深度學(xué)習(xí)方興未艾,但遷移學(xué)習(xí)才是真正的未來?
2017-06-12 18:43:52 滕云閣NIPS 2016:吳恩達(dá)表示,“在繼深度學(xué)習(xí)之后,遷移學(xué)習(xí)將引領(lǐng)下一波機(jī)器學(xué)習(xí)技術(shù)。

大牛吳恩達(dá)曾經(jīng)說過:做 AI 研究就像造宇宙飛船,除了充足的燃料之外,強(qiáng)勁的引擎也是必不可少的。假如燃料不足,則飛船就無法進(jìn)入預(yù)定軌道。而引擎不夠強(qiáng)勁,飛船甚至不能升空。類比于 AI,深度學(xué)習(xí)模型就好像引擎,海量的訓(xùn)練數(shù)據(jù)就好像燃料,這兩者對于 AI 而言同樣缺一不可。在訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)、學(xué)習(xí)輸入到輸出的精準(zhǔn)映射上,近年來大家做得越來越好。不管是針對圖像、語句,還是標(biāo)簽預(yù)測,有了大量做過標(biāo)記的樣例,都已不再是難題。
但是!今天的深度學(xué)習(xí)算法仍然欠缺的,是在新情況(不同于訓(xùn)練集的情況)上的泛化能力和訓(xùn)練模型所必須的海量數(shù)據(jù)難以獲取。
在深度學(xué)習(xí)熱火朝天,全民深度的時候說深度學(xué)習(xí)的壞話,而且對于那些沒有看完本文的標(biāo)題黨,會不會打我。但是我還是要鼓足勇氣說一下深度學(xué)習(xí)目前面臨的困難:
表達(dá)能力的限制。因為一個模型畢竟是一種現(xiàn)實的反映,等于是現(xiàn)實的鏡像,它能夠描述現(xiàn)實的能力越強(qiáng)就越準(zhǔn)確,而機(jī)器學(xué)習(xí)都是用變量來描述世界的,它的變量數(shù)是有限的,深度學(xué)習(xí)的深度也是有限的。另外它對數(shù)據(jù)的需求量隨著模型的增大而增大,但現(xiàn)實中有那么多高質(zhì)量數(shù)據(jù)的情況還不多。所以一方面是數(shù)據(jù)量,一方面是數(shù)據(jù)里面的變量、數(shù)據(jù)的復(fù)雜度,深度學(xué)習(xí)來描述數(shù)據(jù)的復(fù)雜度還不夠復(fù)雜。
缺乏反饋機(jī)制。目前深度學(xué)習(xí)對圖像識別、語音識別等問題來說是最好的,但是對其他的問題并不是最好的,特別是有延遲反饋的問題,例如機(jī)器人的行動,AlphaGo 下圍棋也不是深度學(xué)習(xí)包打所有的,它還有強(qiáng)化學(xué)習(xí)的一部分,反饋是直到最后那一步才知道你的輸贏。還有很多其他的學(xué)習(xí)任務(wù)都不一定是深度學(xué)習(xí)才能來完成的。
模型復(fù)雜度高。以下是一些當(dāng)前比較流行的機(jī)器學(xué)習(xí)模型和其所需的數(shù)據(jù)量,可以看到隨著模型復(fù)雜度的提高,其參數(shù)個數(shù)和所需的數(shù)據(jù)量也是驚人的。

