AlphaGo是如何被訓練成圍棋之神的?
2017-02-03 20:22:42 n編者按:本文作者為彩云天氣創始人兼 CEO 袁行遠,由雷鋒網整理自其知乎專欄,獲授權發布。
袁行遠:19年前計算機擊敗國際象棋冠軍卡斯帕羅夫的情景還歷歷在目,現在計算機又要來攻克圍棋了嗎?

虛竹在天龍八部里自填一子,無意中以“自殺”破解“珍籠”棋局,逍遙子方才親傳掌門之位。難道以后“阿爾法狗”要出任逍遙派掌門了?
1933年,東渡日本19歲的吳清源迎戰當時的日本棋壇霸主、已經60歲的本因坊秀哉,開局三招即是日本人從未見過的三三、星、天元布陣,快速進擊逼得對方連連暫停“打卦”和弟子商量應對之策。隨后以“新布局”開創棋壇新紀元。難道阿爾法狗會再造一個“新新布局”?
作為一個關心人工智能和人類命運的理科生,近些天刷了好些報道,記者們說“阿爾法狗是個‘價值神經網絡’和‘策略神經網’絡綜合蒙特卡洛搜索樹的程序”,但我覺得光知道這些概念是不夠的。我想看看“阿爾法狗”的廬山真面目。
準備好棋盤和腦容量,一起來探索吧?

圍棋棋盤是19x19路,所以一共是361個交叉點,每個交叉點有三種狀態,可以用1表示黑子,-1表示白字,0表示無子,考慮到每個位置還可能有落子的時間、這個位置的氣等其他信息,我們可以用一個361 * n維的向量來表示一個棋盤的狀態。我們把一個棋盤狀態向量記為s。
當狀態s下,我們暫時不考慮無法落子的地方,可供下一步落子的空間也是361個。我們把下一步的落子的行動也用361維的向量來表示,記為a。
這樣,設計一個圍棋人工智能的程序,就轉換成為了,任意給定一個s狀態,尋找最好的應對策略a,讓你的程序按照這個策略走,最后獲得棋盤上最大的地盤。
如果你想要設計一個特別牛逼驚世駭俗的圍棋程序,你會從哪里開始呢?對于在谷歌DeepMind工作的黃士杰和他的小伙伴而言,第一招是:
深度卷積神經網絡
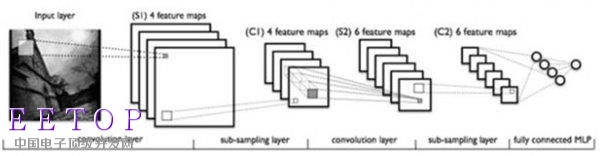
深度卷積神經網絡早在98年就攻克了手寫數字識別,近些年在人臉識別、圖像分類、天氣預報等領域無往而不利,接連達到或超過人類的水平,是深度學習火遍大江南北的急先鋒。我們現在看到的Picasa照片自動分類,Facebook照片識別好友,以及彩云小譯同聲傳譯(軟廣出現,不要打我)都是此技術的應用。這等天賜寶物,如果可以用來下圍棋,豈不是狂拽酷炫吊炸天?
所以2015年黃士杰發表在ICLR的論文一上來就使出了“深度神經網絡”的殺招,從網上的圍棋對戰平臺KGS(外國的qq游戲大廳)可以獲得人類選手的圍棋對弈的棋局。觀察這些棋局,每一個狀態s,都會有一個人類做出的落子a,這不是天然的訓練樣本嗎?如此可以得到3000萬個樣本。我們再把s看做一個19x19的二維圖像(具體是19x19 x n,n是表示一些其他feature),輸入一個卷積神經網絡進行分類,分類的目標就是落子向量a’,不斷訓練網絡,盡可能讓計算機得到的a’接近人類高手的落子結果a,不就得到了一個模擬人類棋手下圍棋的神經網絡了嗎?
