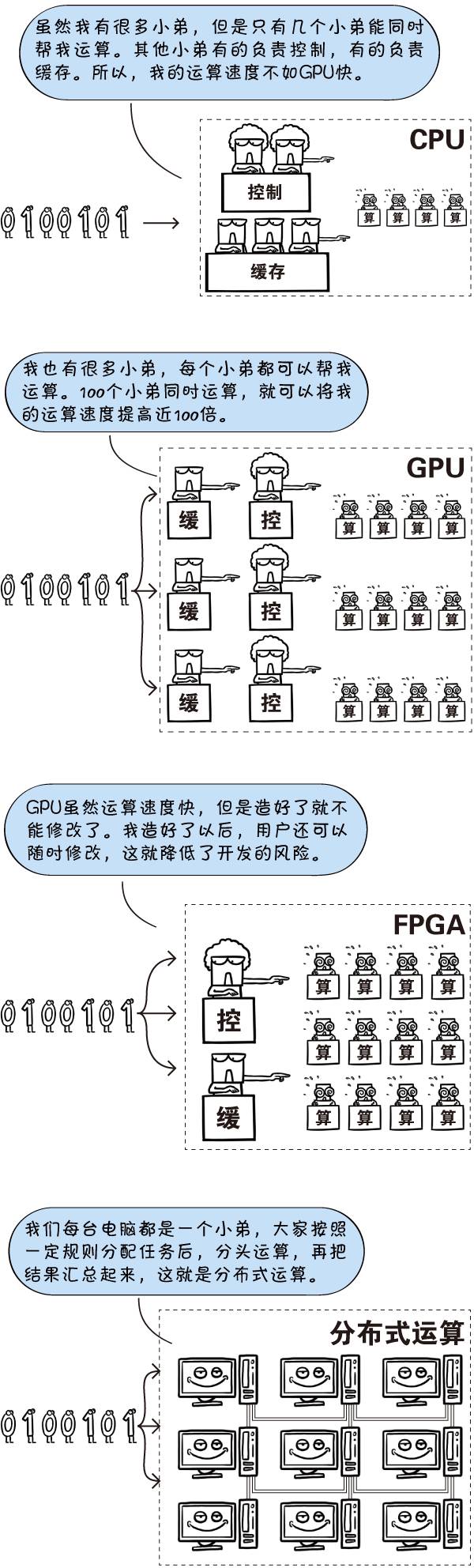
人工智能之所以能在近年來掀起新一輪高潮,主要是因為三大驅動要素:算法、大數據、運算能力。
算法:概括地說,計算機主要干三件事,一是輸入,二是運算,三是輸出。不論輸入什么,在計算機看來都是一堆數據。不論輸出什么,在計算機看來也都是一堆數據。研究人工智能的計算機程序,很多時候是在研究“聰明的算法”,能夠適應各種各樣的實際情況,讓計算機程序通過運算,從輸入的數據出發,正確而高效地得出應該輸出的結果。在這一輪人工智能的熱潮中,機器學習的算法發揮了重要的作用。

什么叫算法?
當你交給計算機一個任務的時候,不但要告訴它做什么,還要告訴它怎么做。關于“怎么做”的一系列指令就叫做算法。
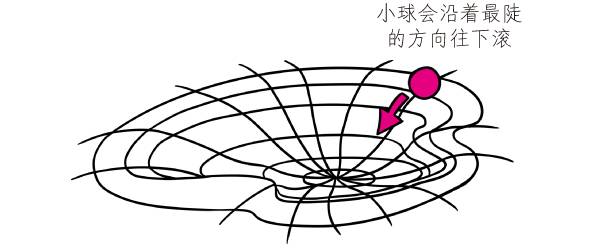
比方說,你輸入一個峽谷的等高線地形圖,讓計算機找到其中海拔最低的地方。你需要告訴計算機,從地形圖的左上角開始向右走,一行一行地來回掃描,走遍整張圖之后,比較所有經過的地方的海拔高度,最終找到那個最低的地方。這就是一種算法,只不過這種算法效率很低,看起來很“笨”。