OK,從上面的闡述,我們可以得出目前傳統(tǒng)的機(jī)器學(xué)習(xí)方法(包括深度學(xué)習(xí))三個待解決的關(guān)鍵問題:
隨著模型復(fù)雜度的提高,參數(shù)個數(shù)驚人。
在新情況下模型泛化能力有待提高。
訓(xùn)練模型的海量的標(biāo)記費時且昂貴。
表達(dá)能力有限且缺乏反饋機(jī)制。
遷移學(xué)習(xí)幫你搞定一切,讓你的模型小而輕,還能舉一反三!
"你永遠(yuǎn)不能理解一種語言——除非你至少理解兩種語言"。
任何一個學(xué)過第二語言的人,對英國作家杰弗里·威廉斯的這句話應(yīng)該都會"感同身受"。但為什么這樣說呢?其原因在于學(xué)習(xí)使用外語的過程會不可避免地加深一個人對其母語的理解。事實上,歌德也發(fā)現(xiàn)這一理念的強(qiáng)大威力,以至于他不由自主地做出了一個與之類似但更為極端的斷言:
"一個不會外語的人對其母語也一無所知"。
這種說法極為有趣,但令人驚訝的是恐怕更在于其實質(zhì)——對某一項技能或心理機(jī)能的學(xué)習(xí)和精進(jìn)能夠?qū)ζ渌寄芑蛐睦頇C(jī)能產(chǎn)生積極影響——這種效應(yīng)即為遷移學(xué)習(xí)。它不僅存在于人類智能,對機(jī)器智能同樣如此。如今,遷移學(xué)習(xí)已成為機(jī)器學(xué)習(xí)的基礎(chǔ)研究領(lǐng)域之一,且具有廣泛的實際應(yīng)用潛力。
一些人也許會很驚訝,計算機(jī)化的學(xué)習(xí)系統(tǒng)怎樣能展現(xiàn)出遷移學(xué)習(xí)的能力。Google 通過一項涉及兩套機(jī)器學(xué)習(xí)系統(tǒng)的實驗來思考了這個問題,為了簡單起見,我們將它們稱為機(jī)器 A 和機(jī)器 B。機(jī)器 A 使用全新的 DNN,機(jī)器 B 則使用已經(jīng)接受訓(xùn)練并能理解英語的 DNN。現(xiàn)在,假設(shè)我們用一組完全相同的普通話錄音及對應(yīng)文本來對機(jī)器 A 和 B 進(jìn)行訓(xùn)練,大家覺得結(jié)果會怎樣?令人稱奇的是,機(jī)器 B(曾接受英語訓(xùn)練的機(jī)器)展現(xiàn)出比機(jī)器 A 更好的普通話技能,因為它之前接受的英語訓(xùn)練將相關(guān)能力遷移到了普通話理解任務(wù)中。
不僅如此,這項實驗還有另一個令人更為驚嘆的結(jié)果:機(jī)器 B 不僅普通話能力更高,它的英語理解能力也會提高!看來威廉斯和歌德確實說對了一點——學(xué)習(xí)第二語言確實能夠加深對兩種語言的理解,即使機(jī)器也不例外。
其實這就是計算機(jī)化的遷移學(xué)習(xí)。然而在我們身邊,遷移學(xué)習(xí)的例子太多太多,一個精通吉他的人會比那些沒有音樂基礎(chǔ)的人能更快地學(xué)習(xí)鋼琴;一個會打乒乓球的人比沒有經(jīng)驗的人更容易接受網(wǎng)球;會騎自行車的人能更快學(xué)習(xí)騎電動車,等等,遷移學(xué)習(xí)就在你身邊。