于是我們得到了一個可以模擬人類棋手的策略函數P_human,給定某個棋局狀態s,它可以計算出人類選手可能在棋盤上落子的概率分布a = P_human(s),如下圖:

紅圈就是P_human覺得最好的落子方案。每一步都選擇概率最高的落子,對方對子后再重新計算一遍,如此往復就可以得到一個棋風類似人類的圍棋程序。
這個基于“狂拽酷炫”深度學習的方案棋力如何呢?
不咋地。黃士杰說P_human已經可以和業余6段左右的人類選手過招,互有勝負,但還未能超過當時最強的電腦程序CrazyStone[1,5],距離人類頂尖玩家就差得更遠了。
所以,為求更進一步,黃士杰打算把P_human和CrazyStone的算法結合一下,師夷長技以制夷,先擊敗所有的其他圍棋AI再說。
等等,CrazyStone的算法是什么?
哦,那個算法是黃士杰的老師Remi Coulum在2006年對圍棋AI做出的另一個重大突破:
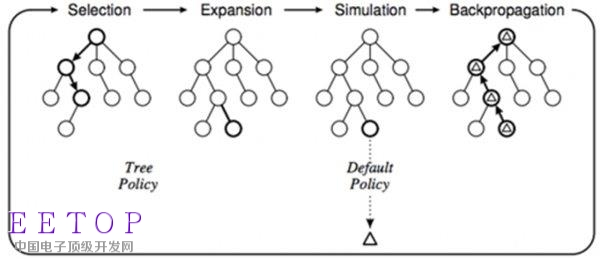
MCTS,蒙特卡洛搜索樹

蒙特卡洛搜索樹(Monte-Carlo Tree Search)是一種“大智若愚”的方法。面對一個空白棋盤S0,黃士杰的老師Coulum最初對圍棋一無所知,便假設所有落子方法分值都相等,設為1。然后扔了一個骰子,從361種落子方法中隨機選擇一個走法a0。Coulum想象自己落子之后,棋盤狀態變成S1,然后繼續假設對手也和自己一樣二逼,對方也扔了一個篩子,隨便瞎走了一步,這時棋盤狀態變成S2,于是這兩個二逼青年一直扔骰子下棋,一路走到Sn,最后肯定也能分出一個勝負r,贏了就r記為1,輸了則為0,假設這第一次r=1。這樣Coulum便算是在心中模擬了完整的一盤圍棋。
Coulum心想,這樣隨機扔骰子也能贏?運氣不錯啊,那把剛才那個落子方法(S0,a0)記下來,分值提高一些:
新分數=初始分+r
我剛才從(S0, a0)開始模擬贏了一次,r=1,那么新分數=2,除了第一步,后面幾步運氣也不錯,那我把這些隨機出的局面所對應落子方法(Si,ai)的分數都設為2吧。然后Coulum開始做第二次模擬,這次扔骰子的時候Coulum對圍棋已經不是一無所知了,但也知道的不是太多,所以這次除(S0, a0)的分值是2之外,其他落子方法的分數還是1。再次選擇a0的概率要比其他方法高一點點。
那位假想中的二逼對手也用同樣的方法更新了自己的新分數,他會選擇一個a1作為應對。如法炮制,Coulum又和想象中的對手又下了一盤稍微不那么二逼的棋,結果他又贏了,Coulum于是繼續調整他的模擬路徑上相應的分數,把它們都 1。隨著想象中的棋局下得越來越多,那些看起來不錯的落子方案的分數就會越來越高,而這些落子方案越是有前途,就會被更多的選中進行推演,于是最有“前途”的落子方法就會“涌現”出來。
最后,Coulum在想象中下完10萬盤棋之后,選擇他推演過次數最多的那個方案落子,而這時,Coulum才真正下了第一步棋。
蒙特卡洛搜索樹華麗轉身為相當深刻的方法,可以看到它有兩個很有意思的特點:
1)沒有任何人工的feature,完全依靠規則本身,通過不斷想象自對弈來提高能力。這和深藍戰勝卡斯帕羅夫完全不同,深藍包含了很多人工設計的規則。MCTS靠的是一種類似遺傳算法的自我進化,讓靠譜的方法自我涌現出來。讓我想起了卡爾文在《大腦如何思維》中說的思維的達爾文主義[6]。
2)MCTS可以連續運行,在對手思考對策的同時自己也可以思考對策。Coulum下完第一步之后,完全不必要停下,可以繼續進行想象中的對弈,直到對手落子。Coulum隨后從對手落子之后的狀態開始計算,但是之前的想象中的對弈完全可以保留,因為對手的落子完全可能出現在之前想象中的對弈中,所以之前的計算是有用的。這就像人在進行對弈的時候,可以不斷思考,不會因為等待對手行動而中斷。這一點Coulum的程序非常像人,酷斃了。
但黃士杰很快意識到他老師的程序仍然有局限:初始策略太簡單。我們需要更高效地扔骰子。
如何更高效的扔骰子呢?