聰明的人會用聰明的算法。例如,讓計算機把自己想象成一個小球,從圖中峽谷的任意一個地方開始往下滾。如果滾到一個地方滾不動了,那個地方就是海拔最低的地方。這種聰明的算法叫做“梯度下降法”。如果將來你要學習人工智能,這可能是你要掌握的第一個算法。
什么叫機器學習?
很多時候,計算機工程師不可能像諸葛亮一樣,把所有可能發生的情況都提前預料到,然后把應對方法寫入幾個錦囊之中,讓計算機遇到問題時就打開其中一個看。計算機只要按照提前準備好的方法應對,就能渡過難關。
為了完成更加復雜的任務,工程師必須讓計算機變得再聰明一些,能夠自動“學習”,從已有的歷史數據和經驗中自動分析,總結出規律。隨后,計算機就可以利用自己總結出來的規律,對新輸入的數據進行預測。這就是機器學習算法。
例如,你把杭州所有房子的價格和它們的面積、學區、建造時間以及周圍的交通情況等信息輸入計算機,通過機器學習算法,計算機就能學到“大致判定杭州一個房子的價格的規律”。

上面那個例子很簡單,可能你覺得不必勞煩計算機去學習,直接告訴它規律就可以了。但是有些規律雖然你自己能夠領悟,但你卻無法翻譯成機器能理解的算法。例如,如何把一張照片變成一幅像是梵高畫過的油畫?如何讓語音合成旗模仿一個名人的聲音?如何讓一個六條腿的機器狗適應各種野外地形?如何讓一家電商的服務器猜出一個新用戶可能想要買什么商品?這個時候就要靠機器學習了。

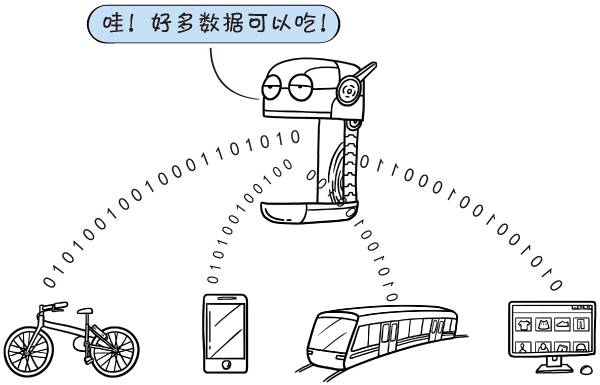
大數據:既然要讓機器努力學習,就得有東西(“大量數據”)可學。人類每時每刻的每個行為都可以變成數據,但在前互聯網時代,這些數據都不可能輕易地記錄和保存下來。隨著互聯網和物聯網的發展,隨著網絡帶寬不斷增加,隨著存儲的硬件成本不斷降低,全球人類產生的數據在爆發性增長,為人工智能的發展提供了源源不斷的營養。
運算能力:大數據的營養有了,計算機程序還要經過大量運算,才能對這些營養進行“消化”、“吸收”,變成各種各樣的“模型”,才能夠模擬人類的智能。從前,科學家使用傳統的CPU進行模型訓練,運算過程少則幾天,多則幾個星期,效率非常低。應用了GPU、FPGA和分布式運算等新的運算加速技術以后,模型訓練的效率大大提高。有實際應用價值的人工智能程序一個接一個地涌現了出來。
人工智能近期可以用在哪里?
從理論上講,人類能夠完成的任何一種重復的勞動,甚至人類無法完成的許多重復的勞動,都能用人工智能的算法進行機器學習。一旦模型訓練成功,它們就可以在這些學過的具體任務中,像人類一樣能看、能聽、能想、能說、能動。
實際上,科學界和企業界對人工智能的應用,依賴于每個領域的具體使用場景。下面,我們從與日常生活相關的領域出發,簡要地介紹人工智能的幾個使用場景。
醫療:每天都有很多人去醫院看門診,做檢查,接受治療。假設一個專家每天看30個病人,全年無休,經過30年的艱苦訓練,也只能看完33萬個病人。而且,如果他這樣不要命地看病,就沒有辦法讀論文,參加學術會議,學習最新的醫學研究成果。
同時,根據IBM的資料,僅僅在上海市衛生信息系統,每天生產的數據就高達1000萬條,已建立起的電子健康檔案達3000萬,信息總量已達20億條。這些資料靠人力根本不可能看完,只能依靠擁有人工智能的計算機。
例如,根據日本媒體報道,有位 66 歲的女病人山下女士罹患罕見的「急性骨髄性白血病」,IBM的人工智能系統Watson 在她病情突然惡化,意識不清的緊急狀況下,只用了 10分鐘就從 2000 萬份論文中找到了依據,精確判斷了她的病癥,并找出了最適合的療法治療成功。

安防:為了偵破案件,公安部門常常要調取公共場所和道路兩側的監控錄像。應用了人工智能技術之后,計算機在破案時可以從視頻畫面中,識別可疑人員的特征,快速確定可疑人員的身份,并綜合解決查人、找人、預警、追蹤等的人員管理監控問題。計算機也可以在視頻畫面中,識別車輛信息,幫助失主追回被盜的汽車。