在機(jī)器學(xué)習(xí)的經(jīng)典監(jiān)督學(xué)習(xí)場景中,如果我們要針對一些任務(wù)和域 A 訓(xùn)練一個模型,我們會假設(shè)被提供了針對同一個域和任務(wù)的標(biāo)簽數(shù)據(jù)(也就是說訓(xùn)練集和測試集的數(shù)據(jù)必須是iid的,即獨立同分布)。我們可以在下圖中清楚地看到這一點,其中我們的模型 A 在訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)中的域和任務(wù)都是一樣的(后面我會詳細(xì)地定義什么是任務(wù)(task),以及什么是域(domain))。
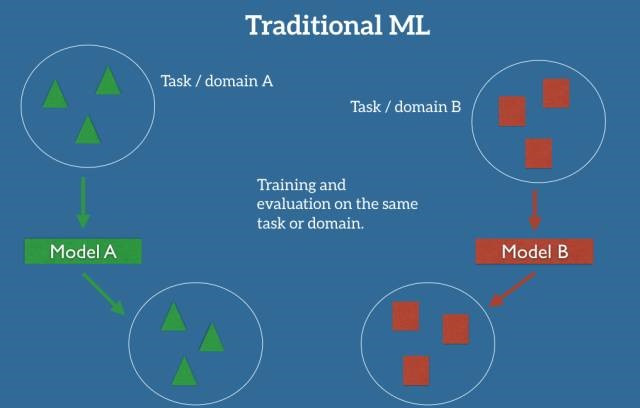
現(xiàn)在我們可以在這個數(shù)據(jù)集上訓(xùn)練一個模型 A,并期望它在同一個任務(wù)和域中的未知數(shù)據(jù)上表現(xiàn)良好。在另一種情況下,當(dāng)給定一些任務(wù)或域 B 的數(shù)據(jù)時,我們還需要可以用來訓(xùn)練模型 B 的有標(biāo)簽數(shù)據(jù),這些數(shù)據(jù)要屬于同一個任務(wù)和域,這樣我們才能預(yù)期能在這個數(shù)據(jù)集上表現(xiàn)良好。
但是,現(xiàn)實往往很殘酷,當(dāng)我們沒有足夠的來自于我們關(guān)心的任務(wù)或域的標(biāo)簽數(shù)據(jù)來訓(xùn)練可靠的模型時(新的標(biāo)簽數(shù)據(jù)很難獲取,或者很費時),傳統(tǒng)的監(jiān)督學(xué)習(xí)范式就支持不了了。
但傳統(tǒng)的監(jiān)督學(xué)習(xí)方法也會失靈——在缺乏某任務(wù)/領(lǐng)域標(biāo)記數(shù)據(jù)的情況下,它往往無法得出一個可靠的模型。舉個例子,如果我們想要訓(xùn)練出一個模型,對夜間的行人圖像進(jìn)行監(jiān)測,我們可以應(yīng)用一個相近領(lǐng)域的訓(xùn)練模型——白天的行人監(jiān)測。理論上這是可行的。但實際上,模型的表現(xiàn)效果經(jīng)常會大幅惡化,甚至崩潰。這很容易理解,模型從白天訓(xùn)練數(shù)據(jù)獲取了一些偏差,不知道怎么泛化到新場景。
如果我們想要執(zhí)行全新的任務(wù),比如監(jiān)測自行車騎手,重復(fù)使用原先的模型是行不通的。這里有一個很關(guān)鍵的原因:不同任務(wù)的數(shù)據(jù)標(biāo)簽不同。但是遷移學(xué)習(xí)就允許我們通過借用已經(jīng)存在的一些相關(guān)的任務(wù)或域的標(biāo)簽數(shù)據(jù)來處理這些場景,充分利用相近任務(wù)/領(lǐng)域的現(xiàn)有數(shù)據(jù)我們嘗試著把在源域中解決源任務(wù)時獲得的知識存儲下來,并將其應(yīng)用在我們感興趣的目標(biāo)域中的目標(biāo)任務(wù)上去,如下圖所示。
