模擬芯片--人工智能未來發展的關鍵
2019-06-14 13:02:30 EETOPAI應用程序的核心是乘法累加函數(MAC)或點積運算。這需要兩個數字,將它們相乘,并將結果添加到累加器。數字從內存中提取并存儲到內存中。這些操作重復多次,占學習和推理所消耗的絕大部分時間和功率。
機器學習快速增長的一個原因是GPU的可用性。這些設備雖然最初用于圖形處理,但具有大量MAC和高速存儲器接口。它們可以比通用CPU更快地執行必要的計算。缺點是GPU傾向于使用浮點算法,這遠遠超出了AI算法的需要。但是,大多數研究都因此使用了浮點數。
業界正試圖通過遷移到更適合任務的定點數學或修改形式的浮點來削減浪費的時間和功耗。最初認為需要12位精度,但最新的發展正在推動8位計算。一些研究正在進行單比特處理,這表明它只會將準確度降低一點。
最新的谷歌TPU,一種針對機器學習的芯片,包含65,536個8位MAC塊,功耗非常大,芯片必須采用水冷卻。鑒于技術擴展正在放緩,我們不能指望增加集成到芯片上的MAC數量,除非進一步減少位數。
可以對傳統的馮·諾依曼架構進行改進。“微控制器性能的不斷提高以及圖書館和中間件的增加,以支持機器學習,有助于推理引擎遠離云端,更接近網絡邊緣,”營銷項目高級主管Rhonda Dirvin說道。為了武器汽車和物聯網業務。“通過這種遷移,可以更好地利用聲音識別,物體識別和電機健康振動監測等數據。隨著數據變得更有用,將收集更多數據。收集數據意味著通過混合信號IC實現我們的模擬世界并將其轉換為數字。新的信號處理功能已經添加到現代MCU中,允許在基于Arm的MCU上以數字方式完成信號處理,例如,不需要為許多應用提供額外的DSP。
這需要更好的模數轉換器(ADC)。“將模擬傳感器輸入轉換為數字信號需要ADC,”Microchip Technology混合信號和線性器件部高級技術人員工程師Youbok Lee說。“然后使用利用數字機器學習塊的AI算法處理該數字信號。隨著機器學習應用的普及,將需要更節能的自適應混合信號模擬前端設備。“
模擬幫助嗎?已經證明,AI功能可以使用數量級更少的功率執行,并且能夠解決比目前正在開發的AI系統復雜得多的問題。最好的例子是哺乳動物的大腦。即使是最耗電的人腦,也只消耗大約25W。TPU的功耗可能在200W到300W之間。雖然它包含64K處理單元,但人類大腦包含大約860億個處理單元。我們距離可能的地方有很多個數量級。雖然嘗試復制大腦可能不是理想的前進道路,但它確實表明,從長遠來看,將所有雞蛋放入數字籃子可能不是最有成效的。
業內有些人士同意。“由于其高功耗和外形尺寸,數字AI ASIC可能不是物聯網邊緣計算的理想解決方案,”Alchip的美國總經理Hiroyuki Nagashima說。“混合信號機器學習,受人類大腦的啟發,應該在未來的世界中發揮重要作用。我們是否能夠構建一臺能像人腦一樣感知,計算和學習的機器,并且只消耗幾瓦的功率?這是一個相當大的挑戰,但科學家們應該朝著這個方向努力。“
