揭秘NVIDIA加速AI推理的密碼,1臺T4服務器完勝200臺CPU服務器
2019-07-15 09:30:39 智東西
用戶會看重AI產品的實時性、高準確度,而對于開發者來說,要考慮到的因素更多,不僅要滿足最終用戶的需求,還要考慮成本、能效等因素,因而,能滿足可編程性、低延遲、高準確度、高吞吐量、易部署的成套AI推理軟硬件組合成為開發者的心頭好。
而配備NVIDIA TensorRT超大規模推理平臺的GPU可以說是學術界和產業界最受歡迎的AI推理組合之一,它們可以帶來速度、準確度和快速響應能力的成倍提升。
去年NVIDIA最新發布的Tesla T4 GPU,因其專為推理而生的超高效率、超低功耗,能為開發者節省大筆預算,已成為業界首選AI推理神器。
本期的智能內參,我們對《NVIDIA AI推理平臺》白皮書進行解讀,看NVIDIA超大規模推理平臺如何協同頂尖AI推理加速器Tesla T4 GPU,為深度學習推理帶來吞吐量、速度等性能的倍增,并降低數據中心運營商的開發成本。如果想查閱此白皮書《NVIDIA AI 推理平臺》,可直接點擊http://nvidia.zhidx.com/content-9-1114-1.html下載。
NVIDIA GPU推理的應用價值
NVIDIA AI推理平臺就像一個隱形的推理助手,正通過互聯網巨頭的超大規模數據中心,為人們帶來各種新鮮且高效的AI體驗。
相比傳統的CPU服務器,GPU產品推理組合不僅能提升推理性能,還能更節省成本。
比如京東的視頻審核就使用NVIDIA AI平臺,將服務器數量減少了83%。
每天由第三方商家上傳到京東POP平臺的視頻數據不計其數,京東必須確保上傳的信息安全無害。
以前,要審核1000路的視頻流,京東必須在云端部署1000枚CPU,而使用NVIDIA AI推理平臺后,吞吐量提升20倍,速度比CPU快40倍,1臺配備4個Tesla P40的服務器能代替超過約50臺CPU服務器。
T4作為NVIDIA專為加速AI推理打造的GPU,在推理性能和能效比上一代產品P4 更勝一籌。
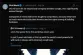
如圖,左邊是200臺占用四個機架的CPU服務器,支持語音、NLP和視頻應用,功耗達60千瓦。而相同的吞吐量和功能,一臺搭載16塊T4 GPU的服務器就足矣,不僅如此,這臺服務器還將功耗降為原來的1/30。
基于Turing架構的Tesla T4 GPU
NVIDIA Tesla T4 GPU是全球頂尖的通用加速器,適用于所有AI推理工作負載,不僅有小巧的外形規格和僅70瓦的超低功耗,而且效率比前一代Tesla P4超出兩倍以上。
它采用的Turing架構,除了繼承Volta架構為CUDA平臺引入的增強功能外,還新增獨立線程調度、統一內存尋址等許多適合推理的特性。
Turing GPU能提供比歷代GPU更出色的推理性能、通用性和高效率,這主要歸功于如下幾個創新特性:
1、新型流式多元處理器(SM)
新型SM具有Turing Tensor核心,基于Volta GV100架構上經過重大改進的SM而構建。
它能像Volta Tensor核心一樣,可提供FP16和FP32混合精度矩陣數學,還新增了INT8和INT4精度模式。
通過實現線程間細粒度同步與合作等功能,Turing SM使得GPU的性能和能效均遠高于上一代Pascal GPU,同時簡化了編程。
2、包含實驗特性,首用GDDR6
Turing是首款采用GDDR6顯存的GPU架構,最高可提供320GB/s的顯存帶寬,其存儲器接口電路也經過全面重新設計。
相比此前Pascal GPU使用的GDDR5X。Turing的GDDR6將速度提升40%,能效提升20%。
3、專用硬件轉碼引擎
視頻解碼正呈現爆炸式增長,在內容推薦、廣告植入分析、無人車感知等領域都獲得大規模應用。
T4憑借專業的硬件轉碼引擎,將解碼能力提升至上代GPU的兩倍,可以解碼多達38路全高清視頻流,而且能在不損失視頻畫質的前提下實現快速編碼或最低比特率編碼。
超大規模推理平臺TensorRT
僅有強大硬件還不夠,要搭配高適配度的軟件工具,才能最大化硬件算力的利用率,為開發者帶來更完整和優化的開發體驗。
NVIDIA加速推理的優勢也正是在軟硬件的結合上凸顯出來,既有專為深度學習定制的處理器,又具備軟件可編程特質,還能加速TensorFlow、PyTorch、MXNet等各種主流深度學習框架,為全球開發者生態系統提供支持。
面向深度學習推理,NVIDIA提供了一套完整的推理套餐——TensorRT超大規模推理平臺。
TensorRT包含T4推理加速器、TensorRT5高性能深度學習推理優化器和運行時、TensorRT推理服務三部分,支持深度學習推理應用程序的快速部署。
其中,TensorRT5將能夠優化并精確校準低精度網絡模型的準確度,最終將模型部署到超大規模數據中心、嵌入式或汽車產品平臺。
TensorRT推理服務是NVIDIA GPU Cloud免費提供的即用型容器,能提高GPU利用率,降低成本,還能簡化向GPU加速推理框架的轉換過程,更加節省時間。
配備TensorRT的GPU,推理性能最高可達CPU的50倍。
這得益于TensorRT對網絡結構的重構與優化。在精度方面,TensorRT提供INT8和FP16優化,通過降精度推理,在顯著減少應用程序的同時保持高準確度,滿足許多實時服務的需求。
另外,TensorRT還通過融合內核的節點,優化GPU顯存和帶寬的使用,并以更大限度減少顯存占用,以高效方式重復利用張量內存。
TensorRT和TensorFlow現已緊密集成,Matlab也已通過GPU編碼器實現與TensorRT的集成,能協助工程師和科學家在使用MATLAB時為Jetson、NVIDIA DRIVE和Tesla平臺自動生成高性能推理引擎。
TensorRT和Turing架構兩相結合,能提供高達CPU服務器45倍的吞吐量。
智東西認為,深度學習推理需要強大的計算平臺,來滿足云端與終端日益增長的AI處理需求。而一款強大的計算平臺不僅需要強大的芯片,還需要完整的生態系統。
通過軟硬件協同作用,NVIDIA TensorRT能在帶來高吞吐量和高能效的同時,實現推理神經網絡的快速優化、驗證和部署,既能降低開發門檻,又能節省服務器成本,使得工程師和科學家更好地專注于深度學習研究,推動各行業智能化升級。
免責聲明:本文由作者原創。文章內容系作者個人觀點,轉載目的在于傳遞更多信息,并不代表EETOP贊同其觀點和對其真實性負責。如涉及作品內容、版權和其它問題,請及時聯系我們,我們將在第一時間刪除!