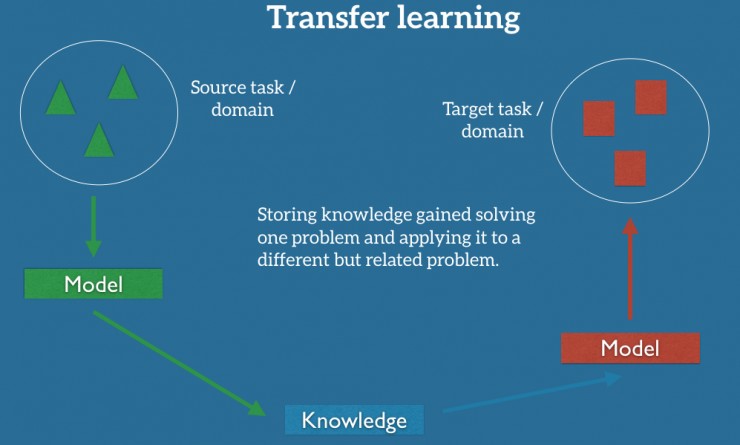
1.遷移學(xué)習(xí)的基本概念:域和任務(wù),源和目標(biāo)
一個域 D 由一個特征空間 X 和特征空間上的邊際概率分布 P(X) 組成,其中 X=x1,…, xn∈X。對于有很多詞袋表征(bag-of-words representation)的文檔分類,X 是所有文檔表征的空間,xi 是第 i 個單詞的二進(jìn)制特征,X 是一個特定的文檔。對我來說,通俗的理解就是域 D 就是特征的空間及分布。
給定一個域 D={X,P(X)},一個任務(wù) T 由一個標(biāo)簽空間 y 以及一個條件概率分布 P(Y|X)構(gòu)成,這個條件概率分布通常是從由特征——標(biāo)簽對 xi∈X,yi∈Y 組成的訓(xùn)練數(shù)據(jù)中學(xué)習(xí)得到。在我們的文檔分類的例子中,Y 是所有標(biāo)簽的集合(即真(True)或假(False)),yi 要么為真,要么為假。
源域 Ds,一個對應(yīng)的源任務(wù) Ts,還有目標(biāo)域 Dt,以及目標(biāo)任務(wù) Tt,這個就很好理解了,源就是對應(yīng)的我們的訓(xùn)練集,目標(biāo)就是對應(yīng)我們的測試集。
2.遷移學(xué)習(xí)的定義:
在 Ds≠Dt 和/或 Ts≠Tt 的情況下,讓我們在具備來源于 Ds 和 Ts 的信息時,學(xué)習(xí)得到目標(biāo)域 Dt 中的條件概率分布 P(Yt|Xt)。絕大多數(shù)情況下,假設(shè)可以獲得的有標(biāo)簽的目標(biāo)樣本是有限的,有標(biāo)簽的目標(biāo)樣本遠(yuǎn)少于源樣本。
3.遷移學(xué)習(xí)的分類:
XS≠XT,即源域和目標(biāo)域的特征空間不同,舉個例子,文檔是用兩種不同的語言寫的。在自然語言處理的背景下,這通常被稱為跨語言適應(yīng)(cross-lingual adaptation),我們將這種情況稱為異構(gòu)遷移學(xué)習(xí)(Heterogeneous TL)。
XS=XT,即源域和目標(biāo)域的特征空間相同,稱為同構(gòu)遷移學(xué)習(xí)(Homogenrous TL)
P(Xs)≠P(Xt),源域和目標(biāo)域的邊際概率分布不同,例如,兩個文檔有著不同的主題。這種情況通常被稱為域適應(yīng)(domain adaptation)。
P(Ys|Xs)≠P(Yt|Xt),源任務(wù)和目標(biāo)任務(wù)的條件概率分布不同,例如,兩個不同數(shù)據(jù)集的標(biāo)簽規(guī)則是不一樣的。
YS≠YT,兩個任務(wù)的標(biāo)簽空間不同,例如源域是二分類問題,目標(biāo)域是 4 分類問題,因為不同的任務(wù)擁有不同的標(biāo)簽空間,但是擁有相同的條件概率分布,這是極其罕見的。
借用一張之前自己做的幻燈片:

4.遷移學(xué)習(xí)的四種常見解決方法:

四種方法分別為:基于樣本的遷移學(xué)習(xí)、基于特征的遷移學(xué)習(xí)、基于參數(shù)/特征的遷移學(xué)習(xí)和基于關(guān)系的遷移學(xué)習(xí)。
(1) 基于樣本的遷移學(xué)習(xí)

第一種為樣本遷移,就是在數(shù)據(jù)集(源領(lǐng)域)中找到與目標(biāo)領(lǐng)域相似的數(shù)據(jù),把這個數(shù)據(jù)的權(quán)值進(jìn)行調(diào)整,使得新的數(shù)據(jù)與目標(biāo)領(lǐng)域的數(shù)據(jù)進(jìn)行匹配(將分布變成相同)。樣本遷移的特點是:1)需要對不同例子加權(quán);2)需要用數(shù)據(jù)進(jìn)行訓(xùn)練,上圖的例子就是找到源領(lǐng)域的例子 3,然后加重該樣本的權(quán)值,使得在預(yù)測目標(biāo)領(lǐng)域時的比重加大。
(2) 基于特征的遷移學(xué)習(xí)

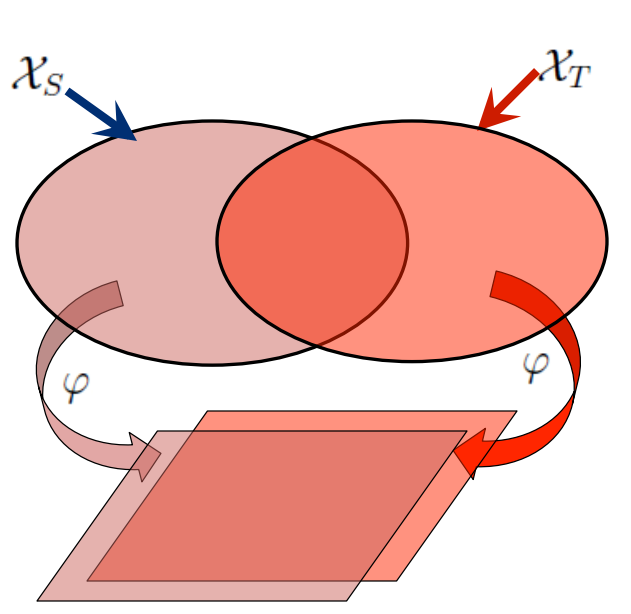
第二種為特征遷移,就是通過觀察源領(lǐng)域圖像與目標(biāo)域圖像之間的共同特征,然后利用觀察所得的共同特征在不同層級的特征間進(jìn)行自動遷移,上圖左側(cè)的例子就是找當(dāng)兩種狗在不同層級上的共同特征,然后進(jìn)行預(yù)測。
(3) 基于參數(shù)/模型的遷移學(xué)習(xí)
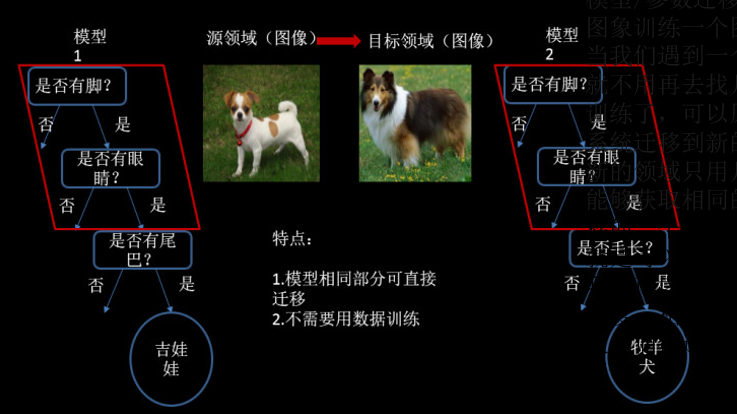
第三種為模型遷移,其原理時利用上千萬的狗狗圖象訓(xùn)練一個識別系統(tǒng),當(dāng)我們遇到一個新的狗狗圖象領(lǐng)域,就不用再去找?guī)浊f個圖象來訓(xùn)練了,可以原來的圖像識別系統(tǒng)遷移到新的領(lǐng)域,所以在新的領(lǐng)域只用幾萬張圖片同樣能夠獲取相同的效果。模型遷移的一個好處是我們可以區(qū)分,就是可以和深度學(xué)習(xí)結(jié)合起來,我們可以區(qū)分不同層次可遷移的度,相似度比較高的那些層次他們被遷移的可能性就大一些。
(4) 基于關(guān)系的遷移學(xué)習(xí)

這種關(guān)系的遷移,我研究的較少,定義說明是可以將兩個相關(guān)域之間的相關(guān)性知識建立一個映射,例如源域有皇帝、皇后,那么就可以對目標(biāo)域的男和女之間建立這種關(guān)系,一般用在社會網(wǎng)絡(luò),社交網(wǎng)絡(luò)之間的遷移上比較多。
遷移學(xué)習(xí)主要可以解決兩大類問題:小數(shù)據(jù)問題和個性化問題。
小數(shù)據(jù)問題:比方說我們新開一個網(wǎng)店,賣一種新的糕點,我們沒有任何的數(shù)據(jù),就無法建立模型對用戶進(jìn)行推薦。但用戶買一個東西會反應(yīng)到用戶可能還會買另外一個東西,所以如果知道用戶在另外一個領(lǐng)域,比方說賣飲料,已經(jīng)有了很多很多的數(shù)據(jù),利用這些數(shù)據(jù)建一個模型,結(jié)合用戶買飲料的習(xí)慣和買糕點的習(xí)慣的關(guān)聯(lián),我們就可以把飲料的推薦模型給成功地遷移到糕點的領(lǐng)域,這樣,在數(shù)據(jù)不多的情況下可以成功推薦一些用戶可能喜歡的糕點。這個例子就說明,我們有兩個領(lǐng)域,一個領(lǐng)域已經(jīng)有很多的數(shù)據(jù),能成功地建一個模型,有一個領(lǐng)域數(shù)據(jù)不多,但是和前面那個領(lǐng)域是關(guān)聯(lián)的,就可以把那個模型給遷移過來。
個性化問題:比如我們每個人都希望自己的手機(jī)能夠記住一些習(xí)慣,這樣不用每次都去設(shè)定它,我們怎么才能讓手機(jī)記住這一點呢?其實可以通過遷移學(xué)習(xí)把一個通用的用戶使用手機(jī)的模型遷移到個性化的數(shù)據(jù)上面。我想這種情況以后會越來越多。
1. 我到底是什么顏色?