可以生產遵循數字架構但使用模擬電路的芯片。東芝已經生產出一種使用相域模擬技術執行MAC操作的芯片。它通過動態控制振蕩時間和頻率來使用振蕩器電路的相位域。他們聲稱,該技術可以集中處理傳統上由各個數字電路處理的乘法,加法和存儲器操作,使用具有相同面積的數字電路的八分之一功率。
在模擬和人工智能的背景下,往往會討論幾個問題。它們以精度和可變性為中心。模擬的一個問題是它們的精度有限,基本上由本底噪聲定義。數字電路沒有這樣的限制,但隨著對精度的需求降低,它正在成為模擬電路能夠提供的領域。
新的計算概念很重要。“我們的想法是,這些東西可以在一個時間步長內對完全連接的神經網絡層進行多次累積,”IBM研究院主要RSM的Geoffrey W. Burr解釋道。“否則,在一系列處理器上需要花費一百萬個時鐘,你可以在模擬域中使用數據位置的基礎物理。在時間和精力方面,它有足夠嚴重的有趣方面,它可能會在某個地方。“
這使可變性成為一個大問題。如果模擬電路用于推理,結果可能不是確定性的,并且更可能受到熱量,噪聲或其他外部因素的影響,而不是數字推理引擎。
但模擬可以在這個領域有一些顯著的優勢。當數字出錯時,它可能會出現災難性錯誤,而模擬能夠更好地容忍錯誤。“ 神經網絡很脆弱,”IBM研究中心主任Dario Gil在2018年設計自動化大會期間的一個小組中說道。 “我們一直在研究相變存儲器,我們已經制造出具有超過一百萬個PCM元件的芯片,并證明您可以實現深度學習培訓,與傳統GPU相比,具有相似的精度水平,可實現500倍的改進,”Gil說。“我們還有一個混合精密系統,所以它的一些可能是低精度但使用PCM矩陣陣列非常有效,但你也有一些高精度邏輯,能夠微調并獲得一些計算所需的任意精度。 ”
我們看一下不久前IBM關于模擬AI的一篇博客文章,可以了解一下模擬AI推理的實現原理,文章指出通過使用基于相變存儲器(Phase-Change Memory,簡稱PCM)的模擬芯片,機器學習可以加速一千倍。
人工智能或許能解決一些科學和行業最棘手的挑戰,但要實現人工智能,需要新一代的計算機系統。IBM在博客中的一篇文章中指出,通過使用基于相變存儲器(Phase-ChangeMemory,簡稱PCM)的模擬芯片,機器學習可以加速一千倍。
博客正文:
(來源:雷鋒網編譯)
相變存儲器基于硫化物玻璃材料,這種材料在施加合適的電流時會將其相從晶態變為非晶態并可恢復。每相具有不同的電阻水平,在相位改變之前是穩定的。兩個電阻構成二進制的1或0。
PCM是非易失性的,訪問延遲與DRAM水平相當,他們都是存儲級內存的代表。英特爾與美光聯合開發的3D XPoint技術就基于PCM。
為了實現AI真正的潛力,在紐約州立大學和創始合作伙伴成員的支持下,IBM正在建立一個研究中心,以開發新一代AI硬件,并期待擴展其納米技術的聯合研究工作。