用P_human()來扔。
黃士杰改進了MCTS,一上來不再是二逼青年隨機擲骰子,而是先根據P_human的計算結果來得到a可能的概率分布,以這個概率來挑選下一步的動作。一次棋局下完之后,新分數按照如下方式更新:
新分數=調整后的初始分 通過模擬得到的贏棋概率
如果某一步被隨機到很多次,就應該主要依據模擬得到的概率而非P_human。
所以P_human的初始分會被打個折扣:
調整后的初始分= P_human/(被隨機到的次數+1)
這樣就既可以用P_human快速定位比較好的落子方案,又給了其他位置一定的概率。看起來很美,然后實際操作中卻發現:“然并卵”。因為,P_human()計算太慢了。
一次P_human()計算需要3ms,相對于原來隨機扔骰子不到1us,慢了3000倍。如果不能快速模擬對局,就找不到妙招,棋力就不能提高。所以,黃士杰訓練了一個簡化版的P_human_fast(),把神經網絡層數、輸入特征都減少,耗時下降到了2us,基本滿足了要求。先以P_human()來開局,走前面大概20多步,后面再使用P_human_fast()快速走到最后。兼顧了準確度和效率。
這樣便綜合了深度神經網絡和MCTS兩種方案,此時黃士杰的圍棋程序已經可以戰勝所有其他電腦,雖然距離人類職業選手仍有不小的差距,但他在2015年那篇論文的最后部分信心滿滿的表示:“我們圍棋軟件所使用的神經網絡和蒙特卡洛方法都可以隨著訓練集的增長和計算力的加強(比如增加CPU數)而同步增強,我們正前進在正確的道路上。”
看樣子,下一步的突破很快就將到來。同年2月,黃士杰在Deepmind的同事在頂級學術期刊nature上發表了“用神經網絡打游戲”的文章。這篇神作,為進一步提高MCTS的棋力,指明了前進的新方向:
左右互搏,自我進化紅白機很多人小時候都玩過,你能都打通嗎?黃士杰的同事通過“強化學習”方法訓練的程序在類似紅白機的游戲機上打通了200多個游戲,大多數得分都比人類還好。
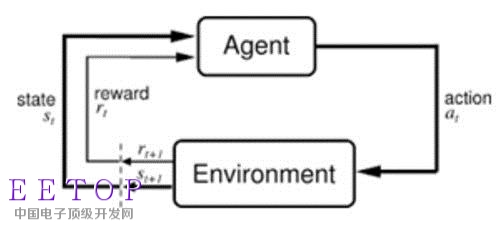
“強化學習”是一類機器學習方法,Agent通過和環境s的交互,選擇下一步的動作a,這個動作會影響環境s,給Agent一個reward,Agent然后繼續和環境交互。游戲結束的時候,Agent得到一個最后總分r。這時我們把之前的環境狀態s、動作a匹配起來就得到了一系列,設定目標為最后的總得分r,我們可以訓練一個神經網絡去擬合在狀態s下,做動作a的總得分。下一次玩游戲的時候,我們就可以根據當前狀態s,去選擇最后總得分最大的動作a。通過不斷玩游戲,我們對下總得分的估計就會越來越準確,游戲也玩兒得越來越好。
