機器學習追根溯源:和計算機技術一樣久遠
2017-03-04 21:20:34 TechCrunch中文版媒體有關機器學習的輪番報道或許讓人誤以為我們剛剛發現了什么全新的東西,但事實上這項技術的年代幾乎與計算機一樣久遠。
作為史上最富盛名的計算機科學家之一,阿蘭·圖靈(Alan Turing)早在1950年一篇有關計算機的文章中,就提出了“機器人能思考嗎?”這一問題。從科幻小說到研究實驗室,我們很早以前就提出了這樣一個問題,即人工智能的誕生是否有助于我們發現自我意識的起源,或者從更廣泛的意義上講,有助于發現人類的具體作用。不幸的是,人工智能的學習曲線過陡,盡管如此,我們仍然希望通過追根溯源,能真正明白人工智能究竟是什么東西。
如果我的大數據足夠大,是不是我也能創造智能?
我們復制自身的首次嘗試就是人為干擾充滿信息的機器,希望能獲得最好的結果。說真的,曾幾何時,有關意識的主流理論是,它源于匯聚在一起的海量信息。有些人認為,谷歌的誕生預示著這種愿景走向巔峰。然而,盡管谷歌對30萬億個網頁建立了索引,我并不認為人們覺得搜索引擎會問我們世上是不是真的有上帝。
相反,機器學習的妙處恰恰在于,我們不是將計算機假裝變成人類,然后不斷灌輸知識,而是幫助計算機進行推理,令其將自己學到的東西歸納總結為新的信息。
雖然神經網絡、深度學習和強化學習(reinforcement learning)這些概念都不太好理解,但這些都是機器學習。它們都是創建可對新數據進行分析的廣義系統的方法。換言之,機器學習只是諸多人工智能方法的一種,神經網絡和深度學習之類的東西只是工具而已,可以被用于創建應用范圍更廣、更好用的構架。
在上世紀50年代,我們的計算能力是有限的,大數據還是一個陌生的字眼,我們的算法也相當初級。這意味著,我們推進機器學習研究的能力相當有限。然而,這并未阻止人們勇于嘗試的腳步。
1952年,亞瑟·塞繆爾(Arthur Samuel)利用最基本的人工智能形式——Alpha-Beta剪枝算法——開發了一個跳棋程序。這種方法通過運用代表數據的“搜索樹”(search tree)來減少計算量,但這并不是解決一切問題的最佳方法。多年以前,隨著弗蘭克·羅森布拉特(Frank Rosenblatt)感知器(perceptron)的問世,神經網絡終于露出廬山真面目。
復雜的聲音模型
弗蘭克·羅森布拉的感知器的確具有超前性,充分利用神經系統科學來推進機器學習研究。從理論上講,這個創意就像下圖所示。
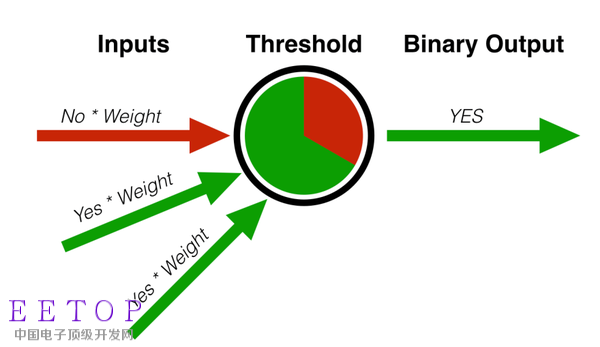
若想搞清楚圖中所表達的意思,首先必須明白大部分機器學習問題可以被分解為分類(classification)或回歸(regression)。分類器(Classifier)一般用于對數據進行歸類,而回歸模式則主要是推算我們的趨勢,然后進行預測。
弗蘭克·羅森布拉的感知器即是分類器的一個 典型例證——它提取了一套數據,然后將其分為多個數據集。在這種情況下,兩個具有不同重量的特征的存在,足以讓這個物體被歸為“綠色”類別。今天的分類器可以將垃圾郵件從收件箱中分離出去,幫助銀行發現欺詐活動。