大家一看這幅圖就知道,這里以此前網(wǎng)上流行的一個連衣裙圖片為例。如圖所示,如果你想通過深度學(xué)習(xí)判斷這條裙子到底是藍(lán)黑條紋還是白金條紋,那就必須收集大量的包含藍(lán)黑條紋或者白金條紋的裙子的圖像數(shù)據(jù)。參考上文提到的問題規(guī)模和參數(shù)規(guī)模之間的對應(yīng)關(guān)系,建立這樣一個精準(zhǔn)的圖像識別模型至少需要 140M 個參數(shù),1.2M 張相關(guān)的圖像訓(xùn)練數(shù)據(jù),這幾乎是一個不可能完成的任務(wù)。
現(xiàn)在引入遷移學(xué)習(xí),用如下公式可以得到在遷移學(xué)習(xí)中這個模型所需的參數(shù)個數(shù):
No. of parameters = [Size(inputs) 1] [Size(outputs) 1] = [2048 1][1 1]~ 4098parameters
可以看到,通過遷移學(xué)習(xí)的引入,針對同一個問題的參數(shù)個數(shù)從**140M 減少到了 4098**,減少了 10 的 5 次方個數(shù)量級!這樣的對參數(shù)和訓(xùn)練數(shù)據(jù)的消減程度是驚人的。
這里給大家介紹一個遷移學(xué)習(xí)的工具 NanoNets,它是一個簡單方便的基于云端實現(xiàn)的遷移學(xué)習(xí)工具,其內(nèi)部包含了一組已經(jīng)實現(xiàn)好的預(yù)訓(xùn)練模型,每個模型有數(shù)百萬個訓(xùn)練好的參數(shù)。用戶可以自己上傳或通過網(wǎng)絡(luò)搜索得到數(shù)據(jù),NanoNets 將自動根據(jù)待解問題選擇最佳的預(yù)訓(xùn)練模型,并根據(jù)該模型建立一個 NanoNets(納米網(wǎng)絡(luò)),并將之適配到用戶的數(shù)據(jù)。以上文提到的藍(lán)黑條紋還是白金條紋的連衣裙為例,用戶只需要選擇待分類的名稱,然后自己上傳或者網(wǎng)絡(luò)搜索訓(xùn)練數(shù)據(jù),之后 NanoNets 就會自動適配預(yù)訓(xùn)練模型,并生成用于測試的 web 頁面和用于進(jìn)一步開發(fā)的 API 接口。如下所示,圖中為系統(tǒng)根據(jù)一張連衣裙圖片給出的分析結(jié)果。具體使用方法詳見 NanoNets 官網(wǎng):http://nanonets.ai/ 。

2. Deepmind 的作品 progressive neural network(機(jī)器人)
Google 的 Deepmind 向來是大家關(guān)注的熱點,就在去年,其將三個小游戲 Pong, Labyrinth, Atari 通過將已學(xué)其一的游戲的 parameter 通過一個 lateral connection feed 到一個新游戲。外墻的可以看 youtub 的視頻:https://www.youtube.com/watch?v=aWAP_CWEtSI,與此同時,DeepMind 最新的成果 Progressive Neural Networks終于伸向真正的機(jī)器人了!