打磚塊游戲有一個秘訣:把球打到墻的后面去,球就會自己反彈得分。強化學習的程序在玩了600盤以后,學到這個秘訣:球快要把墻打穿的時候評價函數v的分值就會急劇上升。
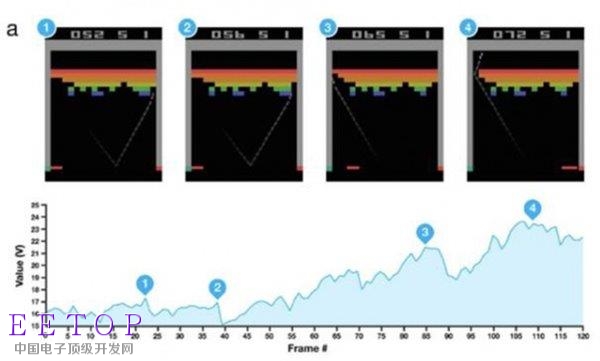
黃士杰考慮給圍棋也設計一個評價函數v(s),在P_human()想象自己開局走了20多步之后,不需要搜索到底,如果有一個v(s)可以直接判斷是否能贏,得到最后的結果r,這樣肯定能進一步增加MCTS的威力。
黃士杰已經有了國外的qq游戲大廳KGS上的對局,但是很遺憾這些對局數量不夠,不足以得到局面評價函數v。但是沒關系,我們還可以左右互搏自對弈創造新的對局。
機器學習的開山鼻祖Samuel早在1967年就用自對弈的方法來學習國際跳棋[7],而之前的蒙特卡洛搜索樹也是一個自對弈的過程。但是現在黃士杰不僅有一個從人類對弈中學習出的P_human這樣一個高起點,而且有一個神經網絡可以從對弈樣本中學習,有理由相信這次會有更好的結果。
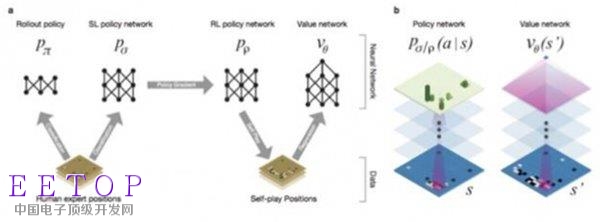
先用P_human和P_human對弈,比如1萬局,就得到了一萬個新棋譜,加入到訓練集當中,訓練出P_human_1。然后再讓P_human_1和P_human_1對局,得到另外一萬個新棋譜,這樣可以訓練出P_human_2,如此往復,可以得到P_human_n。P_human_n得到了最多的訓練,棋力理應比原來更強。我們給最后這個策略起一個新名字:P_human_plus。這時,再讓P_human_plus和P_human對局,在不用任何搜索的情況下勝率可達80%,不加任何搜索策略的P_human_plus和開源的MCTS相比也有85%的勝率。自對弈方法奏效了。
既然P_human_plus這么強,我們先代入到MCTS中試試,用P_human_plus來開局,剩下的用P_human_fast。可惜,這樣的方法棋力反而不如用P_human。黃士杰認為是因為P_human_plus走棋的路數太集中,而MCTS需要發散出更多的選擇才好。看來,P_human_plus練功還是太死板,還沒有進入無招勝有招的境界。
沒關系,黃士杰還有局面評價函數v(s)這一招,有了v(s),如果我可以一眼就看到“黑棋大勢已去”,我就不用MCTS在想象中自我對弈了。但考慮到P_human_plus的招法太過集中,黃士杰在訓練v( )的時候,開局還是先用P_human走L步,這樣有利于生成更多局面。黃士杰覺得局面還不夠多樣化,為了進一步擴大搜索空間,在L 1步的時候,干脆完全隨機擲一次骰子,記下這個狀態SL 1,然后后面再用P_human_plus來對弈,直到結束獲得結果r。如此不斷對弈,由于L也是一個隨機數,我們就得到了開局、中盤、官子不同階段的很多局面s,和這些局面對應的結果r。有了這些訓練樣本,還是使用神經網絡,把最后一層的目標改成回歸而非分類,黃士杰就可以得到一個v( )函數,輸出贏棋的概率。