羅森布拉的感知器模式利用一系列輸入手段,思考長度、重量、顏色等特征,然后給每一種特征指派重量。接著,這個模型不斷調節重量,直至輸出的重量也減少至那種程度,而誤差也在可接受的范圍內。
例如,一個人可以輸入數據,物體(碰巧是蘋果)的重量是100克。計算機并不知道物體是蘋果,但感知器可以通過已知數據集來調節分類器的重量,最終將該物體歸類為像蘋果的物體或不像蘋果的物體。一旦分類器被調整,它可以在數據集上重新使用,前提是這個數據集之前從未暴露過,被用于分類未知物體。
連人工智能研究人員都被這種東西搞懵了

感知器只是機器學習所取得的諸多早期進步之一。神經網絡有點像是協同工作的感知器的大合集,酷似我們大腦和神經工作機制——也是神經網絡這一名稱的由來。
在之前的幾十年,人工智能領域的進步始終與復制大腦工作機制有關,而不是復制我們頭腦中對其內容的認識。基本或“淺層”神經網絡至今仍在使用之中,但深度學習就像“下一個大事件”一樣備受歡迎。深度學習模式是具有多層的神經網絡。對于這種讓人極不滿意的解釋,人們正常的反應是,會問我“層”的意思究竟是什么。
若想搞清楚這一點,我們必須要記住,我們只能說計算機可以將貓咪和人類分成兩個不同的組群,但計算機本身不能像人類那樣處理這種任務。機器學習構架則充分利用抽象概念來完成任務。
對于人類來說,臉上有眼睛;對于計算機來說,它看到的是一張張具有明暗像素的面孔,這些像素構成了我們對線條的想象。深度學習模型的每一層可以讓計算機識別相同物體的另一個抽象水平。像素之于線條,就像是2D之于3D幾何。
盡管顯得異常笨拙,計算機已經通過了圖靈測試
人類與計算機評估世界的方式存在著根本的不同,這對我們創建真正人工智能的嘗試構成很大的挑戰。圖靈測試已經概念化,用以評估我們在人工智能領域取得的進步,但它很大程度上忽略了這種事實。圖靈測試是行為主義者測試,旨在評估計算機模仿人類輸出的能力。
但是,模仿和概率推理充其量只是智能與意識之謎的一部分。有些人認為,我們在2014年成功通過了圖靈測試,當時機器讓30位科學家中的10位誤以為,在持續5分鐘的交流中,主角是人而不是鍵盤。
我應該穿上夾克抵御AI寒冬嗎?
盡管取得了進步,但科學家和創業者很快就在人工智能的能力上做出了過多的承諾。由此導致的繁榮與蕭條周期通常被稱為“AI寒冬”。
我們能用機器學習從事一些令人難以置信的事情,比如對自動駕駛汽車車載屏幕上的物體進行分類,通過衛星圖對農作物產量做出估計。漫長的短期記憶有助于機器搞清楚一些事情的時間序列,比如說視頻中的情緒分析。強化學習從游戲理念中獲取靈感,其中包含一種通過獎勵來輔助學習的機制。強化學習正是Alpha Go可以戰勝圍棋世界冠軍李世石的利器。
盡管取得了所有這些進步,但機器學習的最大秘密在于,盡管我們往往知道某個問題的信息輸入與輸出,但我們始終不能確定這個模型是如何從輸入過渡到輸出的。研究人員將這種挑戰稱為機器學習的“黑箱問題”。
在變得心灰意冷之前,我們一定要記住,人類大腦本身就是一個“黑箱”。我們并不知道大腦的確切工作機制,不能在每個抽象水平下對其進行分析。如果我要求你分析大腦并搞清楚大腦中的記憶,我會被外人看作瘋子。然而,我們不能就此認為,游戲已經結束,相反,游戲才剛剛開始。