它做了什么事情呢?就是在仿真環(huán)境中訓(xùn)練一個機(jī)械臂移動,然后訓(xùn)練好之后,可以把知識遷移到真實的機(jī)械臂上,真實的機(jī)械臂稍加訓(xùn)練也可以做到和仿真一樣的效果!視頻在這:https://www.youtube.com/watch?v=YZz5Io_ipi8
3. 輿情分析

遷移學(xué)習(xí)也可應(yīng)用在輿情分析中,如用戶評價方面。以電子產(chǎn)品和視頻游戲留言為例,上圖中綠色為好評標(biāo)簽,而紅色為差評標(biāo)簽。我們可以從上圖左側(cè)的電子產(chǎn)品評價中找到特征,促使它在這個領(lǐng)域(電子產(chǎn)品評價)建立模型,然后利用模型把其遷移到視頻游戲中。這里可以看到,輿情也可以進(jìn)行大規(guī)模的遷移,而且在新的領(lǐng)域不需要標(biāo)簽。
4. 個性化對話

訓(xùn)練一個通用型的對話系統(tǒng),該系統(tǒng)可能是閑聊型,也可能是一個任務(wù)型的。但是,我們可以根據(jù)在特定領(lǐng)域的小數(shù)據(jù)修正它,使得這個對話系統(tǒng)適應(yīng)不同任務(wù)。比如,一個用戶想買咖啡,他并不想回答所有繁瑣的問題,例如是要大杯小杯,熱的冷的?
5. 基于遷移學(xué)習(xí)的推薦系統(tǒng)
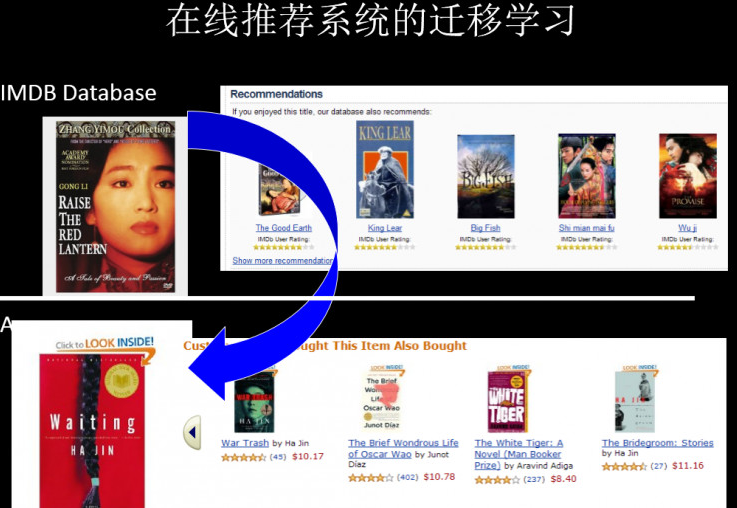
在線推薦系統(tǒng)中利用遷移學(xué)習(xí),可以在某個領(lǐng)域做好一個推薦系統(tǒng),然后應(yīng)用在稀疏的、新的垂直領(lǐng)域。(影像資料——>書籍資料)
6. 遷移學(xué)習(xí)在股票中的預(yù)測
香港科技大學(xué)楊強(qiáng)教授的學(xué)生就把遷移學(xué)習(xí)應(yīng)用到大家公認(rèn)的很難的領(lǐng)域中——預(yù)測股市走勢。下圖所示為 A 股里面的某個股票,用過去十年的數(shù)據(jù)訓(xùn)練該模型。首先,運用數(shù)據(jù)之間的連接,產(chǎn)生不同的狀態(tài),讓各個狀態(tài)之間能夠互相遷移。其次,不同狀態(tài)之間將發(fā)生變化,他們用了一個強(qiáng)化學(xué)習(xí)器模擬這種變化。最后,他們發(fā)現(xiàn)深度學(xué)習(xí)的隱含層里面會自動產(chǎn)生幾百個狀態(tài),基本就能夠?qū)@十年來的經(jīng)濟(jì)狀況做出一個很完善的總結(jié)。
楊強(qiáng)教授也表示,這個例子只是在金融領(lǐng)域的一個小小的試驗。不過,一旦我們對一個領(lǐng)域有了透徹的了解,并掌握更多的高質(zhì)量數(shù)據(jù),就可以將人工智能技術(shù)遷移到這個領(lǐng)域來,在應(yīng)用過程中對所遇到的問題作清晰的定義,最終能夠?qū)崿F(xiàn)通用型人工智能的目的。

