從深藍到阿爾法狗 人機大戰(zhàn)20年進化了什么?
2016-03-12 16:41:18 it168俄羅斯國際象棋世界冠軍弗拉基米爾?克拉姆尼曾說過:“相信我,敗給電腦的痛苦感覺,相當(dāng)于敗給同行的兩倍。” 不想求李世石現(xiàn)在的心理陰影面積,因為很認同谷歌董事長施密特在賽前說過的一句話,“輸贏都是人類的勝利!因為正是人類的努力才讓人工智能有了現(xiàn)在的突破。”
雖然3:0的結(jié)果會讓很多期待李世石扳回一城的人黯然神傷,更有可能會讓“機器人威脅論”再次甚囂塵上。但是作為剛剛加入人機大戰(zhàn)俱樂部的新成員來說,AlphaGo交上的這份答卷可以說是完美。
從“算”到“學(xué)”,人工智能的進化
1997年,IBM的“深藍”戰(zhàn)勝了卡斯帕羅夫。在“深藍”設(shè)計者許峰雄看來,“深藍”主要依靠強大的計算能力窮舉所有路數(shù)來選擇最佳策略:“深藍”靠硬算可以預(yù)判12步,卡斯帕羅夫可以預(yù)判10步。

2006年,超級計算機浪潮天梭與中國象棋特級大師許銀川的較量最終以平局收場,然而許銀川在賽后感慨道:“整個比賽感覺很吃力,因為電腦一步可以算16個變化,而我只能憑借經(jīng)驗和理解與它對抗。而跟我下棋的對手不是真人,這讓我感覺很寂寞,我想我還是習(xí)慣和有表情交流的真人對弈。”

憑借超越特級大師對后續(xù)變化的計算能力,人工智能在此前的多場棋類人機大戰(zhàn)中占據(jù)上風(fēng)。但在圍棋,人工智能始終無法戰(zhàn)勝人類高手。為什么?

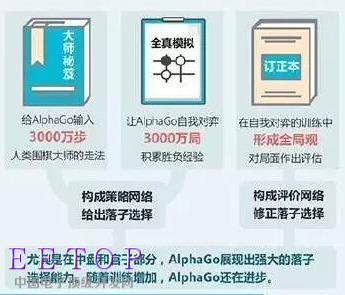
因此,要想在圍棋上戰(zhàn)勝人類頂尖棋手,必須先要讓電腦學(xué)會像人一樣思考。為此,谷歌為AlphaGo設(shè)計了兩個神經(jīng)網(wǎng)絡(luò):“決策網(wǎng)絡(luò)”(policy network)負責(zé)選擇下一步走法, “值網(wǎng)絡(luò)”(value network)則預(yù)測比賽勝利方,用人類圍棋高手的三千萬步圍棋走法訓(xùn)練神經(jīng)網(wǎng)絡(luò)。與此同時,AlphaGo也自行研究新戰(zhàn)略,在它的神經(jīng)網(wǎng)絡(luò)之間運行了數(shù)千局圍棋,利用反復(fù)試驗調(diào)整連接點,完成了大量研究工作。
而這種超強的學(xué)習(xí)能力,正是AlphaGo在戰(zhàn)勝職業(yè)二段樊麾5個月之后,就可以挑戰(zhàn)人類頂尖棋手并“戰(zhàn)而勝之”的關(guān)鍵所在。
如果說20年前的超級計算機還在依靠窮舉這種有些粗暴的手段才能戰(zhàn)勝人類,那么今天AlphaGo在與職業(yè)棋手的兩場對弈中,所表現(xiàn)出來智慧和超強學(xué)習(xí)能力則更加讓人驚嘆。
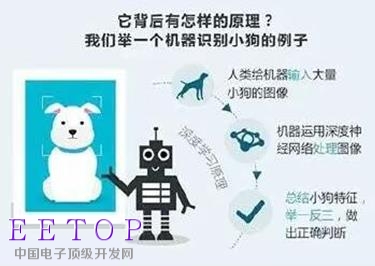
AlphaGo的連續(xù)勝利讓人更加確信,深度學(xué)習(xí)確實是當(dāng)下最有希望實現(xiàn)人工智能的技術(shù)。深度學(xué)習(xí)的概念源于人工神經(jīng)網(wǎng)絡(luò)的研究,其動機在于建立、模擬人腦進行分析學(xué)習(xí)的神經(jīng)網(wǎng)絡(luò),讓機器能夠像人一樣思考。
從本質(zhì)上來說,深度學(xué)習(xí)是一項“大數(shù)據(jù)工程”,需要通過建立有效的學(xué)習(xí)模型,讓機器從數(shù)以百萬計的圖像、聲音和文本數(shù)據(jù)中,自行總結(jié)出某種特定事物的特征,從而實現(xiàn)自主學(xué)習(xí)。
因此,實現(xiàn)機器像人一樣思考的一個關(guān)鍵前提是,需要有計算速度可以媲美人腦的高性能計算集群,來快速完成海量數(shù)據(jù)的“學(xué)習(xí)”。據(jù)說,AlphaGo的“單機版”性能至少是當(dāng)年“深藍”的1000倍。
與AlphaGo和李世石之間的最終勝負無關(guān),這場人機大戰(zhàn)的重要意義在于:有更多人愿意相信深度學(xué)習(xí)代表著人工智能未來之路,而這也勢必會讓本已“大紅”的深度學(xué)習(xí)變成“大紫”。

EETOP 官方微信

創(chuàng)芯大講堂 在線教育

半導(dǎo)體創(chuàng)芯網(wǎng) 快訊
相關(guān)文章