v( )可以給出下一步落子在棋盤上任意位置之后,如果雙方都使用P_human_plus來走棋,我方贏棋的概率。如果訓練v()的時候全部都使用P_human不用P_human_plus呢?實驗表明基于P_human_plus訓練的v,比基于P_human訓練的v’,棋力更強。強化學習確實有效。
萬事俱備,只欠東風。準備好P_human(),MCTS,以及評價函數v(),黃士杰和小伙伴們繼續進擊,向著可以和人類專業選手過招的圍棋AI前進:
“阿爾法狗”
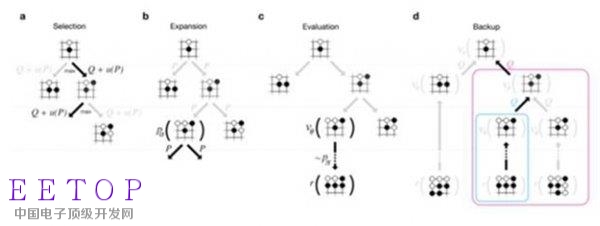
黃士杰準備在MCTS框架之上融合局面評估函數v()。這次還是用P_human作為初始分開局,每局選擇分數最高的方案落子,下到第L步之后,改用P_human_fast把剩下的棋局走完,同時調用v(SL),評估局面的獲勝概率。然后按照如下規則更新整個樹的分數:
新分數=調整后的初始分 0.5 *通過模擬得到的贏棋概率 0.5 *局面評估分
前兩項和原來一樣,如果待更新的節點就是葉子節點,那局面評估分就是v(SL)。如果是待更新的節點是上級節點,局面評估分是該節點所有葉子節點v()的平均值。
如果v()表示大局觀,“P_human_fast模擬對局”表示快速驗算,那么上面的方法就是大局觀和快速模擬驗算并重。如果你不服,非要做一個0.5: 0.5之外的權重,黃士杰團隊已經實驗了目前的程序對陣其他權重有95%的勝率。
以上,便是阿爾法狗的廬山真面目。
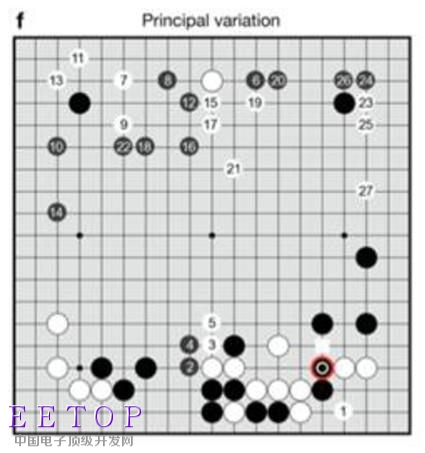
上圖演示了阿爾法狗和樊麾對弈時的計算過程,阿爾法狗執黑,紅圈是阿爾法狗實際落子的地方。1、2、3和后面的數字表示他想象中的之后雙方下一步落子的地方。白色方框是樊麾的實際落子。在復盤時,樊麾覺得位置1的走法更好。
深度學習、蒙特卡洛搜索樹,自我進化三招齊出,所有其他圍棋ai都毫無還手之力。99%的勝率不說,“阿爾法狗”還可以在讓四子的情況下以77%的勝率擊敗crazystone。“阿爾法狗”利用超過170個GPU,粗略估算超過800萬核并行計算,不僅有前期訓練過程中模仿人類,自我對弈不斷進化,還有實戰時的模擬對局可以實時進化,已經把現有方法發揮到了極限,是目前人工智能領域絕對的巔峰之作。