金融:全球的證券市場每天都會產生大量交易數據。著名對沖基金橋水曾經利用人工智能技術,通過這些歷史數據和統計概率預測未來。這個程序能隨著市場的變化而變化,不斷適應新的趨勢,而不是一成不變的。

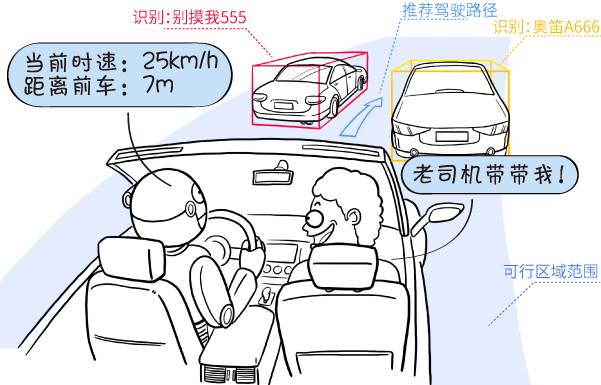
交通:在汽車上安裝了攝像頭之后,無人駕駛的科學家就可以訓練計算機從視頻圖像中,學習識別周圍的物體和環境,檢測可行區域的范圍,并判斷車該往哪里開。
新聞業:美國有一家叫做敘事科學的公司,在2010年就推出了一款名為Quill的寫作軟件,能從不同角度將數字轉化為有故事情節的敘述文。Quill曾被用來撰寫電視及網絡上棒球賽事的比賽報告,福布斯網站曾使用該公司的技術自動制作財報和房地產相關報告等。

語音識別和語音合成:只要給人工智能軟件投喂足夠多的語料庫,理論上它可以模仿任何一個人的聲音。你想讓它說什么,它就能按照那個人的聲音說什么。甚至還能用奧巴馬的聲音說帶口音的漢語。

自然語言處理:時間就是金錢,浪費你的時間就是浪費你的錢。垃圾郵件不但浪費你的時間,浪費你的帶寬,有時候還給你設下騙局,妄圖直接騙走你的錢。應用了人工智能技術之后,許多郵箱的垃圾郵件大大降低了,有些郵件服務商甚至將垃圾郵件比例降到了0.1%。

機器人裝置:雖然機器貓八字還沒一撇,但是機器狗,機器驢,機器蜘蛛都已經發明出來了。它們能站,能走,能跑,能爬,上山不打顫,下雪不怕滑。

科學研究:歐洲核子中心的大型強子對撞機,每秒鐘能夠產生幾億次對撞,但這些數據并不是全都能派上用場,科學家只能用快速而粗糙的標準篩選出其中區區1/1000的事件。科學家計劃在未來的加速器中安裝人工智能程序,將更多可能蘊含著新發現的工作交給它。

電子商務:當你在網上開心地剁手的時候,你可知道自己也在不知不覺地用到了人工智能技術?利用機器學習、數據挖掘、搜索引擎、自然語言處理等多種技術,各種買買買的網站都能根據用戶在網站中的點擊、瀏覽、停留、跳轉、關閉等行為,猜出你大概是哪種人,可能會喜歡什么,然后把你可能喜歡的商品推薦到你眼前,讓剁手來得更猛烈些。