遷移學(xué)習(xí)的應(yīng)用越來越廣泛,這里僅僅介紹了冰山一角,例如生物基因檢測、異常檢測、疾病預(yù)測、圖像識別等等。

當(dāng)今全世界都在推動遷移學(xué)習(xí),當(dāng)今 AAAI 中大概有 20 多篇遷移學(xué)習(xí)相關(guān)文章,而往年只有五六篇。與此同時,如吳恩達(dá)等深度學(xué)習(xí)代表人物也開始做遷移學(xué)習(xí)。正如吳恩達(dá)在 NIPS 2016 講座上畫了一副草圖,大致的意思如下圖所示:

有一點是毋庸置疑的:迄今為止,機(jī)器學(xué)習(xí)在業(yè)界的應(yīng)用和成功,主要由監(jiān)督學(xué)習(xí)推動。而這又是建立在深度學(xué)習(xí)的進(jìn)步、更強(qiáng)大的計算設(shè)施、做了標(biāo)記的大型數(shù)據(jù)集的基礎(chǔ)上。近年來,這一波公眾對 人工智能技術(shù)的關(guān)注、投資收購浪潮、機(jī)器學(xué)習(xí)在日常生活中的商業(yè)應(yīng)用,主要是由監(jiān)督學(xué)習(xí)來引領(lǐng)。但是,該圖在吳恩達(dá)眼中是推動機(jī)器學(xué)習(xí)取得商業(yè)化成績的主要驅(qū)動技術(shù),而且從中可以看出,吳恩達(dá)認(rèn)為下一步將是遷移學(xué)習(xí)的商業(yè)應(yīng)用大爆發(fā)。
最后,借鑒香港科技大學(xué)計算機(jī)與工程系主任,全球第一位華人 AAAI Fellow 楊強(qiáng)教授在 2016 年底騰訊暨 KDD China 大數(shù)據(jù)峰會上的一頁膠片來作為結(jié)束。
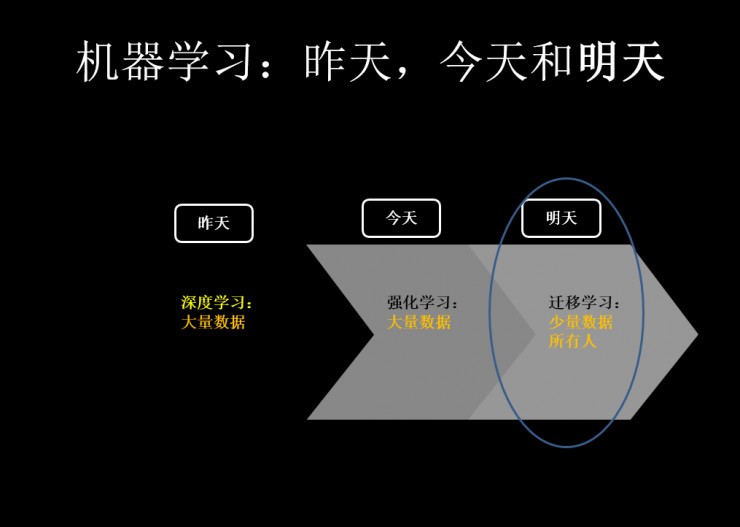
昨天我們在深度學(xué)習(xí)上有著很高成就。但我們發(fā)現(xiàn)深度學(xué)習(xí)在有即時反饋的領(lǐng)域和應(yīng)用方向有著一定的優(yōu)勢,但在其他領(lǐng)域則不行。打個比方:就像我在今天講個笑話,你第二天才能笑得出來,在今天要解決這種反饋的時延問題需要強(qiáng)化學(xué)習(xí)來做。而在明天,則有更多的地方需要遷移學(xué)習(xí):它會讓機(jī)器學(xué)習(xí)在這些非常珍貴的大數(shù)據(jù)和小數(shù)據(jù)上的能力全部釋放出來。做到舉一反三,融會貫通。
打個小廣告,由于自己本人希望在遷移學(xué)習(xí)方向上長期研究和學(xué)習(xí),因此申請了一個"遷移學(xué)習(xí)"的公眾號,每周會推送遷移學(xué)習(xí)的技術(shù)和學(xué)術(shù)干貨,同時對自己也是一種監(jiān)督,也希望在學(xué)習(xí)和分享的過程中遇到同路人,共同交流和進(jìn)步,請大家多多支持。

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章