后記圍棋是NP-hard問題,如果用一個原子來存儲圍棋可能的狀態,把全宇宙的原子加起來都不夠儲存所有的狀態。于是我們把這樣的問題轉換為尋找一個函數P,當狀態為S時,計算最優的落子方案a = P(s)。我們看到,無論是“狂拽酷炫”的深度學習,還是“大智若愚”的MCTS,都是對P(s)的越來越精確的估計,但即使引入了“左右互搏”來強化學習,黃士杰和團隊仍然做了大量的細節工作。所以只有一步一個腳印,面對挑戰不斷拆解,用耐心與細心,還有辛勤的汗水,才能取得一點又一點的進步,而這些進步積累在一起,終于讓計算機達到并超過了人類職業選手的水平。
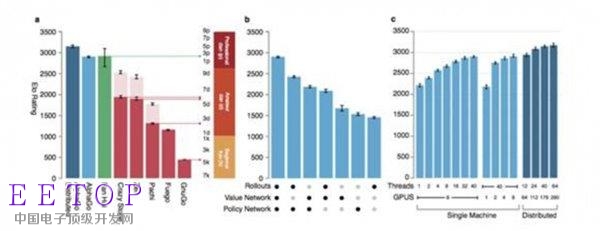
因為一盤棋走一步需要3ms(P_human_plus遍歷整個棋盤的時間),谷歌用大規模集群進行并行化計算,自我對弈3000萬盤棋生成訓練集只需要一天左右的時間[4],所以如果對弈更多棋局可以提高棋力的話,黃士杰他們早就做了。目前的方案可能已經達到了CNN網絡能力的極限。完整的阿爾法狗不僅需要生成訓練集,還要用訓練集來生成局面評估函數v(),而這還使用了兩周時間,一局比賽需要花掉4個小時,自我對局速度不夠快,這也許是阿爾法狗并沒有能夠完全使用強化學習,而僅僅是在整個過程的一小部分使用左右互搏的原因。左右互博用的還不夠多,這是一個遺憾。
如果存在一個“圍棋之神”,一個已經窮盡了所有的圍棋步法的“上帝”,那他每一步都是最優應對。一些頂尖棋手在接受采訪時表示[8],“圍棋之神”對戰人類選手可能還有讓4子的空間,也就是說,就算下贏了人類,計算機也還有很大進步的空間。
面對一個如此高難度的問題,計算機和人類都無法在有限時間內找到完全的規律(柯潔和李世乭比賽是一人有3小時時間思考,阿爾法狗今年3月和李世乭進行的比賽則是每人2小時)。計算機和人都是在對問題做抽象,然后搜索最佳策略。要下好圍棋所需要的能力已經接近人類智力的極限:要有大局觀、要懂得取舍、還要會精打細算,治理一個國家也不過如此。計算機可以學會圍棋,就能學會很多一樣難度的技能。在未來,也許圍棋、自動駕駛、同聲傳譯(「彩云小譯」已經開始公測,歡迎體驗)都會被一一攻克。甚至在數論、量子場論等領域,深度學習和搜索相結合,可能也會帶給我們更多驚喜,比如攻克“哥德巴赫猜想”。
那么,人工智能是否真的會很快登頂呢?
雖然在智力方面AI有希望登峰造極,但高智商只是人類眾多能力的一個方面。吳清源先生在方寸之間縱橫無敵,但仍然漂泊一生,被命運推著前進。早年他做段祺瑞的門客,棋盤上把段祺瑞打的落花流水,弄得下人都沒有早飯吃;后來東渡日本,三易國籍,留下許多遺憾。如果把“強人工智能”比作一個天才少年,雖然智商爆表,但其他方面還需要我們悉心加以引導。創造出“德才兼備,匡扶濟世”的人工智能,才是我輩真正應該努力實現的目標。