看完這份小資料之后,你有沒有人工智能沒那么神秘,沒那么可怕了呢?其實,人工智能技術的發展就像人類之前遭遇過的每一項技術突破一樣,既會給我們帶來好處,也會給我們帶來問題。鼓吹人工智能也好,警惕人工智能也好,我們不如先冷靜下來,踏踏實實地搞清楚人工智能到底是什么,理性地迎接未來的降臨。
附錄:機器到底是怎么學習的?(本節內容專門為有好奇心的讀者而設)
從算法的角度看,機器學習有很多種算法,例如回歸算法、基于實例的算法、正則化算法、決策樹算法、貝葉斯算法、聚合算法、關聯規則學習算法和人工神經網絡算法。很多算法可以應用于不同的具體問題;很多具體的問題也需要同時應用好幾種不同的算法。由于篇幅有限,我們僅介紹其中(可能是公眾心目中名氣最大的)一種:人工神經網絡。
人工神經網絡:
既然人工智能要模擬人類的思考過程,一些人工智能科學家想,不如我們先看看人類是怎樣思考的吧?
人類的大腦是一個復雜的神經網絡。它的組成單元是神經元。每一個神經元看起來很簡單,它們先接收上一個神經細胞的電信號刺激,再向下一個神經細胞發出電信號刺激。
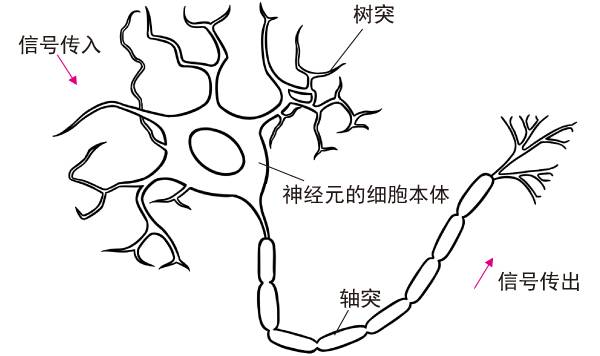
別看神經元細胞很簡單,但如果神經元的數量很多,它們彼此之間的連接恰到好處,變成神經網絡,就可以從簡單中演生出復雜的智能來。例如,人類的大腦中含有1千億個神經元,平均每個神經元跟其他的神經元存在7000個突觸連接。一個三歲小孩大腦中,大約會形成1千萬億個突觸。隨著年齡的增長,人類大腦的突觸數量會逐漸減少。成年人的大腦中,大約會有1百萬億到5百萬億個突觸。
雖然科學家還沒有完全搞清楚人類大腦的神經網絡的運作方式,但人工智能科學家想,不理解沒關系,先在計算機中模擬一組虛擬的神經網絡試試看,這就是人工神經網絡。
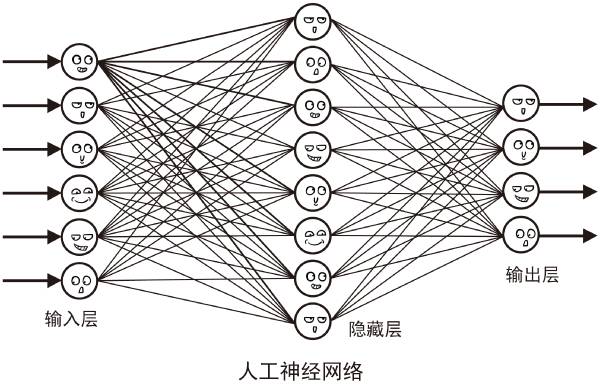
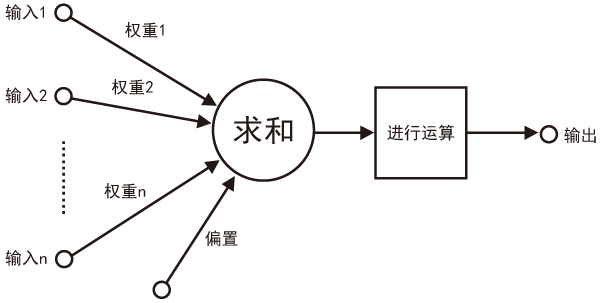
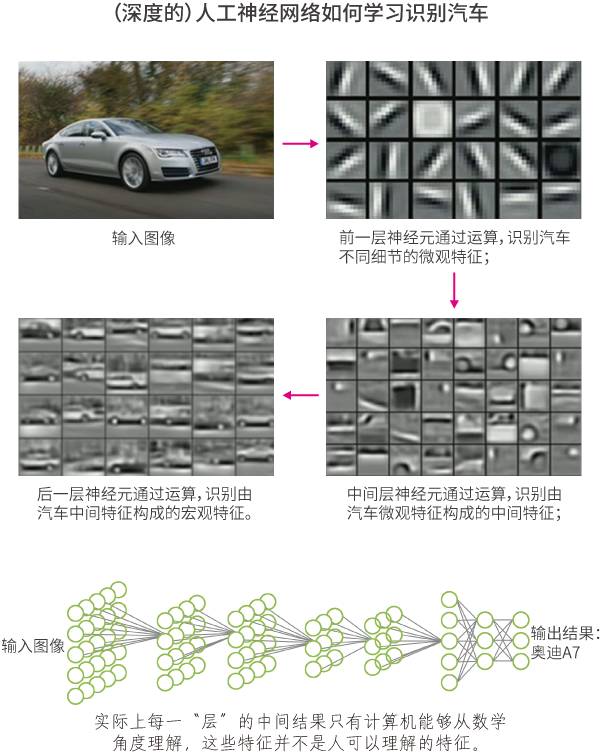
在人工神經網絡中,每一個小圓圈都是在模擬一個“神經元”。它能夠接收從上一層神經元傳來的輸入信號(也就是一堆數字);根據不同神經元在它眼中的重要性,分配不同的權重,然后將輸入信號按照各自的權重加起來(一堆數字乘以權重的大小,再求和);接著,它將加起來結果代入某個函數(通常是非線性函數),進行運算,得到最終結果;最后,它再將這個結果輸出給神經網絡中的下一層神經元。
人工神經網絡中的神經元看起來很簡單,只知道傻傻地將上一層神經元的輸入數據進行簡單的運算,然后再傻傻地輸出。沒想到這一套還真的很管用,運用一系列精巧的算法,再給它投喂大量的數據之后,人工神經網絡居然能夠像人腦的神經網絡一樣,從復雜的數據中發現一系列“特征”,產生“聰明的思考結果”。
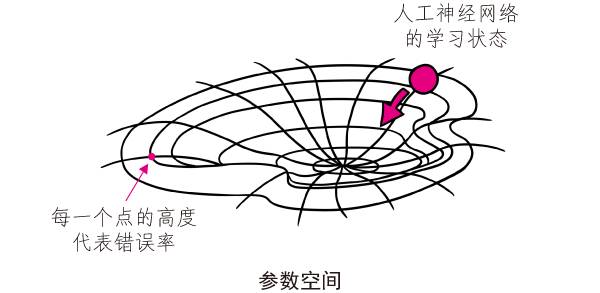
那么人工神經網絡是怎么學習的呢?所謂的學習,本質上是讓人工神經網絡嘗試調節每一個神經元上的權重大小,使得整個人工神經網絡在某一個任務的測試中的表現達到某個要求(例如,識別汽車的正確率達到90%以上)。
請回憶一下前面講過的“梯度下降法”。人工神經網絡嘗試不同的權重大小,相當于在一個參數空間的地圖上四處游走。每一種權重的組合對應的人工神經網絡執行任務時的錯誤率,相當于這個地圖上的每一點都有一個海拔高度。尋找一組權重,使得人工神經網絡的表現最好,錯誤率最低,就相當于在地圖上尋找海拔最低的地方。所以,人工神經網絡的學習過程,常常要用到某種“梯度下降法”,這就是為什么如果將來你要學習人工智能,第一個要掌握的就是“梯度下降法”。
機器學習的分類:
從學習風格的角度看,機器學習有很很多種學習方法,我們簡要地列舉其中幾種方法:監督學習、非監督學習、強化學習和遷移學習。
監督學習:比方說,你想教計算機如何識別一張照片上的動物是不是貓。你先拿出幾十萬張動物的照片,凡是有貓的,你就告訴計算機有貓;凡是沒有貓的,你就告訴計算機沒有貓。也就是說,你預先給計算機要學習的數據進行了分類。這相當于你監督了計算機的學習過程。
經過一段監督學習的過程之后,如果你再給計算機看照片,它就能認出照片中有沒有貓。