IBM Research AI硬件中心合作伙伴涵蓋半導體全產業鏈上的公司,包括IBM制造和研究領域的戰略合作伙伴三星,互聯解決方案公司Mellanox Technologies,提供仿真和原型設計解決方案軟件平臺提供商Synopsys,半導體設備公司Applied Materials和Tokyo Electron Limited(TEL)。
還與紐約州奧爾巴尼的紐約州立大學理工學院主辦方合作,進行擴展的基礎設施支持和學術合作,并與鄰近的倫斯勒理工學院(RPI)計算創新中心(CCI)合作,開展人工智能和計算方面的學術合作。
新的處理硬件
IBM研究院的半導體和人工智能硬件副總裁Mukesh Khare表示,目前的機器學習限制可以通過使用新的處理硬件來打破,例如:
數字AI核心和近似計算
帶模擬內核的內存計算
采用優化材料的模擬核心
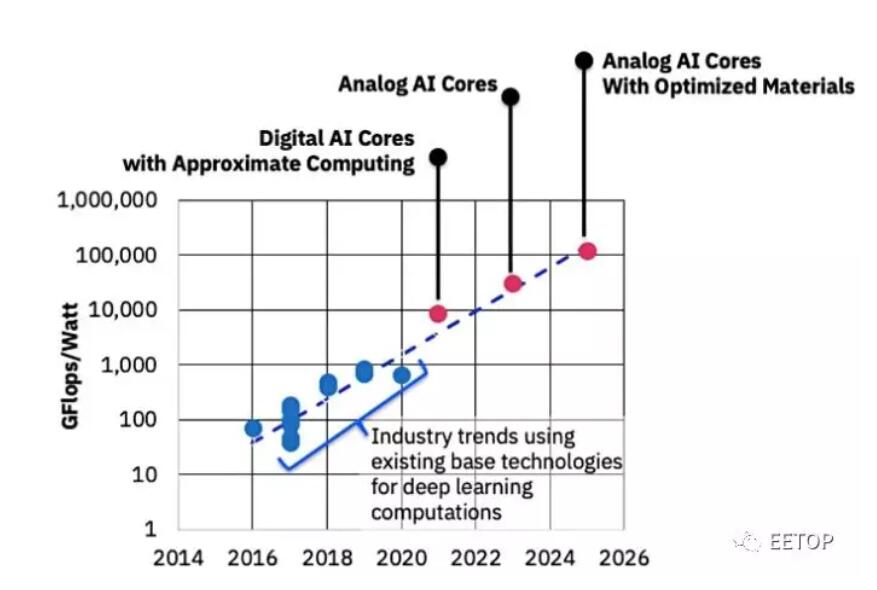
圖1:IBM Research AI硬件中心制定的一個路線圖,在未來十年內將AI計算性能效率提高1000倍,并提供數字AI核心和模擬AI核心管道。
Mukesh Khare提到將深度神經網絡(DNN)映射到模擬交叉點陣列(模擬AI核心)。它們在陣列交叉點處具有非易失性存儲器材料以存儲權重。
DNN計算中的數值被加權以提高訓練過程中決策的準確性。
這些可以直接用交叉點PCM陣列實現,無需主機服務器CPU干預,從而提供內存計算,無需數據搬移。與英特爾XPoint SSD或DIMM等數字陣列形成對比,這是一個模擬陣列。
PCM沿著非晶態和晶態之間的8級梯度記錄突觸權重。每個步驟的電導或電阻可以用電脈沖改變。這8級在DNN計算中提供8位精度。
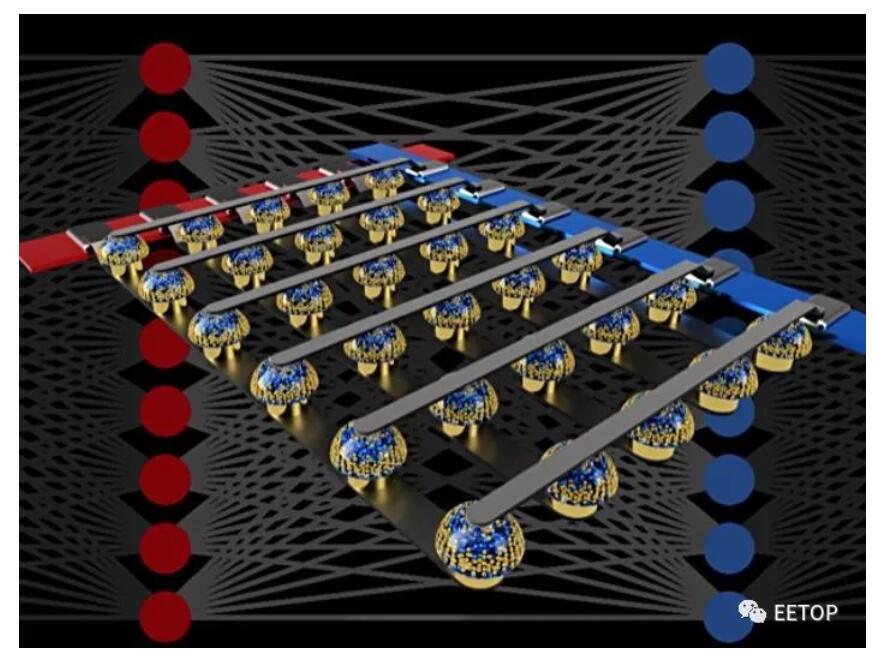
圖2:非易失性存儲器的交叉開關陣列可以通過在數據位置處執行計算來加速完全連接的神經網絡的訓練。
模擬存儲器芯片內部的計算
在IBM的研究報告中指出:
“模擬非易失性存儲器(NVM)可以有效地加速”反向傳播(Backpropagation)“算法,這是許多最新AI技術進步的核心。這些存儲器允許使用基礎物理學在這些算法中使用的“乘法-累加”運算在模擬域中,在權重數據的位置處并行化。
“與大規模電路相乘并將數字相加在一起不同,我們只需將一個小電流通過電阻器連接到一根導線上,然后將許多這樣的導線連接在一起,讓電流積聚起來。這讓我們可以同時執行許多計算,而不順序執行。也不是在數字存儲芯片和處理芯片之間的傳輸數字數據,我們可以在模擬存儲芯片內執行所有計算 。“
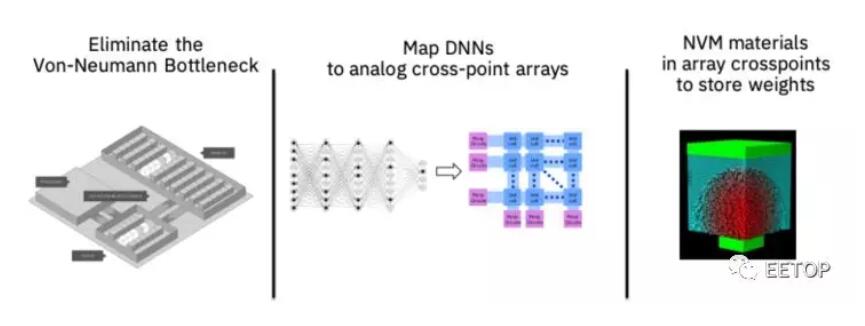
圖3:我們的模擬AI內核是性能效率內存計算方法的一部分,通過消除與內存之間的數據傳輸來突破所謂的馮·諾伊曼結構瓶頸,從而提高了性能。深度神經網絡被映射到模擬交叉點陣列,并且切換新的非易失性材料特性以在交叉點中存儲網絡參數。
免責聲明:本文由作者原創。文章內容系作者個人觀點,轉載目的在于傳遞更多信息,并不代表EETOP贊同其觀點和對其真實性負責。如涉及作品內容、版權和其它問題,請及時聯系我們,我們將在第一時間刪除!