非監督學習:比方說,你想教計算機區分貓和狗的照片。你拿出幾十萬張貓和狗的照片(沒有其他動物)。你并不告訴計算機哪些是貓,哪些是狗。也就是說,你沒有預先給計算機要學習的數據進行分類,所以你并沒有監督計算機的學習過程。

經過一段監督學習的過程之后,計算機就能把你輸入的照片按照相似性分成兩個大類(也就是區分了貓和狗)。只不過計算機只是從數字照片的數學特征的角度進行了分類,而不是從動物學的角度進行了分類。

強化學習:比方說,你想教計算機控制一只機械臂打乒乓球。一開始,計算機控制機械臂像傻瓜一樣,拿著球拍做很多隨機的動作,完全不得要領。
但是,一旦機械臂湊巧接到一個球,并把球擊打到對手的球桌上,我們就讓計算機得一分,這叫做獎勵。一旦機械臂沒有正確地接到球、或沒有把球擊打到正確的位置上,我們就給計算機扣一分,這叫做懲罰。經過大量的訓練之后,機械臂漸漸地從獎勵和懲罰中,學會了接球、擊打球的基本動作。
遷移學習:比方說,你讓計算機學會了控制機械臂打乒乓球之后,又叫它學習打網球。這個時候,你不需要讓計算機從零開始重新學,因為乒乓球和網球的規則是相似的。例如,這兩種球都要把球擊打到對方的球場/球桌上。所以,計算機可以將之前學到的動作遷移過來。這樣一種學習,就叫做遷移學習。